モデル選択の基礎:AIC・BICを“情報量”として理解する— 過学習を避け、汎化性能を高めるための実務的ガイド —

- モデル選択がなぜ必要か(過学習と汎化性能のトレードオフ)
- AIC・BICとは何か ―「あてはまりの良さ」と「複雑さの罰則」で測る情報量規準
- AIC・BICの数式とその意味(最小の数式で直感的に)
- RでAIC・BICによるモデル選択を実装する方法(
step()・AIC()・BIC()) - AICとBICの使い分けと、実務での注意点
はじめに
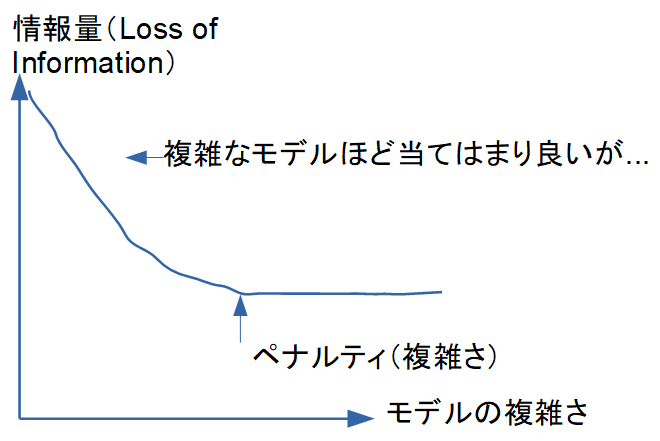
複数の統計モデルの候補から「どのモデルを採用すべきか」を判断する場面では、モデル選択の考え方が極めて重要になります。説明変数を増やせば増やすほど手元のデータへのあてはまりは良くなりますが、それは必ずしも「良いモデル」を意味しません。手元のデータに過剰に適合した結果、未知のデータに対する予測精度(汎化性能)がかえって低下する 過学習(overfitting) が起こるためです。
この「あてはまりの良さ」と「モデルの複雑さ」のバランスを、客観的な一つの数値で評価するための指標が 情報量規準(information criterion) です。なかでも AIC(赤池情報量規準)と BIC(ベイズ情報量規準)は、製薬・臨床研究の解析からマーケティング、機械学習まで、分野を問わず最も広く使われています。
本記事では、AIC・BICを「情報量」という観点から直感的に整理し、Rの組み込みデータセットを使った実装と結果の解釈、そして実務での使い分けまでを体系的に解説します。数理的な導出(KL情報量や事後確率との接続)をさらに深く知りたい方は、姉妹記事もあわせてご覧ください。
AIC・BICとは ― 「情報量」でモデルの良さを測る
AICとBICは、いずれも次の2つの要素のバランスでモデルを評価します。
- あてはまりの良さ:モデルがデータをどれだけうまく説明できているか(対数尤度で測る)
- モデルの複雑さへの罰則:パラメータ(説明変数)の数が多いほどペナルティを課す
直感的には「データをよく説明し、かつできるだけシンプルなモデルほど良い」という、いわゆるオッカムの剃刀の考え方を数値化したものと言えます。値が 小さいほど良いモデル と判断します。
AIC・BICの数式と意味
AICとBICは、それぞれ次の式で定義されます。
\[ \mathrm{AIC} = -2 \ln L + 2k \]
\[ \mathrm{BIC} = -2 \ln L + k \ln n \]
ここで \( L \) は最大化された尤度(モデルがデータに与える尤もらしさ)、\( k \) はモデルのパラメータ数、\( n \) はサンプルサイズを意味します。第1項 \( -2\ln L \) はあてはまりの悪さ(小さいほど良い)を表し、第2項がパラメータ数に対する罰則項です。
両者の違いは罰則項にあります。AICの罰則は \( 2k \) で一定ですが、BICの罰則は \( k \ln n \) であり、サンプルサイズ \( n \) が大きいほど罰則が強くなります。\( n \ge 8 \) であれば \( \ln n > 2 \) となるため、BICのほうがAICよりも複雑なモデルに対して厳しく、結果としてより単純なモデルを選びやすくなります。
AIC・BICの絶対値そのものには意味がありません。重要なのは 同一データに対する複数モデル間の相対比較 です。異なるデータセットやサンプルサイズが異なるモデル間で値を比較しても意味をなさない点に注意してください。
RでAIC・BICによるモデル選択を実装する
ここでは、Rの組み込みデータセット mtcars(32車種の燃費と諸元)を使い、燃費 mpg(1ガロンあたりの走行マイル)を予測する回帰モデルでAIC・BICによるモデル選択を実装します。
まず、すべての変数を投入した「フルモデル」と、変数を絞った候補モデルを用意し、それぞれのAIC・BICを計算します。
# データはRに組み込み済み(mtcars)
# 候補モデルを3つ用意する
m1 <- lm(mpg ~ wt, data = mtcars) # 重量のみ
m2 <- lm(mpg ~ wt + qsec + am, data = mtcars) # 重量+加速+変速機
m3 <- lm(mpg ~ ., data = mtcars) # 全変数(フルモデル)
# AIC・BICを比較
AIC(m1, m2, m3)
BIC(m1, m2, m3)
実行結果は次のとおりです。
> AIC(m1, m2, m3)
df AIC
m1 3 166.0294
m2 5 154.1194
m3 12 163.7098
> BIC(m1, m2, m3)
df BIC
m1 3 170.4266
m2 5 161.4480
m3 12 181.2987
AIC・BICのいずれでも、3変数モデル
m2(mpg ~ wt + qsec + am)が最小値(AIC=154.1/BIC=161.4)となり、最良と判断されます。注目すべきは全変数を投入したフルモデル m3 です。手元データへのあてはまり(尤度)は最も良いはずですが、AIC(163.7)・BIC(181.3)ともに m2 より悪化しています。これは余分な変数による複雑さの罰則が、あてはまりの改善を上回ったためで、まさに過学習が情報量規準によって検出されている状態です。候補が多い場合に、AICを基準として変数を自動的に増減させる手続きが ステップワイズ法 です。Rでは step() 関数で実行できます。
# フルモデルからAIC基準で変数を減らしていく(変数増減法)
best <- step(lm(mpg ~ ., data = mtcars), direction = "both", trace = 0)
summary(best)$call
AIC(best)
> summary(best)$call
lm(formula = mpg ~ wt + qsec + am, data = mtcars)
> AIC(best)
[1] 154.1194
step() はAICを最小化する変数の組み合わせを自動探索し、手動で比較した m2 と同じ mpg ~ wt + qsec + am を選択しました。AICが154.1で一致していることも確認できます。多数の候補変数がある実データでは、すべての組み合わせを手で試すのは現実的でないため、こうした自動選択が有用です。ただし後述のとおり、機械的な変数選択には注意も必要です。AICとBICの使い分け
AICとBICはしばしば異なるモデルを選びます。どちらを使うべきかは「モデル選択の目的」によって決まります。両者の性質を整理します。
| 観点 | AIC(赤池情報量規準) | BIC(ベイズ情報量規準) |
|---|---|---|
| 罰則項 | 2k(一定) | k ln n(n が大きいほど厳しい) |
| 選ばれるモデル | やや複雑(変数多め) | よりシンプル(変数少なめ) |
| 理論的な目的 | 予測精度(汎化誤差)の最小化 | 真のモデルの選択(一致性) |
| 向いている場面 | 予測・将来データへのあてはめを重視 | 要因の特定・説明・解釈を重視 |
ごく大まかには、予測の良さを最優先するならAIC、できるだけ簡潔で解釈しやすいモデルや真の構造の特定を重視するならBIC という使い分けが一つの目安になります。両者が同じモデルを選ぶ場合は、その選択への確信を強められます。一方で結果が分かれた場合は、解析の目的に立ち返って判断することが重要です。
実務でのポイントと注意点
- 比較は同一データ・同一応答変数で:欠測の扱いでサンプルサイズが変わるとAIC・BICは比較できません。
na.omit()等で行数をそろえてから比較します。 - ステップワイズ法を過信しない:自動変数選択は検定の多重性・選択後推論の問題を伴い、p値や信頼区間が楽観的になりがちです。臨床試験の主要解析では、変数は事前に計画して固定するのが原則です。
- 規準だけで決めない:AIC・BICはあくまで判断材料の一つです。臨床的・生物学的な妥当性、交絡の調整、解釈のしやすさも併せて総合的に判断します。
- 小標本ではAICc:サンプルサイズがパラメータ数に対して小さい場合(目安 n/k < 40)は、補正版の AICc を用いると過学習をより適切に抑えられます。
臨床試験や疫学研究では、共変量調整モデルや一般化線形モデル(ロジスティック回帰・Poisson回帰など)でモデル選択が問題になります。AIC・BICは線形回帰だけでなく、glm() で推定したモデルにも同じく AIC()・BIC() で適用できるため、応用範囲は非常に広いと言えます。
📚 この記事をより深く理解するための参考書籍
モデル選択・情報量規準をさらに深く学びたい方に、おすすめの書籍をご紹介します。




関連記事
- AIC/BICの“本質”を数理統計から理解する:KL情報量・事後確率との接続 ― 本記事の数理的背景(KL情報量・ベイズとの接続)を深掘りしています。
- 2値変数とロジスティック回帰:理論・実装・解釈 ―
glm()でのモデル選択にAIC・BICを応用する具体例として参考になります。 - 線形混合モデル (LMM)と一般化線形混合モデル(GLMM)の基礎 ― 混合モデルにおける情報量規準の使い方・注意点を学べます。
まとめ
本記事では、モデル選択の基礎としてAIC・BICを「あてはまりの良さ」と「複雑さへの罰則」のバランスを測る情報量規準として整理し、Rの mtcars を用いた実装(AIC()・BIC()・step())と結果の解釈、そしてAICとBICの使い分けを解説しました。
AIC・BICは、過学習を避けて汎化性能の高いモデルを選ぶための強力な道具ですが、値が小さいモデルを機械的に選べばよいというものではありません。比較の前提(同一データ・同一応答変数)を守り、予測重視か解釈重視かという目的に応じて規準を選び、最後は臨床的・生物学的な妥当性とあわせて総合的に判断することが、実務では極めて重要になります。情報量規準を正しく使いこなすことは、データから過不足のない説明を引き出すための大きな強みになります。