順序統計量の標本最大値、最小値の分布
はじめに
統計学において「順序統計量(order statistics)」は、標本を小さい順に並べたときの各位置の値を指します。例えば、標本サイズ n の独立同分布標本 \(X_1, X_2, \dots, X_n\) を昇順に並べたものを
\[X_{(1)} \leq X_{(2)} \leq \cdots \leq X_{(n)}\]
と表します。このとき、\(X_{(1)}\) は標本最小値、\(X_{(n)}\) は標本最大値となります。標本最大値は、極値統計量の最も基本的な例であり、品質管理、信頼性工学、リスク管理など幅広い分野で重要な役割を果たします。また、統計検定1級でも「順序統計量の分布」や「最大値・最小値の分布」が頻出テーマであるため、理論的理解と具体的な計算練習が不可欠となります。本稿では、標本最大値、最小値の分布を数理的に導入し、代表的な分布での具体例を示したうえで、試験対策上の要点を整理していこうと思います。
標本最大値の分布の一般論
母集団分布の累積分布関数(CDF)を \(F(x) =P(X \le x)\)、確率密度関数(PDF)を f(x) とする。標本最大値を
\[M_n = X_{(n)} = \max\{X_1, \dots, X_n\} \equiv Y\]
とおく。
また、Yの累積分布関数(CDF)を G(y)、確率密度関数(PDF)を g(y) とする。
ここでG(y)は以下のように変形できます。
$$
\begin{eqnarray}
G(y) &=& P(Y \le y)\\
&=& P(\max\{X_1, \dots, X_n\} \le y)\\
&=& P(X_1 \le y, X_2 \le y, … ,X_n \le y,)\\
&=& P(X_1 \le y)P(X_2 \le y)\cdots P(X_n \le y) (\because X_1, \dots, X_n \text{はそれぞれ独立})\\
&=& F(y)F(y)\cdots F(y)\\
&=& {[F(y)]}^n
\end{eqnarray}
$$
よってyの確率密度関数g(y)はG(y)を微分すると得られるので、
$$
\begin{eqnarray}
g(y) &=& \frac{dG(y)}{dy}\\
&=& \frac{d }{dy}{[F(y)]}^n\\
&=& n{[F(y)]}^{n-1}F'(y)\\
&=& n{[F(y)]}^{n-1}f(y)
\end{eqnarray}
$$
標本最小値の分布の一般論
標本最小値についても最大値の時と同様に導出していきます。
母集団分布の累積分布関数(CDF)を \(F(x) =P(X \le x)\)、確率密度関数(PDF)を f(x) とする。標本最小値を
\[Z_n = Z_{(n)} = \min\{X_1, \dots, X_n\} \]
とおく。
また、Zの累積分布関数(CDF)を H(z)、確率密度関数(PDF)を h(z) とする。
ここで1-H(z)は以下のように変形できます。
$$
\begin{eqnarray}
1 – H(z) &=&1 – P(Z \le z)\\
&=& P(Z > z)\\
&=& P((\min\{X_1, \dots, X_n\}) > z)\\
&=& P(X_1 > z, X_2 > z, \cdots ,X_n > z)\\
&=& P(X_1 > z)P(X_2 > z)\cdots P(X_n > z) (\because X_1, \dots, X_n \text{はそれぞれ独立})\\
&=& [1 – P(X_1 \le z)][1 – P(X_2 \le z)]\cdots [1 – P(X_n \le z)]\\
&=& [1 – H(z)][1 – H(z)]\cdots[1 – H(z)]\\
&=& [1 – H(y)]^n
\end{eqnarray}
$$
\[\leftrightarrow H(z) = 1 – [1 – H(y)]^n\]
よってzの確率密度関数h(y)はH(z)を微分すると得られるので、
$$
\begin{eqnarray}
h(z) &=& \frac{dH(z)}{dz}\\
&=& \frac{d}{dz}{1 – [1 – H(y)]^n}\\
&=& -n{[1 – H(z)]}^{n-1}(-H'(z))\\
&=& n{[1 – H(z)]}^{n-1}h(z)
\end{eqnarray}
$$
具体例(標本最大値を例)
一様分布の場合
母集団が U(0,1) の場合、
\[F(x) = x \quad (0 \leq x \leq 1), \quad f(x) = 1.\]
したがって、標本最大値の分布は
\[F_{M_n}(x) = x^n, \quad f_{M_n}(x) = n x^{n-1}, \quad (0 \leq x \leq 1)\]
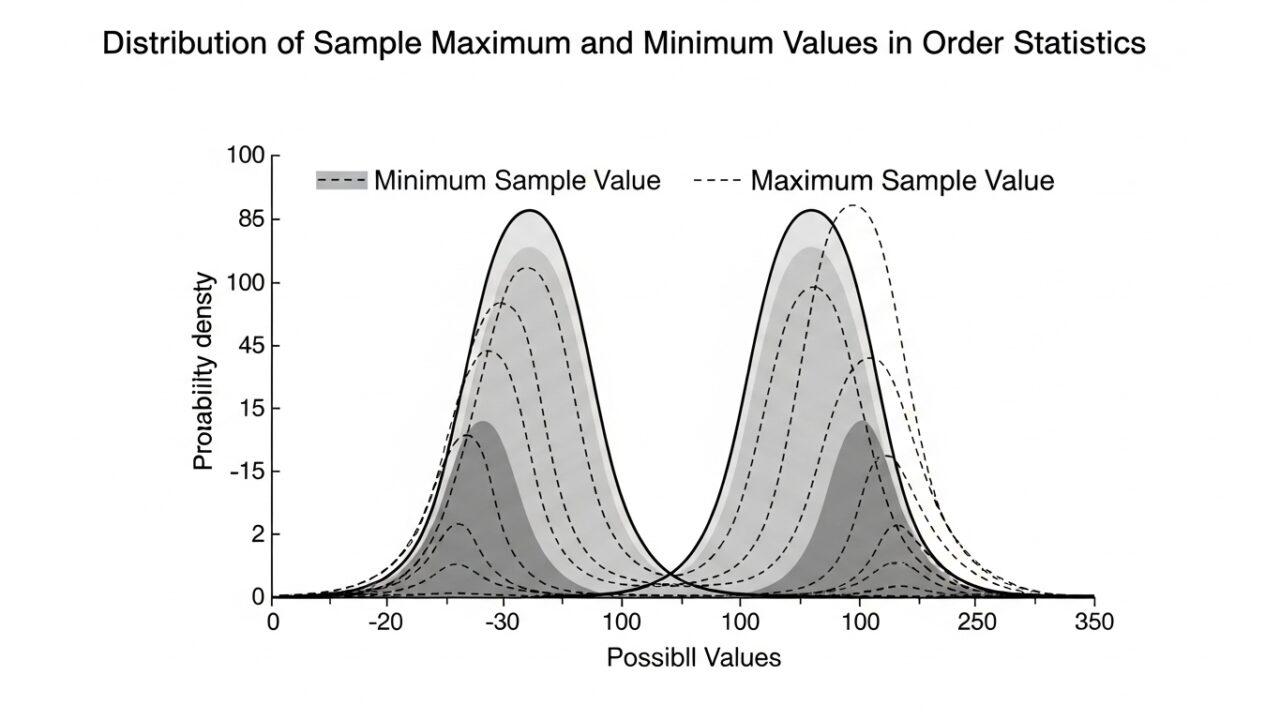
図解では下記のようなイメージです。
これは Beta分布 \(\mathrm{Beta}(n,1)\) に一致します。
期待値は
\[E[M_n] = \frac{n}{n+1}\]
この結果は統計検定1級でも頻出されているので、導出と結果は理解しておくことが大事です。
指数分布の場合
母集団が指数分布 \(\mathrm{Exp}(\lambda)\) の場合、
\[F(x) = 1 – e^{-\lambda x}, \quad f(x) = \lambda e^{-\lambda x}, \quad (x \geq 0)\]
標本最大値の分布は
\[F_{M_n}(x) = (1 – e^{-\lambda x})^n\]
\[f_{M_n}(x) = n (1 – e^{-\lambda x})^{n-1} \lambda e^{-\lambda x}\]
確率密度関数:\(f(t;\theta)=\theta exp[-\theta t]\)
期待値:\(E(T) = \frac{1}{\theta}\)
分散:\(Var(T) = \frac{1}{\theta^{2}}\)
累積分布関数:\(F(t;\theta)=\int^{t}_{0}\theta exp[-\theta t]dt=1-exp[-\theta t]\)
統計検定1級での出題傾向
- 一様分布の最大値・最小値の分布
→ Beta分布との対応を問う問題。 - 期待値や分散の計算
→ \(E[M_n]\) の導出を通じて積分計算力を確認。 - 漸近分布の理解
→ \(n \to \infty\) の極限での挙動を問う問題。 - 応用的設定
→ 信頼区間や推定量の一部として最大値を利用する問題。
特に「一様分布の最大値が Beta 分布に従う」という事実は頻出であり、計算の流れを理解することが重要です。
応用的視点
標本最大値は単なる理論的対象にとどまらず、実務的にも重要となります。
- 臨床試験:副作用の最大値や最大反応量を評価する際に利用。
- 品質管理:製品の強度試験で「最も弱い部品」や「最も強い部品」の分布を評価。
- リスク管理:金融や保険で「最大損失」や「最大リスク」を評価。
具体例
臨床試験で10人の被験者についてある薬の副作用の発現がどれくらいかを調べていく。
事象の発現率は指数分布に従うとして、副作用の単位時間あたりの発生数が0.5とすると、
\(\frac{1}{\lambda}=\frac{1}{2} \)より、\(\lambda= 2\)となる。
このとき、最後に副作用が発現した被験者が5時間~6時間の間に発生する確率は、
\[P(5 < M_n < 6) = 10(1 – e^{-\frac{6}{2}})^9\frac{1}{2}e^{-\frac{6}{2}}(6-5) \risingdotseq 0.1572\]
まとめ
標本最大値、最小値の分布は、順序統計量の中でも直感的でありながら深い理論的背景を持つ重要なテーマです。分布関数は母集団のCDFの累乗で表され、一様分布ではBeta分布に一致するなど計算可能な具体例も多く、統計検定1級でも頻出です。さらに、指数分布や正規分布では漸近的な性質が極値理論と結びつき、実務的にも品質管理やリスク評価に応用されます。試験対策としては、一様分布での具体計算と漸近的挙動の理解を軸に学習を進めることが効果的です。