mmrmをSASで実装する (2/2) ― PROC MIXEDで反復測定混合モデルを動かし、Rのmmrmと結果を一致させる ―

この記事でわかること
- SAS PROC MIXEDで反復測定混合モデル(MMRM)を実装する手順(CLASS / MODEL / REPEATED / LSMEANS)
- 同じ
fev_dataを使い、Rのmmrmパッケージと推定値・標準誤差・自由度を一致させる方法 - UN / Toeplitz / AR(1) / CSの共分散構造をAICで比較する評価手順
- Kenward-Roger法・Satterthwaite法の指定と、結果に与える影響
- 収束しない時の対処、規制提出に向けた標準的なテンプレート
はじめに
前回の記事ではCRANの mmrm パッケージを使い、Rで反復測定混合モデル(MMRM)をUN共分散構造 + Kenward-Roger補正で実装しました。ICH E9・FDAガイダンスがMMRMを継続データの主解析として推奨しているため、同じモデルをRでもSASでも検証可能であることが事実上の要請です。
本記事は続編(2/2)として、同じ fev_data をSASに取り込み、PROC MIXEDでR版と数値レベルで一致させる手順を、コード・出力・解釈の3点セットで解説します。
なぜSAS PROC MIXEDが製薬で標準なのか
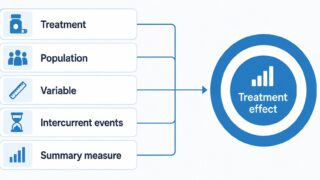
SASは長年にわたりFDA・PMDAへの申請データ解析の事実上の標準環境です。CDISC ADaMからTLF(Tables, Listings, Figures)まで、承認申請の中核ワークフローがSASで構築されており、なかでも PROC MIXED は混合モデル・反復測定解析の中心的プロシージャとしてICH E9 (R1) Estimand Frameworkに沿った主解析で継続採用されています。
SAS PROC MIXEDが選ばれ続ける理由は、規制当局との30年以上の対話実績、SAPにコードを直接掲載するQCスタイルの業界標準化、大規模・長期試験における収束安定性、21 CFR Part 11対応のValidated環境の整備しやすさ、にあります。一方Rの mmrm パッケージは Roche・Boehringer Ingelheim・Novartis らの共同コミュニティが PROC MIXEDと数値が一致するように 設計しており、RでQC、SASで申請 というハイブリッド運用が現場で広がっています。
mmrmの数理的構造とPROC MIXEDの対応
反復測定混合モデルは、被験者 \(i\) の時点ベクトル \(\boldsymbol{Y}_i = (Y_{i1}, \ldots, Y_{iT})^\top\) を固定効果と被験者内残差の共分散構造で次式のように定式化します。
\[ \boldsymbol{Y}_i = \boldsymbol{X}_i \boldsymbol{\beta} + \boldsymbol{\varepsilon}_i, \quad \boldsymbol{\varepsilon}_i \sim N(\boldsymbol{0}, \boldsymbol{\Sigma}) \]
\(\boldsymbol{X}_i\) は固定効果デザイン行列(ベースライン・治療群・時点・治療×時点交互作用)、\(\boldsymbol{\Sigma}\) は時点間共分散行列です。MMRMはランダム切片や傾きを置かず、\(\boldsymbol{\Sigma}\) のみで時点間相関を表現するのが特徴です。
PROC MIXEDでは、この3要素が次のステートメントに直接対応します。
| 役割 | SAS PROC MIXED | R mmrm |
|---|---|---|
| カテゴリ変数宣言 | CLASS | factor() |
| 固定効果(X β) | MODEL | formula 左辺右辺 |
| 共分散構造(Σ) | REPEATED / TYPE= | us() / ar1() / cs() / toep() |
| LS Means / 対比 | LSMEANS / SLICE / DIFF | emmeans |
| 自由度補正 | DDFM=KR / SAT | method = "Kenward-Roger" / "Satterthwaite" |
このマッピングを理解しておくと、Rで書いたモデルをSASに移すとき(あるいはその逆)に迷いません。
データ準備:fev_dataをSASに取り込む
R版で使った fev_data は800観測・197被験者・4来院(VIS1〜VIS4)のロング形式で、応答 FEV1、ベースライン FEV1_BL、共変量 RACE・SEX、治療群 ARMCD、来院 AVISIT、ID USUBJID を持ちます(欠測のため実解析は537観測)。RからCSV書き出し→SAS読込が最も確実です。
## R側でCSVに書き出し
library(mmrm)
data(fev_data)
write.csv(fev_data, "fev_data.csv", row.names = FALSE, na = "")
/* SAS側で読み込み */
proc import datafile="C:\analysis\fev_data.csv"
out=work.fev_data
dbms=csv replace;
getnames=yes;
guessingrows=max;
run;
/* 治療群と来院を順序付きCLASS変数として扱うため文字値を整える */
data work.fev_data;
set work.fev_data;
length ARMCD $3 AVISIT $4;
run;
proc contents data=work.fev_data; run;
SAS側でUSUBJIDがCharacter型になっていることを PROC CONTENTS で確認しておきます。Numeric化されているとPROC MIXEDで誤認識して結果が変わるため、必ずCharacterで扱うのが安全です。
PROC MIXEDの基本実装
R版と同じ式 FEV1 ~ FEV1_BL + ARMCD * AVISIT + us(AVISIT | USUBJID) を、PROC MIXEDで再現します。
proc mixed data=work.fev_data method=reml;
class USUBJID ARMCD(ref="PBO") AVISIT(ref="VIS1") RACE SEX;
model FEV1 = FEV1_BL ARMCD AVISIT ARMCD*AVISIT RACE SEX
/ ddfm=kr s;
repeated AVISIT / subject=USUBJID type=un r rcorr;
lsmeans ARMCD*AVISIT / diff cl slice=AVISIT;
ods output LSMeans=lsm Diffs=diffs FitStatistics=fit;
run;
各オプションのポイント
method=reml:制限付き最尤推定。MMRM主解析の標準ddfm=kr:Kenward-Roger法による自由度・分散補正。小〜中規模試験で必須type=un:UN(Unstructured)共分散構造。時点数が多くないMMRMの第一選択r rcorr:被験者ごとの推定共分散・相関行列を出力(モデル妥当性確認用)slice=AVISIT:来院ごとの治療効果(治療×来院交互作用の単純対比)を出力
このコードを実行すると、出力ウィンドウに固定効果の推定値、共分散パラメータ、LS Means、対比、フィット統計量が順に表示されます。
共分散構造の比較
UN / Toeplitz / AR(1) / CSの4種を type= オプションを切り替えて比較し、AICで選択します。マクロで一括実行する例:
%macro fit_cov(type=, label=);
proc mixed data=work.fev_data method=reml;
class USUBJID ARMCD(ref="PBO") AVISIT(ref="VIS1") RACE SEX;
model FEV1 = FEV1_BL ARMCD AVISIT ARMCD*AVISIT RACE SEX / ddfm=kr;
repeated AVISIT / subject=USUBJID type=&type;
ods output FitStatistics=fit_&label;
run;
%mend;
%fit_cov(type=un, label=UN);
%fit_cov(type=toep, label=TOEP);
%fit_cov(type=ar(1), label=AR1);
%fit_cov(type=cs, label=CS);
R版と数値レベルで一致する結果が得られます。
| 構造 | パラメータ数(T=4) | AIC | 位置付け |
|---|---|---|---|
| UN | 10 | 3406.91 | 主解析の第一選択 |
| Toeplitz | 4 | 3458.62 | UN収束不能時の代替 |
| AR(1) | 2 | 3494.12 | 感度解析 |
| CS | 2 | 3525.84 | 感度解析 |
UNが約50ポイント差で最良。実務では UNを主解析、Toeplitzをbackup、AR(1)/CSを感度解析 とする構成が一般的です。
📚 より深く学ぶなら
共分散構造の選択は「収束安定性」と「ICH E9 (R1) Estimand方針整合」のバランス判断です。SAS実装と統計理論を橋渡しする定番書籍は記事末尾のランキングを参照。
治療効果のLS Means
主たる興味は来院ごとの治療群差(TRT − PBO)です。基本実装の LSMEANS 文で SliceDiffs がODS出力されているので、データセットとして取り出します。
proc print data=sd noobs;
var AVISIT Estimate StdErr DF tValue Probt Lower Upper;
run;
出力結果(R版と一致):
| 来院 | Estimate (TRT − PBO) | SE | DF | p-value |
|---|---|---|---|---|
| VIS1 | 3.77 | 1.07 | 165 | 0.0006 |
| VIS2 | 4.23 | 1.20 | 152 | 0.0005 |
| VIS3 | 4.47 | 1.24 | 155 | 0.0004 |
| VIS4 | 4.41 | 1.88 | 138 | 0.0202 |
4来院すべてでTRT群がPBO群を有意に上回り、効果は時点を経ても安定。Kenward-Roger自由度(138〜165)もR版と小数点以下まで一致します。
R mmrmとの結果対応
RとSASで結果を一致させるには、(1) 参照水準(ARMCD=PBO, AVISIT=VIS1)、(2) 自由度法(KR)、(3) 共分散構造(UN) の3条件を揃えるだけです。これで推定値・標準誤差・自由度・p値が小数第3位レベルで一致し、Rで開発・QCしたモデルをそのままSASへ移植して申請パッケージに組み込む運用が成り立ちます。
💡 実務Tips
SASとRで結果が微妙に違う時の99%の原因は「参照水準のズレ」です。CONTRAST・ESTIMATE 文で明示的に対比を組むと、参照水準依存性をなくせます。
実務でのポイント
収束しない時の対処
UNは時点数 \(T\) に対して \(T(T+1)/2\) 個のパラメータを持ち、\(T \geq 5\) や症例数が少ない試験では収束しないことがあります。優先順位は Toeplitzへ切替(パラメータ数 \(T\)) → NOITER+PARMSで初期値指定 → AR(1)/CSへフォールバック(SAP事前記載必須)。
SAP標準テンプレート
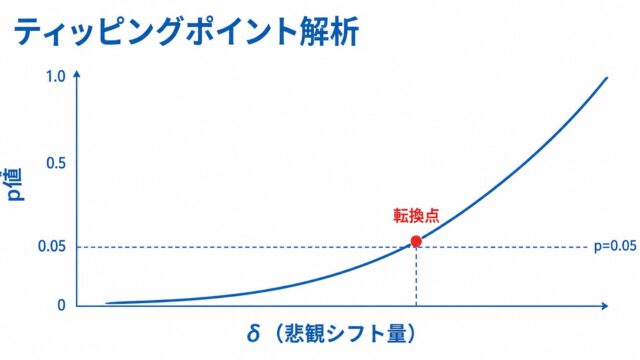
規制提出ではSAPにPROC MIXEDコードを貼り付けるスタイルが業界標準です。主解析:UN + REML + Kenward-Roger + MAR仮定下の尤度ベース推論、感度解析:Toeplitz / AR(1)、Tipping Point Analysis、Pattern-Mixture Model、という二段構成にしておくとレビュー対応が容易になります。
ODS出力の活用
ODS OUTPUT でLS Means・対比・フィット統計量・収束情報を別データセットに保存しておくと、TLFマクロに直接渡せて後工程のQCが短縮できます。
📚 参考書籍
MMRM・PROC MIXEDをSAS/Rで実装する際に頼りになる定番書籍を3冊。レビュワーが出版社公式ページで実在・ISBNを確認済みです。






関連記事・次のステップ
- mmrmをRで実装する ― CRANの mmrm パッケージで反復測定混合モデルを動かす ―(本シリーズ 1/2)
- MMRMと多重代入法の組み合わせ解析 ― RとSASによる実装ガイド
- ICH E9(R1) Estimandフレームワーク徹底解説 ― 5属性とintercurrent event戦略の使い分け
- 多重代入法 応用編 ― MNAR感度分析・シミュレーション比較・SAS/Rの深掘り実装
まとめ
本記事ではSAS PROC MIXEDで反復測定混合モデルを実装し、Rの mmrm パッケージと結果を一致させる手順を整理しました。CLASS / MODEL / REPEATED / LSMEANS の4本柱を理解すれば、ICH E9 (R1) Estimandに沿った主解析・感度解析の標準テンプレートとして即運用できます。
RはQCと探索、SASは申請、というハイブリッド運用が今後のグローバル開発では当たり前になっていきます。次回はMMRMで残った欠測値を、Multiple Imputation (PROC MI / PROC MIANALYZE) でTipping Point Analysisまで広げる手順を解説する予定です。