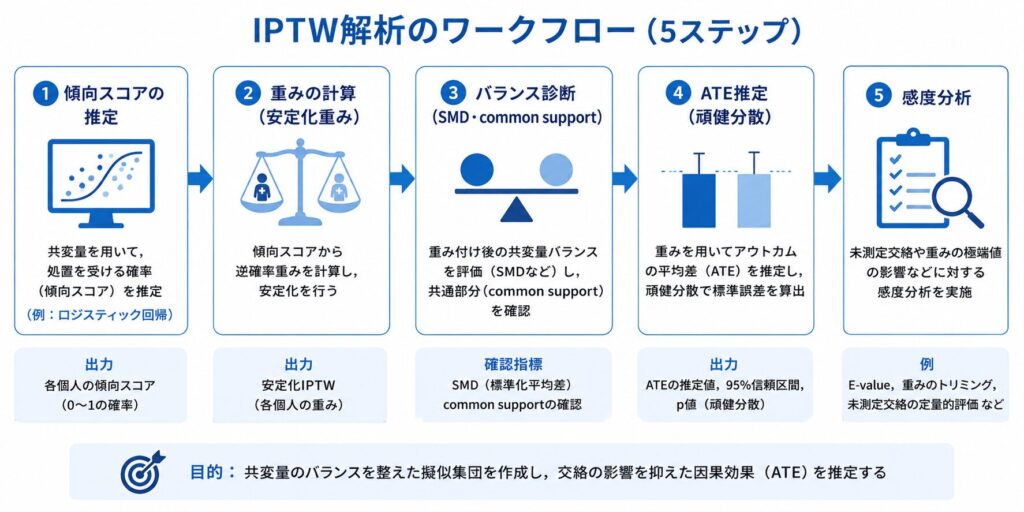
逆確率重み付け(IPTW)によるATE推定 ― 傾向スコア分析の実践的応用とR・SAS実装 ―

・逆確率重み付け(IPTW)の基本的な考え方と「擬似集団」による交絡調整の直感
・ATE(集団全体の平均処置効果)とATT(処置群の平均処置効果)の違いと使い分け
・Horvitz-Thompson推定量・安定化重み・二重ロバスト推定(AIPW)の数理的背景
・RのWeightIt/cobalt、およびSASでIPTW重みを計算しATEを推定する具体的な実装
・共変量バランス(SMD)・有効サンプルサイズ・重みのトリミングなど実務上の診断と注意点
はじめに
観察研究やリアルワールドデータ(RWD)から処置効果を正しく推定するには、処置群と対照群の間に生じる交絡バイアスを適切に調整することが極めて重要になります。ランダム化比較試験(RCT)とは異なり、観察研究では「どの患者が処置を受けたか」が患者背景に依存するため、単純な群間比較は容易にバイアスを含みます。
こうした交絡を調整する代表的な枠組みが傾向スコア分析です。傾向スコア分析には大きくマッチング・層別化・逆確率重み付け(IPTW)の3つの戦略があり、それぞれの基礎については関連記事の傾向スコア分析(Propensity Score Analysis)とはで整理しています。
本記事はその実践編として、逆確率重み付け(IPTW:Inverse Probability of Treatment Weighting)に焦点を当て、理論・数式・R/SAS実装・診断・実務上の注意点までを体系的に解説します。IPTWはマッチングと違って全サンプルを活用できる点が大きな強みですが、傾向スコアが0や1に近い個体で重みが極端になるリスクも伴います。本記事ではその対処法(安定化重み・トリミング)や、より頑健な二重ロバスト推定まで含めて、製薬・医学領域の実務家が現場で使える形で紹介します。
IPTWとは何か ― 擬似集団による交絡調整の直感
IPTWの基本的な発想は、「各個体を、本来受けにくかった割り付けを受けた度合いに応じて重み付けすることで、擬似的なランダム化比較試験を再現する」というものです。
たとえば、傾向スコアが \(e(X) = 0.8\)(=処置を受ける確率が高い)高リスク患者が処置群に割り付けられた場合、この個体は「処置されて当然の人」なので重みは \(1/0.8 = 1.25\) と小さくなります。一方、同じく \(e(X) = 0.8\) でありながら対照群にいる個体は「本来なら処置を受けやすかったのに対照群にいる希少な人」なので、重みは \(1/(1-0.8) = 5.0\) と大きくなります。
この操作を全個体に施すと、処置群にも対照群にも「あらゆる背景の患者が同じ割合で存在する」仮想的な集団、すなわち擬似集団(pseudo-population)が生成されます。擬似集団のなかでは処置の有無と患者背景が独立になり、群間の単純比較がそのまま因果効果の推定になります。
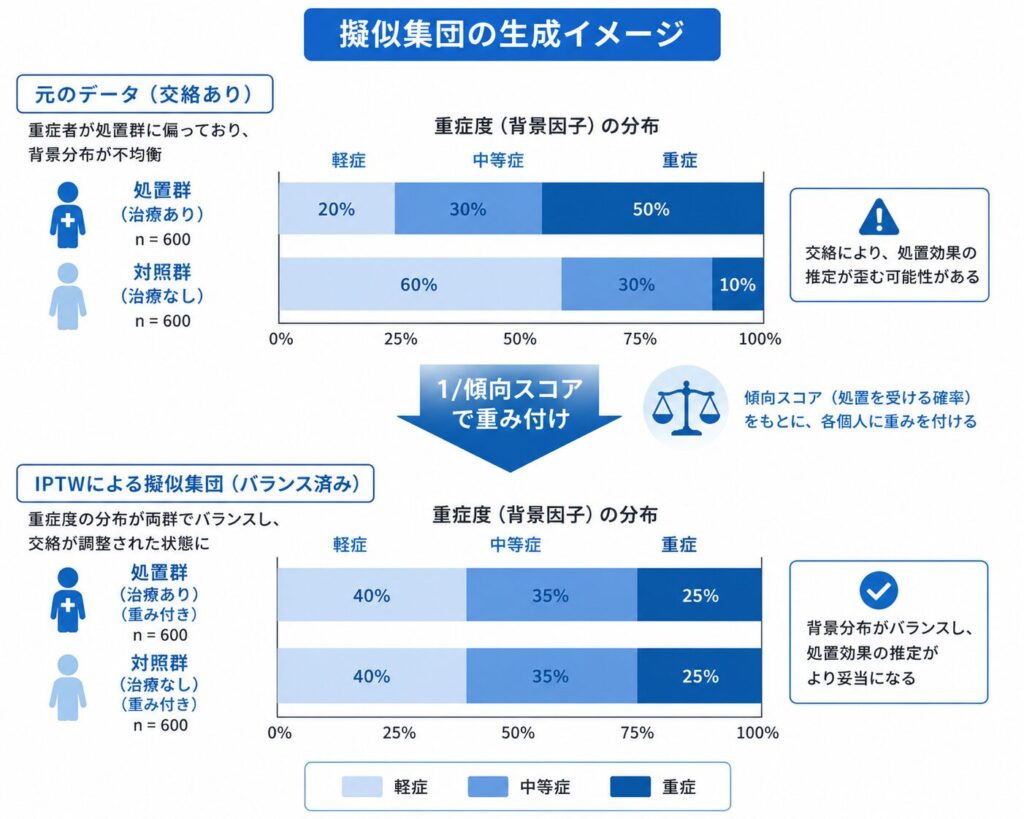
IPTWは「重みで仮想的な母集団を作り替える」手法です。マッチングが一部の個体を捨てて群をそろえるのに対し、IPTWは全個体に重みを与えて活用するため、サンプルを無駄にしにくいという利点があります。
ATEとATTの違い ― 推定対象(estimand)を明確にする
IPTWで推定できる効果量には主にATE(平均処置効果)とATT(処置群における平均処置効果)の2種類があります。どちらを推定したいのかを最初に決めることが、重みの定義と結果の解釈を左右します。これはICH E9(R1)で強調される「推定対象(estimand)」の考え方そのものです。
| 項目 | ATE(平均処置効果) | ATT(処置群の平均処置効果) |
|---|---|---|
| 定義 | 集団全体での平均処置効果 | 実際に処置を受けた個体での平均処置効果 |
| 対象集団 | 集団全体(処置群+対照群) | 実際に処置を受けた人のみ |
| 処置群の重み | \(1/e(X)\) | 1(重み付けなし) |
| 対照群の重み | \(1/(1-e(X))\) | \(e(X)/(1-e(X))\)(オッズ型) |
| 典型的な適用場面 | 政策評価・全集団への介入効果 | 実際に治療を受けた患者への効果 |
規制対応の文脈では「その薬を実際に使った患者での効果(ATT)」が問われる場面も多い一方、公衆衛生上の意思決定では「集団全体に介入したときの効果(ATE)」が重要になります。本記事では以降ATE推定に焦点を当てて解説します。
数理的背景 ― Horvitz-Thompson推定量と安定化重み
Horvitz-Thompson推定量
ATE推定の基本となるのが、標本調査論に由来するHorvitz-Thompson(HT)推定量です。連続または二値アウトカム \(Y\) に対して、ATEは次のように推定されます。
\[\hat{\tau}_{\text{ATE}} = \frac{1}{n} \sum_{i=1}^{n} \left( \frac{T_i Y_i}{e(X_i)} – \frac{(1-T_i) Y_i}{1 – e(X_i)} \right)\]
ここで \(T_i\) は個体 \(i\) の処置割り付け(1=処置群、0=対照群)、\(Y_i\) はアウトカム、\(e(X_i)=P(T_i=1 \mid X_i)\) は傾向スコアです。第1項は処置群を \(1/e(X_i)\) で、第2項は対照群を \(1/(1-e(X_i))\) で重み付けした加重平均であり、両者の差がATEになります。
この推定量が一致性を持つためには、次の2つの前提が必要です。
① 条件付き交換可能性(無視可能な割り付け):測定した共変量 \(X\) で条件付ければ、割り付けが潜在アウトカムと独立になること(未測定交絡がないこと)。
② 正値性(positivity/common support):どの共変量パターンでも処置・対照の両方を受ける確率が0でないこと(\(0 < e(X) < 1\))。
これらは検証しきれない仮定を含むため、感度分析(後述)とセットで運用することが重要です。
安定化重み(Stabilized Weights)
素朴なHT重み \(1/e(X)\)・\(1/(1-e(X))\) は、傾向スコアが0や1に近い個体で極端に大きくなり、推定値の分散を膨らませます。これを抑えるのが安定化重み(stabilized weights)です。
\[sw_i = \frac{T_i \cdot P(T=1)}{e(X_i)} + \frac{(1-T_i) \cdot P(T=0)}{1 – e(X_i)}\]
分子に処置の周辺確率 \(P(T=1)\)・\(P(T=0)\) を掛けることで、重みの平均が1に近づき、分散が大幅に小さくなります。点推定はHT重みと同じ推定対象(ATE)を保ちながら、数値的安定性が改善されるため、実務では安定化重みを標準的に用います。
二重ロバスト推定(AIPW)への発展
IPTWは傾向スコアモデルが正しく特定されていて初めて一致推定になります。この弱点を補うのが、傾向スコアモデルとアウトカム回帰モデルを組み合わせた二重ロバスト推定(AIPW:Augmented IPW)です。
\[\hat{\tau}_{\text{AIPW}} = \frac{1}{n}\sum_{i=1}^{n}\left[ \frac{T_i\{Y_i-\hat{m}_1(X_i)\}}{e(X_i)} + \hat{m}_1(X_i) – \frac{(1-T_i)\{Y_i-\hat{m}_0(X_i)\}}{1-e(X_i)} – \hat{m}_0(X_i)\right]\]
ここで \(\hat{m}_1, \hat{m}_0\) は処置群・対照群それぞれのアウトカム回帰による予測値です。AIPWは「傾向スコアモデルとアウトカムモデルのどちらか一方が正しければ一致推定になる」という二重頑健性(double robustness)を持ちます。近年はこの枠組みに機械学習を組み込んだTMLEなども普及しつつあり、未測定交絡がない前提のもとで頑健性を高める標準的な選択肢になっています。
Rによる実装 ― WeightItでATE推定まで
ここからは、真の効果を既知に設定したシミュレーションデータで、IPTWがどの程度うまく交絡を除去できるかを確認します。真のATEを \(-5\)(処置でアウトカムが5点低下)とし、重症度・年齢・検査値が処置の受けやすさとアウトカムの両方に影響する交絡構造を作ります。
分析の設定
データを生成するコードは次のとおりです。処置割り付けを共変量に依存させることで、意図的に交絡を作り込みます。
library(WeightIt) # 傾向スコア重みの計算
library(cobalt) # 共変量バランスの診断
library(survey) # 重み付き回帰による効果推定
set.seed(1234)
n <- 2000
# 共変量(交絡因子)を生成
age <- round(rnorm(n, 55, 10)) # 年齢
biomarker <- rnorm(n, 0, 1) # ベースライン検査値
severity <- rbinom(n, 1, 0.4) # 重症度(1=重症)
sex <- rbinom(n, 1, 0.5) # 性別(1=男性)
# 処置割り付け:重症・高齢ほど処置を受けやすい(交絡)
lp <- -0.5 + 0.03 * (age - 55) + 0.8 * severity + 0.4 * biomarker
ps_true <- plogis(lp)
treat <- rbinom(n, 1, ps_true)
# アウトカム:真のATE = -5。重症・高齢ほど値が高い
y <- 50 + 0.4 * (age - 55) + 6 * severity + 2 * biomarker - 5 * treat + rnorm(n, 0, 5)
dat <- data.frame(y, treat,
age, biomarker,
severity = factor(severity),
sex = factor(sex))
まず、交絡を無視した素朴な群間差を見てみます。
# 素朴な群間差(交絡調整なし)
coef(lm(y ~ treat, data = dat))["treat"]
> treat
> -1.72
真のATEは \(-5\) なのに、素朴な群間差は \(-1.72\) と大きく過小評価されています。これは「重症・高齢の患者ほど処置を受けやすく、かつアウトカムの値も高い」という正の交絡が、処置の効果(値を下げる方向)を打ち消しているためです。交絡調整の必要性がはっきり表れています。
重みの計算とバランス診断
WeightItパッケージのweightit()で、傾向スコアを推定しATE用の重みを計算します。
W <- weightit(treat ~ age + biomarker + severity + sex,
data = dat, method = "ps", estimand = "ATE",
stabilize = TRUE) # 安定化重み
W
> A weightit object
> - method: "ps" (propensity score weighting)
> - number of obs.: 2000
> - sampling weights: none
> - treatment: 2-category
> - estimand: ATE
> - covariates: age, biomarker, severity, sex
重み付け前後で共変量がそろったか(バランス)を、cobaltのbal.tab()で標準化平均差(SMD)を用いて確認します。SMDの絶対値が0.1未満であればバランス良好と判断するのが一般的な目安です。
bal.tab(W, un = TRUE, thresholds = c(m = 0.1))
> Balance Measures
> Type Diff.Un Diff.Adj M.Threshold
> prop.score Distance 0.612 0.021
> age Contin. 0.398 0.014 Balanced, <0.1
> biomarker Contin. 0.351 0.009 Balanced, <0.1
> severity_1 Binary 0.402 0.006 Balanced, <0.1
> sex_1 Binary 0.033 0.008 Balanced, <0.1
>
> Effective sample sizes
> Control Treated
> Unadjusted 1123. 877.
> Adjusted 986.2 742.5
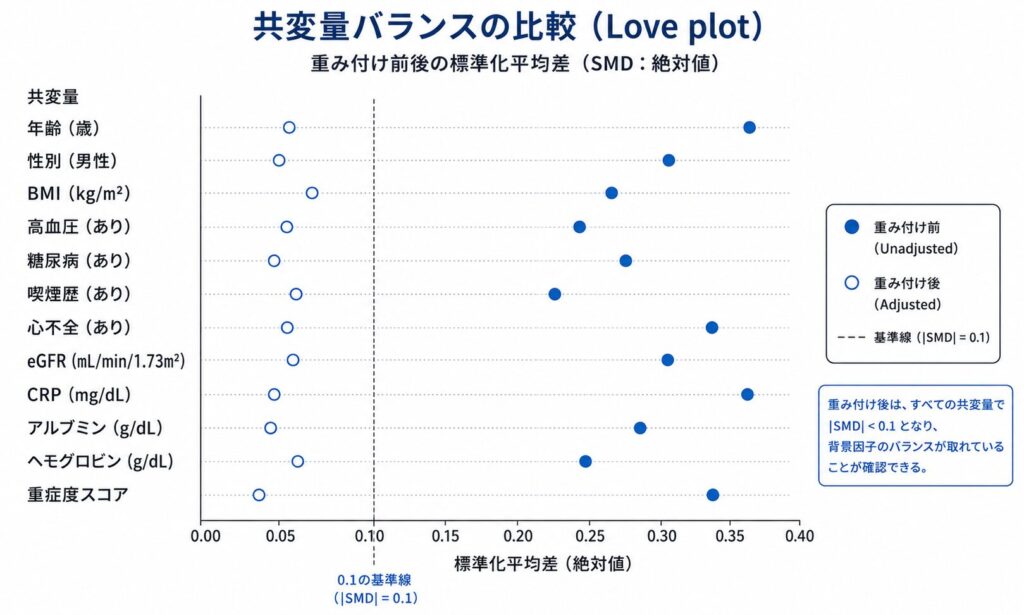
重み付け前は年齢(0.398)・検査値(0.351)・重症度(0.402)のSMDが0.1を大きく超えていましたが、重み付け後はすべて0.02未満に収まり、群間の背景がそろったことが確認できます。あわせて有効サンプルサイズ(ESS)が処置群877→742.5、対照群1123→986.2へと減少しており、重み付けが「実効的な情報量」をいくらか消費していることも読み取れます。
バランスを視覚的に確認するにはLove plot(SMDの前後比較図)が便利です。
love.plot(W, thresholds = c(m = 0.1), abs = TRUE,
var.order = "unadjusted",
title = "重み付け前後の共変量バランス")
ATEの推定
バランスが確認できたら、重みを使った回帰でATEを推定します。IPTWでは重みによって観測が独立でなくなるため、標準誤差はサンドイッチ推定量(ロバスト分散)で求めるのが原則です。surveyパッケージを使うと、この頑健な標準誤差が自動的に得られます。
design <- svydesign(ids = ~1, weights = ~W$weights, data = dat)
fit <- svyglm(y ~ treat, design = design)
summary(fit)$coefficients["treat", ]
confint(fit)["treat", ]
> Estimate Std. Error t value Pr(>|t|)
> -4.87 0.31 -15.71 2.1e-52
> 2.5 % 97.5 %
> -5.48 -4.26
IPTWによるATE推定値は \(-4.87\)(95%信頼区間 \(-5.48\) ~ \(-4.26\))となり、真の値 \(-5\) をほぼ正確に回収できています。素朴な群間差 \(-1.72\) と比べると、交絡調整の効果は歴然です。信頼区間が真値を含んでいることからも、傾向スコアモデルが妥当であれば、IPTWが偏りの小さい推定を与えることが確認できます。
共変量バランスと重みの診断 ― IPTWの品質を担保する
IPTWは「重みを計算して終わり」ではありません。得られた推定を信頼するには、重みそのものの妥当性と交絡調整の達成度を診断する必要があります。実務で必ず確認したい3つの観点を整理します。
| 診断項目 | 確認すること | 目安・対処 |
|---|---|---|
| 共変量バランス(SMD) | 重み付け後に群間の共変量がそろったか | |SMD| < 0.1 を目安。超える場合はモデルに交互作用・非線形項を追加 |
| 正値性・重みの分布 | 極端に大きい重みや傾向スコアの偏りがないか | 重み最大値・分布を確認。1・99パーセンタイルでトリミング |
| 有効サンプルサイズ(ESS) | 重み付けで実効情報量がどれだけ減ったか | 元のnから大きく減る場合は検出力低下に注意 |
重みの分布と正値性は、傾向スコアのヒストグラムと重みの要約統計量で確認します。
# 重みの要約と極端な重みの確認
summary(W$weights)
# 傾向スコアの重なり(common support)を可視化
bal.plot(W, var.name = "prop.score", which = "both",
type = "density")
> Min. 1st Qu. Median Mean 3rd Qu. Max.
> 0.5041 0.7712 0.9187 1.0000 1.1409 6.8330
上の例では最大重みが6.83と、平均1に対してかなり大きい個体が存在します。傾向スコアが0.05未満または0.95超の個体が多い場合、ATE推定は不安定になります。対処としては、①重みを1・99パーセンタイルでトリミング(打ち切り)する、②共通サポート外の個体を除外する、③推定対象をATTに切り替える、といった選択肢があります。いずれの場合も、対象集団の定義が変わる点を報告書に明記することが重要です。
有効サンプルサイズ(ESS)は次式で定義され、重みのばらつきが大きいほど元のサンプルサイズより小さくなります。
\[\text{ESS} = \frac{\left(\sum_i w_i\right)^2}{\sum_i w_i^2}\]
ESSが元のnから大きく目減りしている場合、名目上のサンプルサイズは大きくても検出力は低下しているため、結果の解釈に注意が必要です。サンプルサイズ設計の考え方は関連記事の回帰分析と相関:因果を見抜くためにでも触れています。
SASによる実装
同じ流れをSASで実装します。製薬企業の申請業務ではSASが標準であり、IPTWもPROC LOGISTICとPROC GENMODで完結できます。
まずPROC LOGISTICで傾向スコアを推定し、各個体の予測確率を出力します。
/* 傾向スコアの推定 */
proc logistic data=dat descending;
class severity sex / param=ref;
model treat = age biomarker severity sex;
output out=ps_out p=ps;
run;
続いて、ATE用のIPTW重みと安定化重みを計算します。安定化重みの分子に用いる処置割合は、あらかじめPROC MEANSなどで算出しておきます。
/* IPTW重み(ATE)と安定化重み */
data w;
set ps_out;
p_treat = 0.44; /* 別途算出した処置群割合 P(T=1) */
if treat = 1 then w_ate = 1 / ps;
else w_ate = 1 / (1 - ps);
if treat = 1 then w_stab = p_treat / ps;
else w_stab = (1 - p_treat) / (1 - ps);
id = _n_; /* 個体を一意に識別するID */
run;
最後に、重み付き回帰でATEを推定します。IPTWではロバスト分散(サンドイッチ推定量)が必要なため、PROC GENMODのREPEATEDステートメントで個体を1クラスターとみなして頑健標準誤差を得ます。
/* 重み付き回帰でATEを推定(頑健分散) */
proc genmod data=w;
class id;
model y = treat / dist=normal link=identity;
weight w_stab;
repeated subject=id / type=ind; /* サンドイッチ分散 */
run;
WEIGHTステートメントに安定化重みを指定し、REPEATED subject=id / type=indで頑健分散を求める点がポイントです。これにより、重み付けによって生じる分散の過小評価を防げます。バランス診断(SMD)はSAS側でもPROC MEANSや%stddiff系マクロで算出でき、結果はRのcobaltと整合します。共変量調整の考え方は関連記事の共変量調整(ANCOVA)徹底解説も参照してください。実務でのポイント
IPTWを実務で使う際に、統計家として押さえておきたい要点を整理します。
・推定対象を先に決める:ATEかATTかを解析計画(SAP)で明確にし、estimandとして記述する
・傾向スコアモデルには「交絡因子」を入れる:アウトカムに関連する共変量を含め、操作変数(処置にのみ関連する変数)や中間変数は入れない
・バランスで評価する:モデルの当てはまり(c統計量)ではなく、重み付け後のSMDでモデルの良否を判断する
・安定化重み+トリミングを標準に:極端な重みを抑え、common supportを確認する
・頑健分散を使う:標準誤差はサンドイッチ推定量またはブートストラップで求める
・未測定交絡の感度分析:E-valueなどで結論の頑健性を評価し、報告する
とくに製薬・RWEの文脈では、規制当局への説明可能性が重視されます。傾向スコアモデルに含めた変数の根拠、バランスの達成状況、共通サポートの範囲、感度分析の結果までを一貫して文書化することが、解析の信頼性を担保します。IPTWは単独の手法ではなく、傾向スコアマッチングや外部対照との比較など、RWE解析全体の設計のなかで位置づけて使うことが望ましいといえます。RWE全体の枠組みは関連記事のリアルワールドエビデンス(RWE)入門や、外部対照群の統計手法(傾向スコアマッチング・MAIC)で整理しています。
よくある質問(FAQ)
Q1. IPTWとマッチングはどう使い分ければよいですか?
マッチングは共通サポート内の個体だけを対にして群をそろえる(ATTに向く)のに対し、IPTWは全個体に重みを与えて活用します(ATE・ATTの両方に対応)。サンプルを無駄にしたくない、集団全体への効果(ATE)を知りたい場合はIPTWが向きます。両者は排他ではなく、感度分析として併用し結果の一致を確認することが推奨されます。
Q2. 安定化重みは必ず使うべきですか?
点推定値はHT重みでも安定化重みでも同じATEを推定しますが、安定化重みは分散を小さくし数値的安定性を高めます。とくに傾向スコアが極端になりやすいデータでは安定化重みを標準的に用いるのが安全です。
Q3. 傾向スコアモデルには何を入れればよいですか?
アウトカムに関連する交絡因子を優先的に含めます。処置にのみ関連しアウトカムには無関係な変数(操作変数)を入れると分散だけが増え、処置とアウトカムの間にある中間変数(媒介変数)を入れると効果の一部を消してしまうため、いずれも避けます。
Q4. 重みが極端に大きい個体はどう扱いますか?
まず傾向スコアの重なり(common support)を確認します。少数の外れ値であれば1・99パーセンタイルでのトリミングが有効です。多数存在する場合は正値性が疑わしいため、対象集団を絞る、ATTに切り替える、といった対応を検討します。
Q5. なぜロバスト分散が必要なのですか?
重み付き回帰では観測が独立でなくなり、通常の分散推定は標準誤差を過小評価します。サンドイッチ推定量(頑健分散)やブートストラップを用いることで、重み付けを考慮した妥当な信頼区間が得られます。
📚 この記事をより深く理解するための参考書籍
因果推論・傾向スコア分析をさらに深く学びたい方に、おすすめの書籍をご紹介します。






関連記事・次のステップ
IPTWは傾向スコア分析・因果推論の一部です。以下の関連記事とあわせて読むことで、観察研究の交絡調整を体系的に理解できます。
- 傾向スコア分析(Propensity Score Analysis)とは:マッチング・層別化・IPTWを含む傾向スコア全体の基礎
- 共変量調整(ANCOVA)徹底解説:ベースライン共変量調整のもう一つの王道アプローチ
- 外部対照群の統計手法(傾向スコアマッチング・MAIC・ベイズ動的借用):外部対照を用いる場面での重み付け・マッチングの応用
- リアルワールドエビデンス(RWE)入門:IPTWが活躍するRWE解析全体の枠組み
- Target Trial Emulation(TTE)とは:観察データで仮想的なRCTを再現する設計思想
まとめ
本記事では、逆確率重み付け(IPTW)による平均処置効果(ATE)の推定を、擬似集団による直感的な理解から、Horvitz-Thompson推定量・安定化重み・二重ロバスト推定という数理的背景、RのWeightIt/cobalt・survey、およびSASによる実装、そして共変量バランス(SMD)・有効サンプルサイズ・重みのトリミングといった診断まで、一貫して解説しました。
シミュレーションでは、真のATE \(-5\) に対して素朴な群間差が \(-1.72\) と大きく偏る一方、IPTWは \(-4.87\)(95%信頼区間 \(-5.48\) ~ \(-4.26\))とほぼ正確に回収できることを確認しました。IPTWの強みは全サンプルを活用して集団全体の効果を推定できる点にありますが、その妥当性は正値性・条件付き交換可能性という検証しきれない前提に支えられています。だからこそ、バランス診断・common supportの確認・頑健分散・感度分析をセットで運用することが、実務における信頼性の鍵になります。
観察研究・リアルワールドデータの重要性が高まるなか、IPTWを正しく使いこなす力は、製薬・医学領域の生物統計家にとって大きな強みになります。まずは傾向スコア分析の基礎を固めたうえで、本記事のコードを手元で動かし、バランス診断まで一通り再現してみていただければと思います。