同時検出力を考慮したサンプルサイズ設計

はじめに
複数の主要評価項目(co-primary endpoints)を同時に満たす必要がある臨床試験では、同時検出力(joint power)を確保することが極めて重要になります。単一エンドポイントの検出力とは異なり、複数の統計量が同時に有意となる確率を扱うため、数学的にも計算的にも一段階複雑になります。製薬企業でサンプルサイズ設計を担当する方や、生物統計を学ぶ学生にとって必須のテーマであり、SAS・Rでの実装も実務上欠かせません。
以下では、数理的背景から実装例まで体系的に整理し、図解や数式を交えてわかりやすく解説します
同時検出力とは何か
複数の主要評価項目を設定する理由は、治療効果を多面的に評価するためです。例えば、疼痛スコアの改善と歩行距離の改善の両方が満たされて初めて臨床的に意味があるケースが典型的です。
このとき必要となるのが、次の確率です。
\[\mathrm{Power_{joint}}=P(\mathrm{endpoint\ 1\ が有意\ AND\ endpoint\ 2\ が有意})\]
単純に各エンドポイントの検出力を掛け合わせればよいわけではありません。理由は、統計量間に相関が存在するためです。
数理的背景:多変量正規分布による同時検出力
多くの検定統計量(t統計量、Z統計量)は大標本で正規分布に従います。
2つのエンドポイントの検定統計量を
\[Z_1,Z_2\]
とすると、一般に次の多変量正規分布に従います。
\[\left( \begin{matrix}Z_1\\ Z_2\end{matrix}\right) \sim N\left( \left( \begin{matrix}\mu _1\\ \mu _2\end{matrix}\right) ,\left( \begin{matrix}1&\rho \\ \rho &1\end{matrix}\right) \right)\]
ここで
- \(\mu _1,\mu _2\):効果量に応じた平均
- \(\rho\) :2つの統計量の相関係数
片側検定で有意水準\( \alpha\) の棄却域は
\[Z_i>z_{1-\alpha }\]]
したがって同時検出力は
\[\mathrm{Power_{joint}}=P(Z_1>z_{1-\alpha },Z_2>z_{1-\alpha })\]
これは2次元正規分布の確率として計算できます。
具体例:2つのエンドポイント
以下の設定を考えます。
| 項目 | 値 |
| 効果量(標準化) | \(\delta _1=0.4,\delta _2=0.5\) |
| 有意水準 | \(\alpha =0.025\)(片側) |
| 相関 | \(\rho =0.5\) |
| サンプルサイズ | \(n\)(後で探索) |
各統計量の平均は
\[mu _i=\delta _i\sqrt{n}\]
joint power を 80% にしたい場合、
\[P(Z_1>z_{0.975},Z_2>z_{0.975})=0.8\]
を満たす n を求めます。
R による joint power 計算
R では mvtnorm パッケージを使うと多変量正規分布の確率を直接計算できます。
library(mvtnorm)
joint_power <- function(n, delta1, delta2, rho, alpha = 0.025) {
mu <- c(delta1 * sqrt(n), delta2 * sqrt(n))
sigma <- matrix(c(1, rho, rho, 1), 2, 2)
lower <- qnorm(1 – alpha)
prob <- 1 – pmvnorm(
upper = c(lower, lower),
mean = mu,
sigma = sigma
)
return(prob)
}
# n = 100 の joint power
joint_power(100, 0.4, 0.5, 0.5)
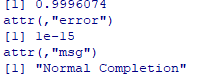
解釈:
- 検出力は99%以上であり、この joint power は ほぼ 100% に近いため、サンプルサイズが大きすぎる可能性があります。
- 実務では、必要検出力(例:80%)を満たす最小の n を探索するため、この結果は「n が十分大きい」ことを示すサインになります。
SAS による joint power 計算
SAS では PROC IML を用いて多変量正規分布の積分を行います。
proc iml;
start JointPower(n, delta1, delta2, rho, alpha);
mu = (delta1sqrt(n)) // (delta2sqrt(n));
Sigma = {1 rho, rho 1};
lower = j(2,1, quantile(“NORMAL”, 1-alpha));
/* 多変量正規分布の上側確率 */
prob = 1 – probmvnorm(lower, ., mu, Sigma);
return(prob);
finish;
do n = 50 to 300;
p = JointPower(n, 0.4, 0.5, 0.5, 0.025);
if p > 0.8 then do;
print n p;
leave;
end;
end;
quit;
相関の影響:joint power の感度分析
相関 \rho が joint power に与える影響は大きく、以下のような傾向があります。
| 相関 | joint power(例) |
| 0.0 | 低い(独立のため) |
| 0.3 | やや上昇 |
| 0.5 | さらに上昇 |
| 0.8 | 大幅に上昇 |
直感的には、2つのエンドポイントが同じ方向に動くほど「両方が有意になる確率」が高まるためです。
実務でのポイント
実際のサンプルサイズ設計では以下が重要になります。
● 相関の推定
- 過去試験データ
- パイロット試験
- 文献値
相関の不確実性が大きい場合は、感度分析が必須です。
● 多重性調整との関係
co-primary の場合は「両方有意」が要件であり、Bonferroni などの調整は不要です。
ただし hierarchical testing と組み合わせる場合は別途検討が必要です。
● 実装の自動化
R や SAS で joint power を計算する関数を作成し、
- 効果量
- 相関
- 有意水準
- 必要検出力
を入力してサンプルサイズを自動探索する仕組みを作ると、実務効率が大きく向上します。
まとめ
同時検出力を考慮したサンプルサイズ設計は、単一エンドポイントの場合よりも複雑になりますが、基盤となる考え方は多変量正規分布と相関構造の理解にあります。複数の検定統計量は大標本で正規分布に従い、相互に相関を持つため、同時に有意となる確率は多変量正規分布の上側確率として表されます。この確率を数値積分によって求めることで joint power を算出できます。R の mvtnorm や SAS の PROC IML を用いれば、この多変量積分を実務レベルで容易に計算でき、効果量・相関・有意水準を入力してサンプルサイズを探索する仕組みも構築しやすくなります。複数エンドポイントを設定する臨床試験が増える中で、joint power の理解と実装はますます重要性を増しており、今後は 3 つ以上のエンドポイントを扱う場合や、多重性調整と組み合わせた設計など、より高度な応用が求められる場面も広がっていくはずです。