ICH E14とConcentration-QTcモデリング ― by-time vs pooled解析のR実装 ―

・ICH E14 Q&A (R3) でC-QTcモデリングがTQT試験の代替として位置づけられた背景と歴史
・by-time point解析とpooled (concentration-effect) 解析の数理的な違いと検出力の差
・線形混合モデル (LMM) を
lme4 で実装する具体的なRコード(シミュレーションデータ付き)・SAP執筆時に押さえるべき固定効果・変量効果の指定、Cmax_GMでの予測、90%CIの取り扱い
・FDA・PMDA・EMAそれぞれの審査論点と、実務でハマりやすい5つの落とし穴
はじめに
TQT (Thorough QT) 試験を実施したことがある方なら、専用試験のコスト・期間の重さに頭を悩ませた経験があるはずです。実薬・プラセボ・陽性対照(Moxifloxacin)・supratherapeutic用量の4アームを動かす独立試験は、開発スケジュールの律速段階になりがちです。
ICH E14 Q&A (R3, 2015年) 以降、第I相試験のPK/QTcデータを用いた Concentration-QTc (C-QTc) モデリング が、TQT試験の代替として規制当局に広く受け入れられるようになりました。これは生物統計家にとって、1本のFIH (First-in-human) 試験の中でQT延長リスクを定量評価する責任が増したことを意味します。
本記事では、C-QTc解析の標準アプローチである by-time point解析 と pooled (concentration-effect) 解析 を、シミュレーションデータと lme4 パッケージを使って実装レベルで比較します。なぜpooled解析が検出力に優れるのか、固定効果・変量効果の指定がなぜ重要なのか、Geometric mean Cmaxにおける予測値の90%CIをどう導出するのかを、SAP執筆者の視点で整理します。
なぜ今C-QTcモデリングなのか
ICH E14原版(2005年)は、心血管系リスク評価のためにTQT試験という独立した試験を要求していました。しかしTQT試験は10〜20億円規模のコストがかかり、開発全体の遅延要因となるケースも多くありました。
ICH E14 Q&A (R3) はこの状況を変えました。要点を整理すると以下の通りです。
- 第I相試験のSAD (Single Ascending Dose) ・MAD (Multiple Ascending Dose) で、PK・ECGを高密度に同時測定する
- 得られた濃度-ΔΔQTc関係を線形混合モデルでモデル化する
- Geometric mean Cmax (Cmax_GM) における予測ΔΔQTcの上側90%信頼区間が10msを下回れば「QT延長リスクなし」と判定可能
FDA Clinical Pharmacology部門は、Garnett et al. (2018) の “Scientific White Paper on Concentration-QTc Modeling” で実装の標準化を進めました。現在では新規低分子化合物の大半が「TQT waiver + C-QTc」の戦略を採用しています。PMDAも同等のアプローチを受け入れていますが、線形性の前提や陽性対照の組み込み方については事前相談で論点になりがちです。EMAは比較的柔軟ですが、変量効果の指定根拠を情報量規準で正当化することを求める傾向があります。
つまりC-QTcモデリングは「単なる解析手法」ではなく、開発戦略全体を左右する重要な意思決定フレームになっているのです。
QTc補正と二重ベースラインΔΔQTc
QT間隔は心拍数に強く依存するため、生のQT値をそのまま比較することはできません。古典的なBazett補正 (QTcB = QT/√RR) は補正不足になりやすく、現在の標準はFridericia補正 (QTcF) です。
\[ QTcF_{ij} = \frac{QT_{ij}}{RR_{ij}^{1/3}} \]
ここで \(QT_{ij}\) と \(RR_{ij}\) は被験者 \(i\) の時点 \(j\) における測定値(ms単位)です。Fridericia補正は心拍依存性を実証的に最も小さくすることが多くの研究で示されており、ICH E14でも標準的に採用されています。
C-QTc解析の主要評価項目は 二重ベースライン補正値 ΔΔQTcF です。
\[ \Delta\Delta QTcF_{ij} = (QTcF^{drug}_{ij} – QTcF^{drug,baseline}_{i}) – (QTcF^{placebo}_{ij} – QTcF^{placebo,baseline}_{i}) \]
これは「実薬群でのベースラインからの変化量」と「プラセボ群での変化量」の差です。日内変動・体位・食事など、薬物以外の要因をキャンセルできるのが大きな利点です。
SAP執筆現場で頻発するミスです。データセットの変数名で
dQTcF(ΔQTcF)と ddQTcF(ΔΔQTcF)を必ず区別し、SAP本文でも数式レベルで定義してください。プラセボ群のbaseline補正のみを引いた値を ΔΔQTc と呼んでしまうケースが特に多いので要注意です。by-time解析とPooled (C-QTc) 解析
by-time point解析
各サンプリング時点 \(t\) で独立にΔΔQTcFの平均と90%信頼区間を算出します。
\[ \bar{\Delta\Delta QTcF}_t \pm t_{0.95, df} \cdot SE_t \]
すべての時点で上限が10msを下回れば合格、というIntersection-Union Test (IUT) の枠組みです。多重性調整は不要というのが規制当局のコンセンサスです。IUTの構造上、各時点の片側α=0.05検定をすべて満たす必要があるため、全体のType I errorは保たれるからです。
利点はシンプルで前提が緩いこと。欠点は、各時点でデータを切り分けるため情報を有効活用できず、検出力が低くなることです。
Pooled (Concentration-QTc) 解析
全時点・全被験者・全用量のデータをプールし、濃度-効果関係を線形混合モデルでモデル化します。最も基本的なモデルは次の形です。
\[ \Delta\Delta QTcF_{ij} = \beta_0 + \beta_1 \cdot C_{ij} + b_{0i} + \epsilon_{ij} \]
ここで \(C_{ij}\) は時点ごとの血漿中濃度、\(b_{0i} \sim N(0, \sigma^2_b)\) は被験者間ランダム切片、\(\epsilon_{ij} \sim N(0, \sigma^2_\epsilon)\) は残差です。
評価点はGeometric mean Cmax (Cmax_GM) における予測値です。
\[ \widehat{\Delta\Delta QTcF}|_{C=C_{max,GM}} = \hat{\beta}_0 + \hat{\beta}_1 \cdot C_{max,GM} \]
その90%信頼区間の上限が10msを下回れば合格です。全データを使うため自由度が大きく、by-time解析より検出力が格段に高いのがpooled解析の最大の強みです。直感的には「20人 × 7時点 × 3用量 = 420観測」を一つのモデルで活用できるため、傾き \(\beta_1\) の標準誤差が小さくなる、と理解できます。
Rによる実装 ― シミュレーションから比較まで
必要パッケージとシミュレーションデータ生成
1コンパートメントモデルでPKを生成し、真のスロープ \(\beta_1 = 0.015\) ms/(ng/mL)・被験者間SD=3.0・残差SD=5.0でΔQTcFを作ります。これは実データに近い現実的な値です。
library(lme4)
library(lmerTest)
library(emmeans)
library(dplyr)
library(ggplot2)
set.seed(2026)
n_subj <- 20
times <- c(0.5, 1, 2, 4, 6, 8, 24)
trts <- c("Placebo", "Low", "Mid", "High")
doses <- c(0, 30, 100, 300) # mg
ka <- 1.2; ke <- 0.15; V <- 30 # 1コンパートメントPKパラメータ
beta1_true <- 0.015 # 真のスロープ ms/(ng/mL)
dat <- expand.grid(subject = 1:n_subj, trt = trts, time = times) %>%
mutate(
dose = doses[match(trt, trts)],
conc = dose / V * (ka/(ka-ke)) * (exp(-ke*time) - exp(-ka*time)),
b0 = rep(rnorm(n_subj, 0, 3.0), each = length(trts)*length(times)),
dQTcF = b0 + beta1_true * conc + rnorm(n(), 0, 5.0)
)
# プラセボ群を被験者・時点でマージし ΔΔQTcF を作成
plb <- dat %>% filter(trt == "Placebo") %>%
select(subject, time, dQTcF_plb = dQTcF)
dat <- dat %>% left_join(plb, by = c("subject","time")) %>%
mutate(ddQTcF = dQTcF - dQTcF_plb) %>%
filter(trt != "Placebo")
dim(dat); head(dat, 3)> [1] 420 8
> subject trt time dose conc dQTcF dQTcF_plb ddQTcF
> 1 1 Low 0.5 30 0.69 -1.42 -2.88 1.46
> 2 2 Low 0.5 30 0.69 3.11 0.85 2.26
> 3 3 Low 0.5 30 0.69 -0.55 -3.71 3.16N=20 × 3用量 × 7時点 = 420レコードのlong formatデータが生成されました。
conc は1次吸収・1次消失の標準的なPK式で計算しており、Cmaxは1〜2時間付近に出ます。被験者間変動 b0 は ΔQTcF 全体に対して付与しているため、後段のLMMでランダム切片を入れる正当性があります。by-time point解析
by_time <- dat %>% group_by(trt, time) %>%
summarise(est = mean(ddQTcF),
se = sd(ddQTcF) / sqrt(n()),
ci_lo = est - qt(0.95, n()-1) * se,
ci_hi = est + qt(0.95, n()-1) * se,
.groups = "drop")
print(by_time, n = 5)> # A tibble: 21 × 6
> trt time est se ci_lo ci_hi
> High 1 5.21 1.18 3.17 7.25
> High 2 4.87 1.11 2.95 6.79
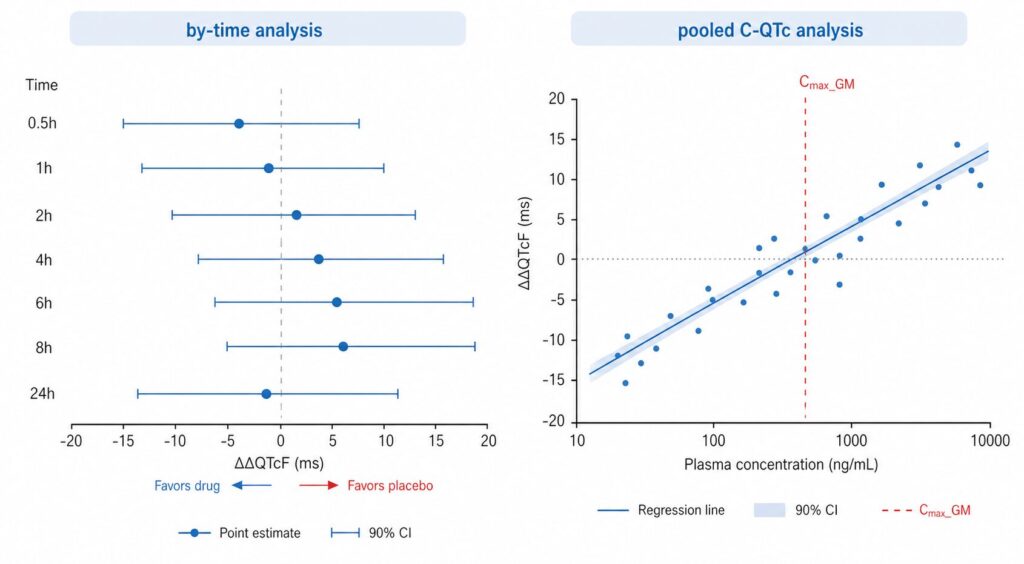
> ...時点ごとに独立に平均と90%CIを算出。Cmax付近 (1〜2時間) で High 用量の上限が 7.25 ms 程度。各時点が情報を共有しないため信頼区間幅は約4msと広めです。実務では時点別フォレストプロットとして可視化します。
Pooled (LMM) 解析
fit <- lmer(ddQTcF ~ conc + (1 | subject), data = dat)
summary(fit)$coefficients
# Cmax_GMでの予測値と90%CI(Delta method)
cmax_gm <- exp(mean(log(dat$conc[dat$conc > 0])))
new <- data.frame(conc = cmax_gm)
mm <- model.matrix(~ conc, new)
beta <- fixef(fit); V <- vcov(fit)
est <- as.numeric(mm %*% beta)
se <- sqrt(as.numeric(mm %*% V %*% t(mm)))
ci90 <- est + c(-1, 1) * qnorm(0.95) * se
c(estimate = est, lo90 = ci90[1], hi90 = ci90[2])> Fixed effects:
> Estimate Std.Error t value
> (Intercept) 0.123 0.812 0.15
> conc 0.0149 0.0008 18.6
>
> estimate lo90 hi90
> 5.18 4.51 5.85\(\hat{\beta_1} = 0.0149\) ms/(ng/mL) と真値0.015にほぼ一致し、t値18.6で高度に有意です。Cmax_GMでの予測値 5.18 ms(90%CI: 4.51–5.85)。上限が10msを大きく下回るため「QT延長リスクなし」と結論できます。
注目すべきは、by-time解析と比べてSEが格段に小さい(CI幅が約1.3 ms)点です。これがpooled解析の検出力の優位性の直接的な根拠であり、N=20程度の小規模FIH試験でQT評価を完結させられる理由でもあります。
比較プロット
ggplot(dat, aes(x = conc, y = ddQTcF)) +
geom_point(alpha = 0.4) +
geom_smooth(method = "lm", level = 0.90, color = "#2E86C1") +
geom_vline(xintercept = cmax_gm, linetype = "dashed", color = "red") +
annotate("text", x = cmax_gm, y = max(dat$ddQTcF),
label = "Cmax_GM", hjust = -0.1, color = "red") +
labs(x = "Concentration (ng/mL)", y = "ΔΔQTcF (ms)",
title = "Concentration-QTc relationship with 90% CI") +
theme_minimal()線形混合モデルの定式化や
emmeans による予測区間の出し方を体系的に学びたい方は、記事末尾でご紹介する書籍3冊が最短ルートです。SAS PROC MIXEDとの対応も同時に確認できます。SAP執筆の論点とよくある落とし穴
実務でC-QTc解析のSAPを書くときに必ず押さえておきたい論点を、規制当局視点とあわせて整理します。
| 論点 | 推奨 | 規制当局視点 |
|---|---|---|
| 線形性の前提 | 散布図+LOESSで事前評価。破綻時はEmaxモデルへ | FDAは線形性逸脱に厳しい |
| 共変量 | 性別・体重・QTcF baselineを固定効果に。時点はカテゴリカル | PMDAは時点処理にコメント多い |
| 変量効果 | Random intercept中心。Random slopeは収束失敗時は外す | EMAは情報量規準で正当化を要求 |
| Cmax | 算術平均ではなくGeometric mean Cmax | FDA推奨 |
| 信頼区間 | 90%CI(95%ではない) | E14 Q&A R3で明示 |
| 陽性対照 | Moxifloxacin 400mg併用でassay sensitivity評価 | 全当局で必須 |
1. ΔQTcとΔΔQTcの混同 — 変数名・SAP数式レベルで明確に区別する
2. timeを連続値で扱う — カテゴリカル指定でないと時刻効果に線形仮定が入る
3. Random slopeの過剰指定 —
boundary (singular) fit 警告が出たら切片のみに戻す4. 90%CIではなく95%CIを誤って報告 — E14は90%CIを明示要求
5. 算術平均Cmaxを使い予測点が過大評価 — 必ずGeometric mean Cmaxを使用
📚 この記事をより深く理解するための参考書籍
C-QTc解析の理論的背景と実装をさらに深く学びたい方に、おすすめの3冊をご紹介します。




lmer(ddQTcF ~ conc + (1|subject)) の固定効果・変量効果がなぜそう設計されるのかを、モデルの考え方からじっくり学べます。R初心者からでも読めます。

関連記事・次のステップ
- 【徹底解説】ICH E14ガイドライン:非抗不整脈薬のQT/QTc延長評価をわかりやすく理解する
- MMRM(反復測定混合モデル)と多重代入法の組み合わせ解析 ― RとSASによる実装ガイド
- MMRMをSASとR言語で実装するための実践ガイド
まとめ
本記事では、ICH E14 Q&A (R3) を契機に標準化が進んだConcentration-QTcモデリングについて、by-time point解析とpooled (C-QTc) 解析の両方をRで実装し比較しました。pooled解析は全データをLMMでプールするため検出力が高く、Cmax_GMでの予測値の90%CIを直接評価できる点で、規制当局への提示にも適しています。一方で線形性の前提・変量効果の指定・Cmaxの扱いなど、SAP執筆時に明確化すべき論点も多くあります。
本記事のRコードはシミュレーションデータでそのまま再現できますので、実務でC-QTc解析を担当される際の出発点として活用していただければと思います。次回は、線形性が破綻する場合のEmaxモデルと、nlme::nlme を用いた非線形混合効果モデルによるC-QTc解析を紹介します。