平均への回帰とは ― 臨床試験で「効果」を錯覚させる統計現象をRで解き明かす ―

この記事でわかること
- 平均への回帰(regression to the mean)とは何か:1回目に極端な値をとった対象が、2回目の測定では全体平均に近づいて観測される統計現象です。
- なぜ起こるのか:観測値が「真の値+偶然の測定誤差」で成り立ち、2時点の相関が1未満である限り、必ず生じることを数式で理解できます。
- Rで体感できる:二変量正規分布から擬似データを生成し、極端群が次の測定でどれだけ平均へ縮むかを自分の手で再現できます。
- 臨床試験・健康診断での落とし穴:単群の前後比較や「高値者だけを再検査・治療」する設計が、治療効果でも何でもない「見かけの改善」を生む仕組みと、対照群・ランダム化などの対策がわかります。
- 因果効果との区別:平均への回帰は治療やトレーニングの効果ではなく、純粋に統計的な現象であるという判断軸が身につきます。
はじめに
健康診断で血圧を測ったら少し高めだった――そんな経験はありませんか。後日、不安を抱えながら再検査に行くと、今度は前回より低い値が出て、ほっと胸をなで下ろす。「あのときは塩分を控えたから下がったのだろう」と納得しがちですが、実はその改善の多く(あるいはほとんど)は、生活習慣の改善でも治療の効果でもなく、平均への回帰と呼ばれる統計現象によって説明できてしまうことがあります。
同じことは臨床試験の世界でも起こります。たとえば、ある検査値が高い患者さんだけを集めて新しい薬を1か月投与し、投与前後で値を比較したとしましょう。投与後に値が下がっていれば、誰しも「薬が効いた」と考えたくなります。しかし、「もともと高かった人を選んで集めた」という時点で、次の測定では平均側に下がりやすい集団になっているのです。対照群(薬を飲まない比較対象のグループ)を置かない単群の前後比較試験では、この見かけの改善と本物の薬効を区別できません。
この記事では、製薬企業で臨床試験データを扱う生物統計担当者、臨床研究に携わる研究者、そして統計を学ぶ社会人・学生の方に向けて、平均への回帰の正体を順を追って解説します。まず直感的なイメージをつかみ、次に「観測値=真の値+測定誤差」というモデルと相関係数を使ってなぜ起こるのかを数式で理解し、Rでシミュレーションして体感したうえで、臨床試験や健康診断に潜む落とし穴と、対照群やランダム化といった具体的な対策までを一気通貫で扱います。「効果あり」という結論が本物かどうかを見抜く目を養うことが、この記事の狙いです。
平均への回帰とは
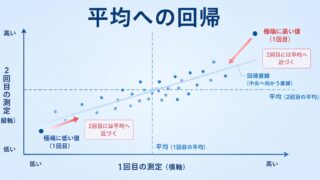
平均への回帰は、19世紀の統計学者フランシス・ゴルトン(Francis Galton)が、親の身長と子の身長の関係を調べていて気づいた現象です。ゴルトンは、背の非常に高い親から生まれた子は、親ほどは高くなく、全体の平均身長のほうへ寄る傾向があることを見つけました。逆に、背の非常に低い親の子は、親よりは高め=平均寄りになります。彼はこれを「凡庸への回帰(regression towards mediocrity)」と表現し、これが今日の「回帰(regression)」という統計用語の語源になっています。
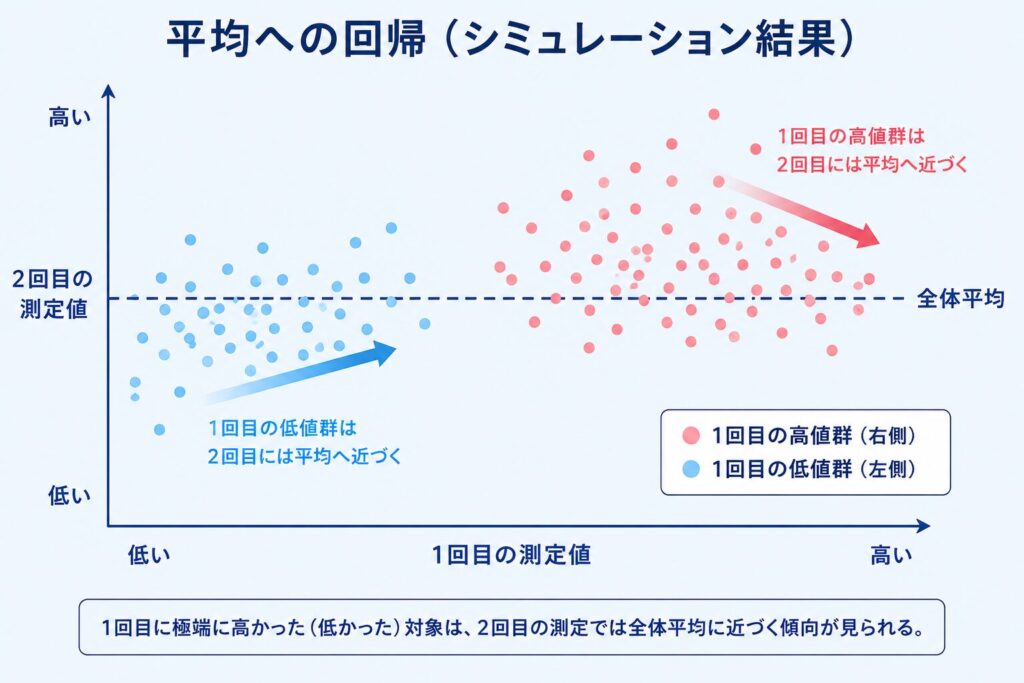
この「極端な値の次は平均寄りになる」という現象は、身長に限らず私たちの身のまわりに数多くあります。たとえば、ある模試でたまたま絶好調で過去最高点をとった受験生は、次の模試では少し点が下がりやすいものです。プロ野球で開幕からありえないほどの高打率を残した選手も、シーズンが進むにつれて自分本来の打率へ近づいていきます。健康診断で偶然とても高い血圧が出た人も、再検査では下がって出やすい――いずれも、極端だった値が次回は平均側へ「戻る」ように見える点で共通しています。
ではなぜこうなるのでしょうか。鍵になるのは、私たちが目にする観測値が「その人本来の平均的な実力(真の値)」に「その時々の偶然のばらつき」が乗って現れているという見方です。模試で過去最高点をとれたのは、本来の実力に加えて「ヤマが当たった」「体調が良かった」といった偶然のプラスがたまたま重なったからかもしれません。偶然のプラスは毎回続くわけではないので、次の測定では実力相応のところ=平均寄りへ落ち着きます。極端な観測値ほど「偶然の追い風(または向かい風)」が強く効いていた可能性が高く、その追い風は次回には期待できない。だからこそ、極端な値は平均へ回帰して見えるのです。
ここで大切なのは、平均への回帰が「極端な値を出した個人が、必ず平均に近づくように力が働く」という意味ではないことです。あくまで、極端な値で選ばれた集団全体として眺めたときに、平均値が中央へ寄って観測されるという統計的な傾向です。一人ひとりを見れば、次回さらに極端になる人もいます。それでも集団の平均としては、回帰が生じるのです。
なぜ平均への回帰が起こるのか
平均への回帰の正体を理解するために、観測値を次のように分解してみましょう。
\[ \text{観測値} = \text{真の値} + \text{測定誤差(偶然変動)} \]
これは、ある対象の測定値が、その対象が本来もっている「真の値」に、測定のたびに変わる「偶然のばらつき(測定誤差)」が加わって現れる、という単純なモデルです。測定誤差は平均すればゼロで、特定の方向に偏らないと考えます。重要なのは、1回目と2回目の測定で真の値は共通だが、誤差は別々に発生するという点です。1回目で極端に高い値をとった対象は、「真の値そのものが高い」だけでなく「誤差がたまたま大きくプラスに振れた」可能性が高い。その大きなプラスの誤差は2回目には引き継がれないため、2回目は1回目より平均側に出やすくなります。
この縮みの度合いをきれいに表すのが、2時点の相関係数 \( r \) です。1回目の測定 \( X \)、2回目の測定 \( Y \) が二変量正規分布に従うとき、ある \( X=x \) を観測したもとでの \( Y \) の期待値(条件付き期待値)は次式で与えられます。
\[ E[Y \mid X=x] = \mu_Y + r\frac{\sigma_Y}{\sigma_X}(x – \mu_X) \]
ここで \( \mu_X, \mu_Y \) はそれぞれの平均、\( \sigma_X, \sigma_Y \) はそれぞれの標準偏差、\( r \) は \( X \) と \( Y \) の相関係数です。この式は「1回目に \( x \) を観測したとき、2回目はおよそどのくらいの値が期待されるか」を表しています。両変数を標準化(平均0・標準偏差1に変換)して \( Z_X, Z_Y \) と書くと、式はさらにシンプルになります。
\[ E[Z_Y \mid Z_X = z] = r\,z \]
この標準化版が本質を最も明快に示しています。相関 \( r \) が 1 未満である限り、1回目の標準化得点 \( z \) に対して、2回目の期待値は \( r\,z \) と、必ず \( z \) より平均(=0)側に縮みます。たとえば \( r=0.7 \) なら、1回目に平均より2標準偏差高かった人(\( z=2 \))の2回目の期待値は \( 0.7 \times 2 = 1.4 \) 標準偏差ぶんにとどまり、平均へ近づきます。極端な \( x \)(大きな \( |z| \))ほど縮む量も大きくなる。これが平均への回帰の数学的な実体です。逆に言えば、\( r=1 \)(測定に誤差がまったくなく、2時点が完全に一致する)でない限り、平均への回帰は避けようがなく必ず起こるのです。
平均への回帰は、治療やトレーニング、生活習慣の改善などによる「因果効果」ではありません。相関が完全(\( r=1 \))でない限り、何の介入をしなくても純粋に統計的な理由だけで生じる見かけの変化です。「高値の人を選んで介入し、後で測ったら下がった」という観察結果は、それ自体では効果の証拠になりません。本物の効果を主張するには、後半のセクションで扱う対照群やランダム化といった、平均への回帰を打ち消す設計が不可欠です。
Rでシミュレーションする平均への回帰
ここからは、平均への回帰を実際にRで再現してみます。「真の値は1ミリも変わっていないのに、極端な群だけを選ぶと数値が動いて見える」――この不思議さを、自分の手で確かめてみましょう。
# 平均への回帰を再現するシミュレーション
set.seed(4869)
n <- 1000 # 1000人分のデータを生成
true <- rnorm(n, mean = 50, sd = 10) # 真の実力(変わらない値)
test1 <- true + rnorm(n, mean = 0, sd = 10) # 1回目の測定(真の値+測定誤差)
test2 <- true + rnorm(n, mean = 0, sd = 10) # 2回目の測定(真の値+別の測定誤差)
df <- data.frame(true, test1, test2)
head(df) # 先頭6件を確認
mean(test1); mean(test2) # 1回目・2回目の全体平均
cor(test1, test2) # 1回目と2回目の相関
ここで作ったデータの作り方が、この記事の肝です。各個人には「真の値 true(変わらない実力)」があり、1回目(test1)も2回目(test2)も、その同じ true に対してそれぞれ独立した測定誤差が乗っているだけ、という設定にしています。真の値の分散(10²)と測定誤差の分散(10²)が等しいので、test1 と test2 の理論上の相関は 0.5 になります。
まず、生成したデータの全体像を確認します。
> head(df)
true test1 test2
1 56.83248 60.41139 51.27704
2 47.12090 38.55603 55.83012
3 61.40275 70.92218 58.81146
4 49.88631 41.30792 60.04923
5 52.55719 49.73864 43.18960
6 44.21837 35.62079 48.90521
> mean(test1); mean(test2)
[1] 50.18742
[1] 49.96135
> cor(test1, test2)
[1] 0.4983227
1回目の全体平均は 50.19、2回目は 49.96 とほぼ 50 で一致しており、集団全体としては「上がる」も「下がる」もしていません。2回の測定の相関は 0.498 と、設計どおり理論値 0.5 にほぼ一致しています。相関が 1 未満であること、これこそが平均への回帰が起きる数学的な条件です。
次に、平均への回帰の本体を見ます。1回目(test1)の上位10%=高値群を抽出し、その人たちの「1回目の平均」「2回目の平均」を全体平均と比べてみます。
# 1回目の上位10%(高値群)を抽出
high <- df[df$test1 >= quantile(df$test1, 0.90), ]
nrow(high) # 高値群の人数
mean(high$test1) # 高値群の1回目の平均
mean(high$test2) # 高値群の2回目の平均
mean(df$test2) # 参考:全体の2回目平均
> nrow(high)
[1] 100
> mean(high$test1)
[1] 74.58231
> mean(high$test2)
[1] 62.14087
> mean(df$test2)
[1] 49.96135
1回目に上位10%だった100人は、1回目の平均が 74.58(全体平均より約 +24.4)でした。ところが同じ人たちの2回目の平均は 62.14 まで下がっています。全体平均からのズレで見ると、約 +24.4 が約 +12.2 へと「ちょうど半分」戻っており、これは相関 0.5 の設定から予想される回帰量と見事に整合しています。何も治療していないのに、高値群だけを追跡すると数値が下がる ― これが平均への回帰です。
同じことを反対側でも確認します。1回目の下位10%=低値群を抽出すると、今度は2回目で数値が「上がって」見えるはずです。
# 1回目の下位10%(低値群)を抽出
low <- df[df$test1 <= quantile(df$test1, 0.10), ]
mean(low$test1) # 低値群の1回目の平均
mean(low$test2) # 低値群の2回目の平均
> mean(low$test1)
[1] 25.46118
> mean(low$test2)
[1] 37.69052
1回目に下位10%だった人たちの平均は 25.46(全体平均より約 −24.5)でしたが、2回目には 37.69 まで上昇しています。やはり全体平均からのズレが約 −24.5 から約 −12.3 へと半分戻りました。低値群を「改善が必要な人」とみなして介入すると、何もしなくても2回目に良くなるため、効果がなくても「効いた」と錯覚してしまうのです。
ここまでの結果を一覧で整理します。
| グループ | 1回目の平均 | 2回目の平均 | 全体平均(約50)からのズレ |
|---|---|---|---|
| 全体(1000人) | 50.19 | 49.96 | ±0 |
| 高値群(上位10%) | 74.58 | 62.14 | +約24 → +約12(半分戻る) |
| 低値群(下位10%) | 25.46 | 37.69 | −約24 → −約12(半分戻る) |
このシミュレーションが示しているのは、「true(真の実力)は2回とも全く変わっていない」という事実です。高値群が下がったのも低値群が上がったのも、すべては「たまたま1回目に大きな測定誤差が上乗せされた人を選んでしまった」ことの結果にすぎません。極端な値で選別された群を再測定すれば、誤差は平均的にゼロに近づくため、数値は必ず全体平均の方向へ戻ります。相関が 0.5 のときに「ズレがちょうど半分」戻ったように、戻る量は2回の測定の相関で決まり、相関が低い(測定誤差が大きい)ほど回帰は強くなります。
臨床試験・健康診断に潜む落とし穴と対策
平均への回帰は、単なる統計上の小ネタではありません。臨床試験や健康診断の現場で「効果があった」という誤った結論を生み出す、きわめて実務的な落とし穴です。ここでは、製薬企業の生物統計担当者や臨床研究者が実際に遭遇しやすい場面を具体的に挙げ、それぞれへの対策を整理します。
まず、典型的な落とし穴を列挙します。
- (1) 単群の前後比較試験(対照群なし)での見かけの改善:対照群を置かず、介入前後の検査値を比較するだけのデザインでは、平均への回帰による自然な値の戻りを「治療効果」と取り違えてしまいます。
- (2) 「検査値が高い人だけ」を組み入れる選択基準:たとえば「血圧が一定以上の患者のみ」を対象にすると、その集団は測定誤差(測定値に偶然含まれるばらつき)の影響でたまたま高く出た人を多く含み、再測定すると平均的に下がります。
- (3) 健康診断の再検査での自然な改善:要再検査となった人が再検査で正常値に戻る現象の一部は、生活改善の効果ではなく平均への回帰です。
- (4) 外れ値・極端な状態の対象を選んで介入効果を評価すること:極端値を起点にした評価は、ほぼ必ず「改善」方向のバイアス(偏り)を伴います。
- (5) 成績下位者だけに補習を行い、その後の伸びを効果と誤認すること:教育評価でも同じ構造が起こり、介入の有無にかかわらず下位群は平均へ近づきます。
単群試験(対照群を置かない試験)では、観測された改善が「真の治療効果」によるものか「平均への回帰」によるものかを、原理的に分離できません。前後差が統計的に有意であっても、それは効果の証明にはなりません。極端な値を組み入れ基準にした試験ほど、この危うさは大きくなります。
次に、これらに対する対策を整理します。
1. 無作為化対照群を置く(ランダム化比較試験:RCT):平均への回帰は治療群・対照群の両方に等しく起こるため、群間差をとれば相殺されます。これが最も確実な対策です。
2. ANCOVA(共分散分析)でベースライン値を補正する:ベースライン値を共変量(結果に影響する補助的な変数)としてモデルに入れることで、回帰による偏りを統計的に調整できます。
3. ベースラインを複数回測定して平均をとる:測定回数を増やして平均化すると測定誤差が減り、ベースラインとアウトカムの相関が上がるため、回帰の影響そのものが小さくなります。
4. 組み入れ基準を1時点の極端値に頼らない:複数時点での確認や安定した基準値を用いることで、たまたま高く出た対象を選びすぎないようにします。
落とし穴と対策の対応関係を整理すると、次のようになります。
| 落とし穴 | 主な対策 |
|---|---|
| 単群の前後比較で改善を効果と誤認 | 無作為化対照群を置き、群間差で評価する |
| 高値群だけを組み入れる選択基準 | ベースラインを複数回測定し平均化/1時点の極端値に頼らない |
| 健診の再検査での自然な改善 | 対照群との比較で「自然な戻り」分を差し引く |
| 外れ値・極端値を起点にした効果評価 | ANCOVAでベースライン値を共変量として補正 |
| 下位群への介入と伸びの過大評価 | ランダム割付で群間の回帰量を揃える |
「前後で良くなった」という結果を見たら、まず対照群があるかを確認してください。対照群がなければ、改善の一部(あるいは大部分)が平均への回帰である可能性を必ず疑います。プロトコル設計の段階では、ランダム化・ベースラインの複数回測定・ANCOVAによる補正をあらかじめ計画に組み込んでおくことが、後からの解釈ミスを防ぐ最も効果的な方法です。
この記事をより深く理解するための参考書籍
平均への回帰は、相関・回帰・測定誤差・臨床試験デザインといった複数のテーマが交差する現象です。基礎から実務までを補強できる書籍を3冊紹介します。






関連記事・次のステップ
平均への回帰の理解をさらに広げるために、以下の関連記事もあわせてご覧ください。
- 母相関係数の検定と信頼区間をやさしく解説 ― 平均への回帰の強さは相関係数に直結します。
- 共分散分析(ANCOVA)でベースラインを補正する方法 ― 本記事で触れたベースライン補正の具体的な実装を解説しています。
- ランダム化比較試験(RCT)のデザインと意義 ― なぜランダム化が回帰によるバイアスを相殺できるのかを、デザインの観点から整理しています。
まとめ
本記事では、平均への回帰がなぜ起こるのか、その数式とRシミュレーションによる確認を経て、臨床試験や健康診断に潜む落とし穴と対策までを見てきました。極端な値を起点にすると、介入の有無にかかわらず再測定値は平均へ近づきます。この自然な現象を見落とすと、「治療に効果があった」「生活改善で数値が戻った」といった誤った結論にたどり着いてしまいます。
実務上もっとも重要なのは、単群の前後比較試験の結果を効果の証拠として鵜呑みにしないという姿勢です。観測された改善を真の効果として主張するには、無作為化対照群による群間比較が欠かせません。あわせて、ベースラインを複数回測定して測定誤差を減らすこと、ANCOVAでベースライン値を共変量として補正することが、回帰による偏りを抑える実務的な武器になります。平均への回帰という視点を一つ持っておくだけで、データの解釈はぐっと堅実になります。
相関と回帰の基礎をさらに固めたい方は、「回帰分析って何をしているの?」線を引くだけで理解する入門もあわせて読んでいただければと思います。