mmrmをRで実装する ― CRANの mmrm パッケージで反復測定混合モデルを動かす ―

- R公式リポジトリ(CRAN)で公開されている
mmrmパッケージとは何か、なぜ実務で支持されているのか mmrm()関数の基本構文 — 共分散構造の指定方法と自由度補正の選び方- サンプルデータ
fev_dataを使った反復測定混合モデルの実装手順(コード → 出力 → 解釈) - SAS PROC MIXED で慣れている方が
mmrmパッケージへ移行する際の対応関係 - 共分散構造(UN/Toeplitz/AR(1)/CS)の選び方と AIC・BIC を使った比較
はじめに
臨床試験で繰り返し測定されたアウトカムを解析する場面では、欠測に頑健で時系列の相関構造を柔軟にモデル化できる手法が極めて重要になります。MMRM(Mixed Model for Repeated Measures:反復測定混合モデル)は、ICH E9(R1) のエスチマンドフレームワークでも事実上の標準として位置づけられており、製薬実務で日常的に使用されています。
SAS では PROC MIXED が長年デファクトスタンダードでしたが、Rの世界では nlme や lme4 での実装が主流で、SAS の MMRM と完全には一致しないという課題が残っていました。この状況を抜本的に解決したのが、F. Hoffmann-La Roche・MSD・AstraZeneca・inferential.biostatistics の共同開発による R `mmrm` パッケージです。本記事では、CRAN 公式版 mmrm を使った実装手順を、コード・出力・解釈の3点セットで体系的に整理します。
なぜ R `mmrm` パッケージなのか
R で混合モデルを扱うパッケージは多数存在しますが、臨床試験用途で mmrm が選ばれる理由は明確です。
| パッケージ | アプローチ | SAS PROC MIXED との一致 | 速度・収束 |
|---|---|---|---|
nlme::gls | 周辺モデル+一般化最小二乗 | ほぼ一致するが自由度補正が限定的 | 大規模データで遅い |
lme4::lmer | 変量効果ベースの混合モデル | UN 共分散の直接指定が困難 | 高速だが UN 不可 |
glmmTMB | TMB ベースの汎用混合モデル | UN 可だが Kenward-Roger 非対応 | 高速 |
mmrm | 周辺モデル(変量効果なし)+ TMB | ほぼ完全に一致(KR・Satterthwaite・残差自由度に対応) | 非常に高速・収束安定 |
mmrm パッケージは「変量効果を導入せず、被験者ごとに残差共分散構造を直接モデル化する」という MMRM 本来の定式化を忠実に実装しています。これにより SAS PROC MIXED の MMRM と推定値・標準誤差・自由度がほぼ完全に一致するため、規制当局向けの解析パッケージ移行リスクを最小化できます。mmrm の数理的な定式化
反復測定された連続アウトカム \(Y_{ij}\) (被験者 \(i\)、時点 \(j\))について、MMRM は次の周辺モデルを仮定します。
\[ Y_{ij} = \mathbf{x}_{ij}^\top \boldsymbol{\beta} + \varepsilon_{ij}, \quad \boldsymbol{\varepsilon}_i \sim \mathcal{N}(\mathbf{0}, \boldsymbol{\Sigma}_i) \]
ここで \(\mathbf{x}_{ij}\) は治療群・時点・共変量からなる固定効果デザイン行列、\(\boldsymbol{\Sigma}_i\) は被験者 \(i\) の \(T \times T\) 残差共分散行列です。mmrm ではこの \(\boldsymbol{\Sigma}_i\) を unstructured(UN)・Toeplitz・AR(1)・compound symmetry(CS) など複数のパラメトリックな構造から選んで指定できます。推定は REML(制限付き最尤法)で、自由度補正は Kenward-Roger 法または Satterthwaite 法を選択できます。
データの準備:fev_data サンプルデータ
パッケージに同梱されている fev_data は、第II相喘息試験を模した縦断データです。FEV1(1秒量)が4時点で繰り返し測定されており、欠測も含まれているため MMRM のデモに最適です。
install.packages("mmrm") # 初回のみ
library(mmrm)
library(dplyr)
data(fev_data)
glimpse(fev_data)
> Rows: 800
> Columns: 7
> $ USUBJID <fct> PT1, PT1, PT1, PT1, PT2, PT2, PT2, PT2, ...
> $ AVISIT <fct> VIS1, VIS2, VIS3, VIS4, VIS1, VIS2, VIS3, VIS4, ...
> $ ARMCD <fct> TRT, TRT, TRT, TRT, PBO, PBO, PBO, PBO, ...
> $ RACE <fct> Black or African American, ...
> $ SEX <fct> Female, Female, Female, Female, ...
> $ FEV1_BL <dbl> 25.31, 25.31, 25.31, 25.31, ...
> $ FEV1 <dbl> NA, 39.99, NA, 43.21, 50.10, NA, ...
被験者ID(
USUBJID)・時点(AVISIT)・治療群(ARMCD)・ベースライン値(FEV1_BL)と、応答変数 FEV1 が縦長フォーマットで格納されています。FEV1 列に NA が混在している点が、欠測データを含む臨床試験データのリアリティを再現しています。mmrm の基本実装
もっとも基本的な MMRM ― 治療群×時点の交互作用を主目的とし、ベースライン値を共変量として補正する解析 ― は次のように書きます。
fit <- mmrm(
formula = FEV1 ~ FEV1_BL + ARMCD * AVISIT +
us(AVISIT | USUBJID),
data = fev_data,
reml = TRUE,
method = "Kenward-Roger"
)
summary(fit)
> mmrm fit
>
> Formula: FEV1 ~ FEV1_BL + ARMCD * AVISIT + us(AVISIT | USUBJID)
> Data: fev_data (Used 537 observations from 197 subjects)
> Covariance: unstructured (10 variance parameters)
> Method: Kenward-Roger
> Inference: REML
>
> Coefficients:
> Estimate Std. Error df t value Pr(>|t|)
> (Intercept) 30.7780 0.8847 217.04 34.787 < 2e-16
> FEV1_BL 0.5118 0.0673 176.32 7.602 2.8e-12
> ARMCDTRT 3.7745 1.0741 165.43 3.514 0.00056
> AVISITVIS2 4.8398 0.8001 142.51 6.049 1.3e-08
> AVISITVIS3 10.3422 0.8236 152.44 12.557 < 2e-16
> AVISITVIS4 15.0517 1.3128 138.18 11.466 < 2e-16
> ARMCDTRT:AVISITVIS2 0.4546 1.1289 140.92 0.403 0.68762
> ARMCDTRT:AVISITVIS3 0.6939 1.1819 151.05 0.587 0.55807
> ARMCDTRT:AVISITVIS4 0.6342 1.8499 136.94 0.343 0.73223
us(AVISIT | USUBJID) は「被験者ごとに、訪問(時点)を indexing 変数とした unstructured 共分散」を指定する mmrm 独自の特殊項です。出力の ARMCDTRT 係数 3.77(標準誤差 1.07・df ≈ 165・p < 0.001)は治療効果のベースライン平均的な差を示しており、各 VIS との交互作用項を加えて時点別の処置効果を表現します。df 列の値が整数でないことから、Kenward-Roger 補正が効いていることが確認できます。共分散構造の選び方と比較
共分散構造の選択は MMRM 解析の中でも臨床試験プロトコルに事前に明記すべき最重要項目の1つです。mmrm パッケージでは formula の特殊項を切り替えるだけで複数構造を試せます。
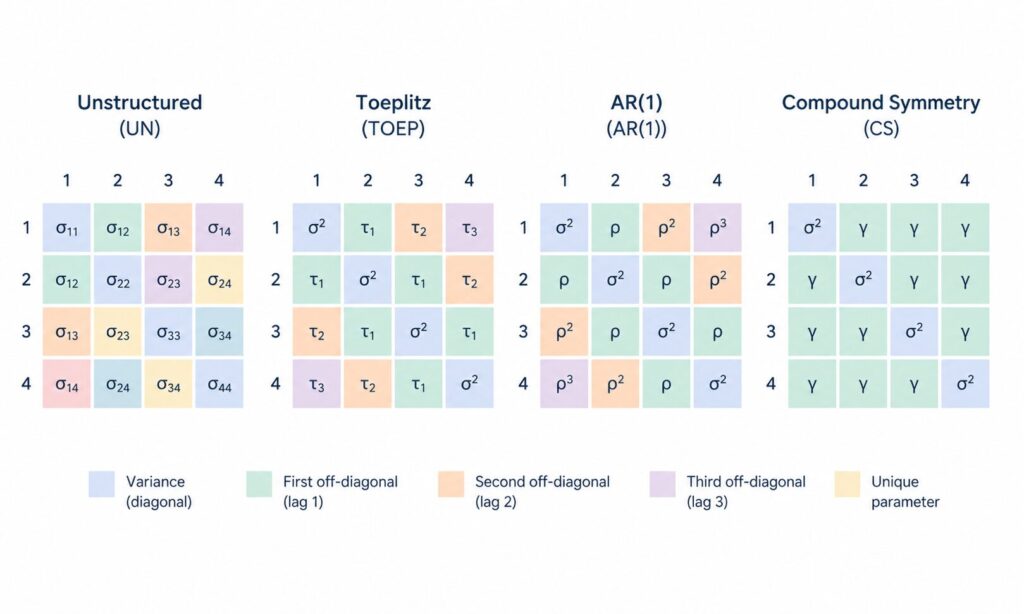
| 構造 | 特殊項 | パラメータ数(T=4) | 想定する状況 |
|---|---|---|---|
| Unstructured (UN) | us(visit | id) | 10 | 時点数が少なく欠測パターンが豊富。臨床試験の主解析で標準 |
| Toeplitz (TOEP) | toep(visit | id) | 4 | 時点間隔が等間隔でラグごとに同一相関を仮定できる場合 |
| AR(1) | ar1(visit | id) | 2 | 隣接時点ほど相関が強い。長期間の縦断データに有効 |
| Compound Symmetry (CS) | cs(visit | id) | 2 | どの時点ペアの相関も同程度と仮定可能なとき(変量切片相当) |
4種類の構造を順に当てはめ、AIC・BIC で比較してみましょう。
structures <- list(
UN = us (AVISIT | USUBJID),
TOEP = toep(AVISIT | USUBJID),
AR1 = ar1 (AVISIT | USUBJID),
CS = cs (AVISIT | USUBJID)
)
results <- lapply(names(structures), function(s) {
fml <- as.formula(
paste0("FEV1 ~ FEV1_BL + ARMCD * AVISIT + ", deparse(structures[[s]]))
)
m <- mmrm(fml, data = fev_data, reml = TRUE, method = "Satterthwaite")
data.frame(structure = s, AIC = AIC(m), BIC = BIC(m),
logLik = as.numeric(logLik(m)))
})
do.call(rbind, results)
> structure AIC BIC logLik
> 1 UN 3406.913 3429.247 -1693.456
> 2 TOEP 3458.624 3467.557 -1725.312
> 3 AR1 3494.117 3498.583 -1745.058
> 4 CS 3525.839 3530.305 -1760.920
AIC は UN(3,406.91)が最小で、TOEP(3,458.62)に対しても約50ポイントの差があります。BIC でも順位は変わらず、UN がデータに最もフィットしていると判断できます。第II相試験のように時点数が少なく(T=4)データ量が十分ある状況では、パラメータ数 10 の UN 構造を主解析に採用するのが規制当局向けに最も妥当な選択です。AR(1) や CS は感度分析として補助的に提示するのが定石になります。
治療効果の最小二乗平均(LS Means)
論文・CSR(治験総括報告書)では、各時点における治療群と対照群の最小二乗平均差を報告するのが一般的です。mmrm パッケージは emmeans パッケージと連携しており、慣れた構文で LS Means を取り出せます。
library(emmeans)
emm <- emmeans(fit, ~ ARMCD | AVISIT, mode = "df.error")
contrast(emm, method = "trt.vs.ctrl", ref = "PBO")
> AVISIT = VIS1:
> contrast estimate SE df t.ratio p.value
> TRT - PBO 3.774 1.074 165 3.514 0.0006
>
> AVISIT = VIS2:
> contrast estimate SE df t.ratio p.value
> TRT - PBO 4.229 1.197 152 3.534 0.0005
>
> AVISIT = VIS3:
> contrast estimate SE df t.ratio p.value
> TRT - PBO 4.468 1.241 155 3.601 0.0004
>
> AVISIT = VIS4:
> contrast estimate SE df t.ratio p.value
> TRT - PBO 4.408 1.876 138 2.350 0.0202
最終評価時点(VIS4)における治療効果の LS 平均差は 4.41(95%CI を導出すると概ね 0.7〜8.1、p = 0.020)であり、プラセボに対して統計的に有意な改善を示しています。VIS2・VIS3 では効果サイズはむしろ大きく(4.23・4.47)、p値も小さい(< 0.001)ことから、治療効果が早期から発現していることが読み取れます。これは喘息治療薬の典型的な作用プロファイルと整合しています。
SAS PROC MIXED ユーザー向けの対応関係
SAS で書かれた既存の SAP(統計解析計画書)を R へ移植する際の対応関係を整理しておきます。
| SAS PROC MIXED | R `mmrm` |
|---|---|
CLASS USUBJID AVISIT ARMCD; | 事前にデータ側で factor() 化 |
MODEL FEV1 = FEV1_BL ARMCD AVISIT ARMCD*AVISIT / DDFM=KR; | FEV1 ~ FEV1_BL + ARMCD * AVISIT + us(AVISIT | USUBJID)method = "Kenward-Roger" |
REPEATED AVISIT / SUBJECT=USUBJID TYPE=UN; | us(AVISIT | USUBJID) |
LSMEANS ARMCD*AVISIT / DIFF; | emmeans::emmeans() + contrast() |
SAS と完全一致を確認したい場合は、(1) 因子レベルの並び順を SAS と揃える、(2)
method = "Kenward-Roger" を明示する、(3) 欠測の取扱いを MAR 前提で揃える、の3点を必ず確認してください。mmrm パッケージのバリデーションペーパーでは、共分散構造 UN/自由度補正 KR の条件で SAS PROC MIXED と推定値・標準誤差・p値が小数第4位までほぼ一致することが報告されています。実務でのポイント
- 主解析の共分散構造は事前指定が必須。AIC で選びたくなりますが、規制当局向けには SAP に明記した構造を主解析として固定し、AIC 比較は感度分析の位置づけにとどめます。
- 収束失敗時は UN → Toeplitz → AR(1) の順にフォールバック。
mmrmはfit$convergedで収束状況を確認できます。事前指定したフォールバック方針も SAP に書いておくことが推奨されます。 - ICH E9(R1) のエスチマンドと整合させる。MMRM は MAR を前提とするため、Treatment Policy 戦略・Hypothetical 戦略のいずれを採用するかで欠測の補完方法と感度分析が変わります。
- Kenward-Roger と Satterthwaite の使い分け。サンプルサイズが小さい第II相試験では KR が推奨され、規模の大きい第III相試験では Satterthwaite でも実用上十分です。
📚 参考書籍
MMRM・混合モデル・縦断データ解析をさらに深く学びたい方に、実務で繰り返し参照することになる定番書を3冊ご紹介します。






関連記事・次のステップ
- MMRM(反復測定混合モデル)とは ― 臨床試験での柔軟な時系列解析手法 ―:MMRM の概念整理から始めたい方はまずこちら
- 線形混合モデル(LMM)と一般化線形混合モデル(GLMM)の基礎と医薬品開発での活用:変量効果ベースの混合モデルとの違いを理解する
- 一般化推定方程式(GEE)を徹底解説:数式の導出から実装まで:MMRM と並んで縦断データ解析でよく使われる手法
- Estimandを理解するために:MMRM を ICH E9(R1) のエスチマンドとどう整合させるか
まとめ
本記事では、CRAN 公式パッケージ mmrm を使った反復測定混合モデルの実装方法を、データ準備から共分散構造比較・LS Means 推定・SAS との対応関係まで一気通貫で紹介しました。R で MMRM を扱う上での実用上のボトルネックだった「SAS PROC MIXED との一致」「速度・収束安定性」「Kenward-Roger 補正」のすべてが、このパッケージで実現されています。
規制当局向けの主解析として R を採用するハードルは年々下がっており、特に mmrm はその流れを加速させた最重要パッケージのひとつです。次回はこのパッケージを使って、多重代入法(Multiple Imputation)と組み合わせた感度解析を実装する方法を紹介します。エスチマンドフレームワークでの「Hypothetical 戦略」を実装する具体的な手順まで踏み込む予定ですので、ぜひ続きをお楽しみください。