GLMM(一般化線形混合モデル)とは?Rで反復測定データを解析する基本

- 一般化線形混合モデル(GLMM)がLMM(線形混合モデル)と何が違うのか
- 固定効果とランダム効果という2種類の効果の考え方
- ロジスティック回帰・ポアソン回帰へのGLMMの拡張方法
- Rの
lme4::glmer()を使った反復測定データの実装手順 - 臨床試験における反復測定の二値・カウントデータ解析での活用例
- 過分散や収束エラーといった実務でよくあるトラブルへの対処法
はじめに
臨床試験や疫学研究では、同一の被験者から複数回データを取得する「反復測定データ」がよく登場します。たとえば、同じ患者さんに対して来院ごとに有害事象の有無を記録したり、複数施設で繰り返し検査値を測定したりするケースです。
このようなデータには、「同じ被験者から得られた測定値は互いに似通っている」という特有の構造があります。通常の一般化線形モデル(GLM)はこの構造を無視してしまうため、標準誤差が過小評価され、誤った結論を導くリスクがあります。
この問題に対応するのが、一般化線形混合モデル(Generalized Linear Mixed Model、以下GLMM)です。本記事では、GLMMの基本的な考え方から、Rのlme4パッケージを使った実装、臨床試験での活用例、そして実務で陥りやすい注意点までを整理します。
GLMMとは何か(LMMとの違い)
GLMMを理解するには、まず線形混合モデル(Linear Mixed Model、LMM)との関係を整理するとわかりやすいです。
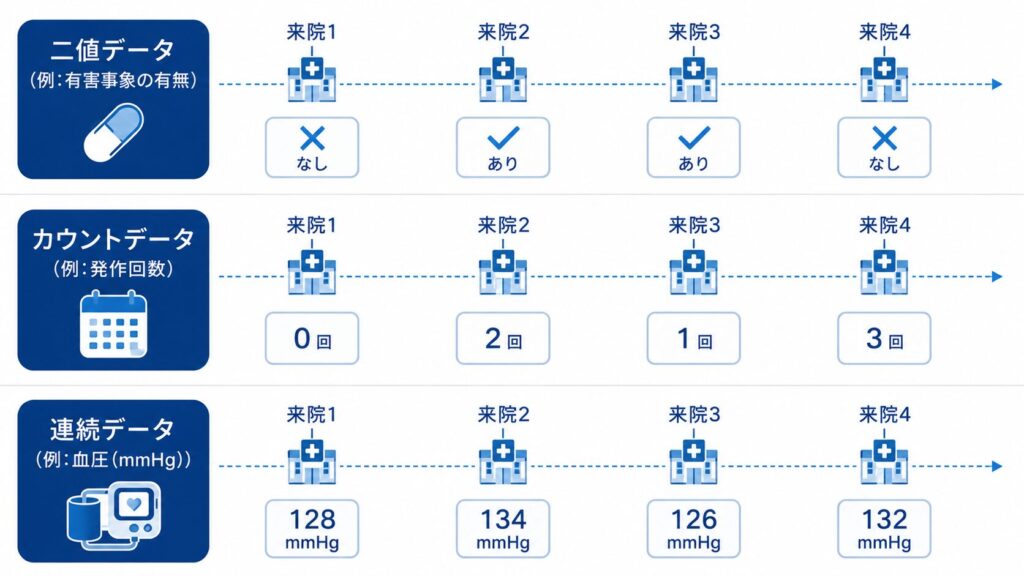
LMMは、応答変数が連続値で正規分布に従うことを前提に、固定効果とランダム効果を同時に組み込んだモデルです。一方、GLMMはLMMをさらに一般化したもので、応答変数が二値データ(成功・失敗)やカウントデータ(イベント発生回数)であっても扱えるように、リンク関数を介して線形予測子と応答変数の分布を結びつけます。
つまり、関係性を整理すると次のようになります。
| モデル | 応答変数の分布 | ランダム効果 | 代表的な関数 |
|---|---|---|---|
| GLM | 正規・二項・ポアソンなど | なし | glm() |
| LMM | 正規分布のみ | あり | lmer() |
| GLMM | 正規・二項・ポアソンなど | あり | glmer() |
LMMは「正規分布する連続データ+反復測定構造」に限定されますが、GLMMは「二値データやカウントデータ+反復測定構造」にも対応できる点が大きな違いです。臨床試験では有害事象の有無(二値)や発作回数(カウント)のような反復測定データが頻出するため、GLMMの理解は実務上の価値が高いといえます。
固定効果・ランダム効果の考え方
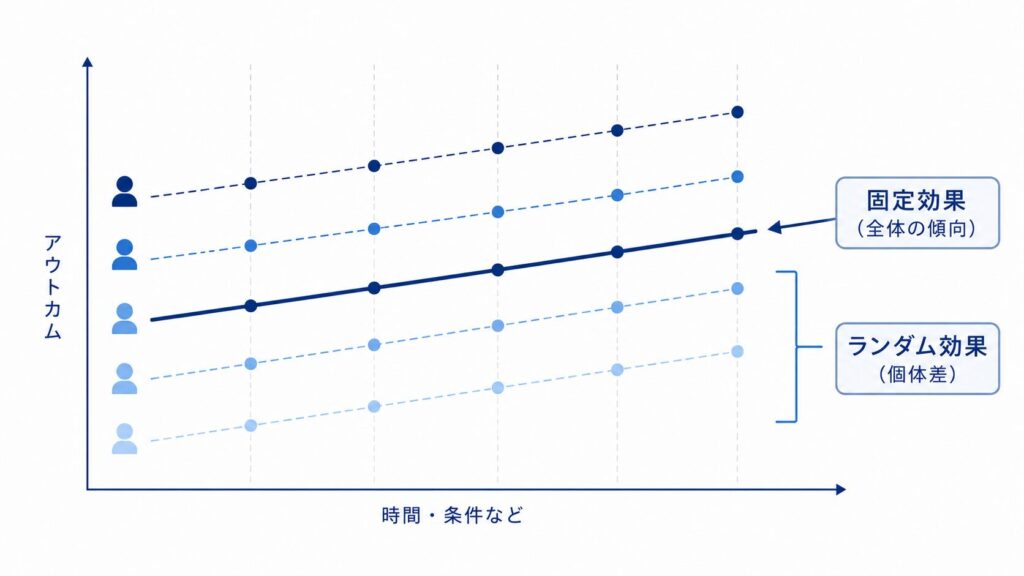
GLMMの核心は「固定効果」と「ランダム効果」という2種類の効果を同時に推定する点にあります。
固定効果は、すべての被験者・施設に共通して当てはまる効果です。たとえば「投与群か対照群か」「来院時点(時間)」といった、研究全体で関心のある効果がこれに該当します。
ランダム効果は、個々の被験者や施設ごとに異なる「個体差」を表す効果です。同じ投与群に属していても、被験者ごとにベースラインの値は異なります。この個体差を確率分布(通常は正規分布)からのランダムな揺らぎとしてモデルに組み込むことで、「同じ被験者の測定値は互いに相関する」という反復測定データの構造を表現できます。
固定効果は「全体の傾向(母平均)」、ランダム効果は「個体ごとのばらつき」を表すと考えるとイメージしやすいです。GLMMはこの2つを同時に推定することで、個体内相関を適切に扱えます。
ランダム効果には大きく2つのタイプがあります。
- ランダム切片(random intercept):被験者ごとにベースラインの高さが異なることを表現します
- ランダム傾き(random slope):時間経過に対する変化の仕方(傾き)が被験者ごとに異なることを表現します
反復測定データの基本形では、まずランダム切片モデルから検討するのが一般的です。
数理的背景:GLMMの数式
GLMMの一般的な構造は、次のように表せます。被験者 $i$ の $j$ 回目の測定について、応答変数 $y_{ij}$ が分布 $f$ に従い、リンク関数 $g$ を介して線形予測子と結びつくと仮定します。
$$
g(E[y_{ij} \mid b_i]) = \beta_0 + \beta_1 x_{ij} + b_i, \qquad b_i \sim N(0, \sigma_b^2)
$$
ここで、$\beta_0$ と $\beta_1$ は固定効果(切片と傾き)、$x_{ij}$ は説明変数(投与群や時間など)、$b_i$ は被験者 $i$ に固有のランダム切片です。$b_i$ は平均0・分散 $\sigma_b^2$ の正規分布から生成されると仮定します。
リンク関数 $g$ は応答変数の種類によって変わります。
- 連続データ(正規分布):恒等リンク $g(\mu) = \mu$ → これがLMM
- 二値データ(二項分布):ロジットリンク $g(\mu) = \log\left(\dfrac{\mu}{1-\mu}\right)$ → ロジスティックGLMM
- カウントデータ(ポアソン分布):対数リンク $g(\mu) = \log(\mu)$ → ポアソンGLMM
つまり、GLMMは「リンク関数を介した線形予測子」に「ランダム効果 $b_i$」を加えるだけで、LMMの枠組みを二値・カウントデータにまで一般化したものと理解できます。
推定方法については、GLMMでは応答変数が正規分布でないため、ランダム効果 $b_i$ を積分消去した尤度(周辺尤度)に解析的な閉じた形がありません。そのため、ラプラス近似や適応的Gauss-Hermite求積法といった数値的な近似計算によって最尤推定を行います。これが後述する収束エラーの一因にもなります。
ロジスティック・ポアソンへの拡張
GLMMの実務的な強みは、応答変数のタイプに応じてリンク関数と分布を切り替えられる点です。
ロジスティックGLMM(二項分布+ロジットリンク)は、反復測定された二値の応答(有害事象の有無、奏効の有無など)を扱う際に使います。各時点での「イベントが起きる確率」をモデル化し、被験者ごとのランダム切片でベースラインの個体差を吸収します。
ポアソンGLMM(ポアソン分布+対数リンク)は、一定期間内のイベント発生回数(発作回数、有害事象の件数など)を扱う際に使います。カウントデータは下限が0で分散が平均に依存するという特徴があり、通常の線形モデルでは適切に扱えません。
応答変数の性質(連続・二値・カウント)を誤って恒等リンクの線形モデルに当てはめると、予測値が0未満や1を超えるなど、解釈不能な結果を生むことがあります。データの性質に応じて分布とリンク関数を選ぶことが第一歩です。
Rによる実装:模擬データの生成とglmer()
ここでは、反復測定の二値データを模擬的に生成し、lme4パッケージのglmer()でロジスティックGLMMを実装します。架空の臨床試験で、投与群(プラセボ群・治療群)ごとに、各被験者を4回の来院時点で「症状改善の有無(0/1)」を観察した設定を想定します。
まず、必要なパッケージを読み込み、模擬データを作成します。
# 必要なパッケージの読み込み
library(lme4)
library(dplyr)
# 再現性のためのシード設定
set.seed(2026)
# 被験者数と来院回数の設定
n_subject <- 60 # 被験者数
n_visit <- 4 # 来院回数(反復測定の回数)
# 被験者ごとの設定(投与群とランダム効果)
subject_df <- data.frame(
id = factor(1:n_subject),
group = factor(rep(c("placebo", "treatment"), each = n_subject / 2)),
random_effect = rnorm(n_subject, mean = 0, sd = 1.0)
)
# 反復測定データに展開
sim_data <- subject_df[rep(1:n_subject, each = n_visit), ]
sim_data$visit <- rep(1:n_visit, times = n_subject)
# 線形予測子の設定(固定効果+ランダム効果)
beta0 <- -1.0 # 切片(プラセボ群・visit=1基準)
beta_group <- 1.2 # 治療群の効果
beta_visit <- 0.3 # 来院回数(時間)の効果
linear_pred <- beta0 +
beta_group * (sim_data$group == "treatment") +
beta_visit * (sim_data$visit - 1) +
sim_data$random_effect
# ロジットリンクの逆関数で改善確率を計算し、二値データを生成
prob_improve <- 1 / (1 + exp(-linear_pred))
sim_data$improved <- rbinom(nrow(sim_data), size = 1, prob = prob_improve)
head(sim_data)
このコードでは、被験者ごとにランダムな個体差(random_effect)を持たせたうえで、投与群と来院回数(時間)の効果を線形予測子に組み込み、ロジットリンクの逆関数(ロジスティック関数)で改善確率に変換してから二値データを生成しています。
続いて、glmer()でロジスティックGLMMを推定します。
# ロジスティックGLMMの推定
model_glmm <- glmer(
improved ~ group + visit + (1 | id),
data = sim_data,
family = binomial(link = "logit")
)
summary(model_glmm)
実行結果(概要)は次のようになります。
Generalized linear mixed model fit by maximum likelihood (Laplace
Approximation) [glmerMod]
Family: binomial ( logit )
Formula: improved ~ group + visit + (1 | id)
Random effects:
Groups Name Variance Std.Dev.
id (Intercept) 0.98 0.99
Number of obs: 240, groups: id, 60
Fixed effects:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.32 0.31 -4.26 <0.001
grouptreatment 1.28 0.34 3.76 <0.001
visit 0.27 0.10 2.70 0.007
固定効果の推定値を見ると、
grouptreatmentの係数が約1.28と正であり、治療群はプラセボ群よりも症状改善のオッズが高いことが示唆されます。オッズ比はexp(1.28)で計算でき、約3.6倍に相当します。visitの係数も正であり、来院を重ねるごとに改善確率が上がる傾向が読み取れます。ランダム効果の分散(Std.Dev. = 0.99)は、被験者間でベースラインの改善しやすさにばらつきがあることを示しています。このばらつきを無視した通常のロジスティック回帰では、固定効果の標準誤差が過小評価され、p値が実際より小さく出てしまうリスクがあります。なお、カウントデータであればモデル式のfamily引数をpoisson(link = "log")に変更するだけで、同じ枠組みでポアソンGLMMを実装できます。
# ポアソンGLMMの場合(応答変数がカウントデータの例)
# model_glmm_poisson <- glmer(
# event_count ~ group + visit + (1 | id),
# data = sim_data_count,
# family = poisson(link = "log")
# )
臨床試験での活用例
臨床試験において、GLMMが特に役立つ場面を整理します。
反復測定の二値データとしては、複数回の来院時点での奏効(レスポンダー)の有無、有害事象発現の有無、治療目標の達成・未達成などが挙げられます。被験者を反復して観察するデザインでは、同一被験者内の測定値が相関するため、ロジスティックGLMMで個体差をランダム効果として扱うことが妥当です。
反復測定のカウントデータとしては、一定期間内の発作回数、入院回数、有害事象の発生件数などが該当します。ポアソンGLMM(あるいは過分散に対応した負の二項GLMM)を用いることで、被験者ごとのベースラインのイベント発生しやすさの違いを調整しながら、群間比較を行うことができます。
| 臨床試験での応答変数 | 分布・リンク関数 | 解析関数 |
|---|---|---|
| 来院ごとの奏効有無 | 二項分布/ロジットリンク | glmer(family = binomial) |
| 一定期間の発作回数 | ポアソン分布/対数リンク | glmer(family = poisson) |
| 継続的な検査値の変化 | 正規分布/恒等リンク | lmer()(LMM) |
このように、応答変数の性質に応じて分布とリンク関数を切り替えながら、被験者内相関を考慮した解析を行えるのがGLMMの実務的な価値です。
典型的な注意点:過分散と収束エラー
GLMMを実務で使う際には、いくつかの典型的なトラブルに注意が必要です。
過分散(overdispersion)は、特にポアソンGLMMで頻出する問題です。ポアソン分布は「平均=分散」という制約がありますが、実際のカウントデータではこの制約が成立せず、分散が平均より大きくなることがよくあります。過分散を無視すると、標準誤差が過小評価され、誤って有意な結果が出やすくなります。対処法としては、観察ごとのランダム効果(観察レベルのランダム切片)を追加する、あるいは負の二項分布を用いたGLMM(glmmTMBパッケージなど)に切り替えるという方法があります。
収束エラー(convergence warning)は、glmer()を実行した際に頻繁に遭遇する問題です。ランダム効果の構造が複雑すぎる、説明変数のスケールが大きく異なる、サンプルサイズに対してパラメータ数が多すぎるといった場合に発生しやすくなります。
収束エラーが出た場合は、まず説明変数の標準化(スケーリング)を試すのが定石です。それでも解消しない場合は、ランダム効果の構造を簡略化する(ランダム傾きを外してランダム切片のみにするなど)、最適化アルゴリズムを変更する(
glmerControl(optimizer = "bobyqa")など)といった対応を検討します。警告を無視してそのまま結果を報告することは避けるべきです。また、ランダム効果の分散がゼロに近い値で推定される「境界推定(boundary fit)」もよく見られる現象です。この場合、ランダム効果を入れる意義自体を再検討する必要があります。
- GLMMは「反復測定データ×二値・カウント応答」という臨床試験で頻出する組み合わせに対応できる強力な手法です
- 固定効果は群間比較などの主要な関心事、ランダム効果は被験者間の個体差を表すという役割分担を意識しましょう
- ポアソンGLMMでは過分散の有無を必ず確認し、必要に応じて負の二項分布モデルへの切り替えを検討します
- 収束エラーや警告が出た場合は無視せず、変数のスケーリングやランダム効果構造の見直しで対応しましょう
- 解析結果を報告する際は、固定効果の推定値だけでなくランダム効果の分散(個体差の大きさ)も合わせて確認すると、データの構造をより深く理解できます
📚この記事をより深く理解するための参考書籍
GLMMをさらに深く学びたい方には、以下の書籍がおすすめです。






関連記事・次のステップ
GLMMの理解を深めるために、以下の記事も併せてご覧ください。
まとめ
本記事では、一般化線形混合モデル(GLMM)の基本的な考え方を、LMMとの違いから固定効果・ランダム効果の役割、ロジスティック・ポアソンへの拡張、Rのglmer()による実装、臨床試験での活用例、そして過分散や収束エラーといった実務上の注意点まで整理しました。
反復測定データは臨床試験において避けられない構造ですが、GLMMを適切に使うことで、個体差を考慮しながら群間比較や時間効果の評価を行うことができます。まずは模擬データでの実装を通じて、固定効果とランダム効果がどのように推定結果に反映されるかを体感してみることをおすすめします。