Rで学ぶ反復測定ANOVA ― afexパッケージで球面性検定からGreenhouse-Geisser補正まで実装する ―

この記事でわかること
- 反復測定ANOVAがどんな試験デザインに使える解析手法か
- 被験者内要因と被験者間要因の違い、何が「反復」かの整理
- 古典的反復測定ANOVAとMMRMがどう違うか、なぜ両方学ぶ価値があるか
- Rのafexパッケージで動かす全体像
反復測定ANOVAとは何か
臨床試験や薬理試験の現場では、同じ被験者から複数時点でアウトカムを繰り返し測定するデザインが日常的に登場します。降圧薬の投与後0・2・4・8時間の血圧推移、抗うつ薬投与下でのHAM-Dスコアを4週ごとに評価する試験、あるいは3種類の鎮痛薬をクロスオーバーで投与し各条件下での疼痛VASを比較する試験などが典型例です。こうした反復測定(経時測定)デザインのデータを、群間差や時点間差として正しく検定するための古典的な枠組みが、反復測定ANOVA(repeated measures ANOVA)です。
反復測定ANOVAを理解する出発点は、要因を2種類に区別することです。1人の被験者の中で水準が変わる要因を被験者内要因(within-subject factor)、被験者ごとに水準が固定される要因を被験者間要因(between-subject factor)と呼びます。両者の違いを下表に整理しました。
| 観点 | 被験者内要因 | 被験者間要因 |
|---|---|---|
| 水準の変動 | 同一被験者の中で変化する | 被験者ごとに固定される |
| 代表例 | 測定時点、クロスオーバー条件 | 投与群、性別、年齢層 |
| 誤差構造 | 同一被験者内で相関あり | 独立と仮定できる |
| 検出力への寄与 | 個人差を分離して高めやすい | サンプルサイズ次第 |
ここで素朴な疑問として、「すべての観測値を独立データと見なして普通のone-way ANOVAに流し込んでもよいのでは」と考えたくなります。しかしこのアプローチは2つの意味で破綻します。第一に、同じ被験者から得られた測定値は相関しており、ANOVAが前提とする独立性の仮定を満たしません。第二に、被験者ごとのベースライン差(個人差)を誤差項に押し込んでしまうため、本来検出できるはずの効果を見逃す、つまり検出力を捨てている状態になります。反復測定ANOVAは被験者内変動を分離して扱うことで、この2つの問題を同時に解決します。
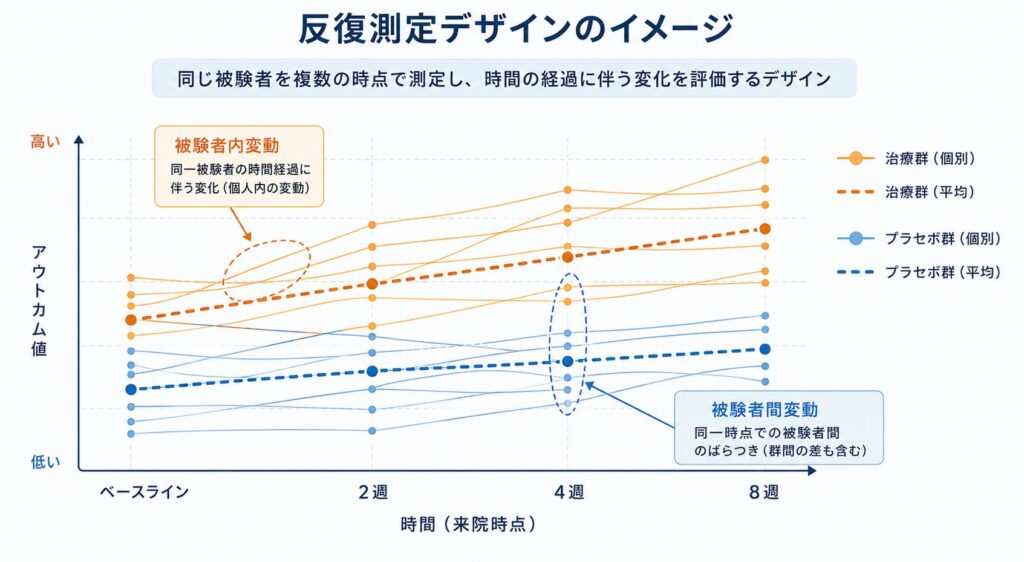
イメージを掴むために、下図で被験者ごとの軌跡を視覚的に確認してみましょう。各被験者がどのような経時パターンを描き、群全体の平均挙動とどう重なり合うのかが、データ構造を理解する第一歩となります。次の節では、なぜこの設計に専用の検定統計量が必要なのか、その数理的背景に踏み込んでいきます。
数理:分散分解とF統計量、球面性仮定
反復測定ANOVAを理解するうえで最初の鍵となるのは、全体のばらつきをどのように分解するかという発想です。通常の一元配置ANOVAでは「被験者間」のばらつきしか扱いませんが、反復測定デザインでは同一被験者から複数の観測値が得られるため、ばらつきを被験者間(between-subjects)と被験者内(within-subjects)に切り分けます。
基本となる分散分解式は次のとおりです。
\[ SS_{total} = SS_{between} + SS_{within} \]
さらに被験者内成分は、条件(時点)の効果と残差に分解されます。
\[ SS_{within} = SS_{treatment} + SS_{error} \]
F統計量は、条件の効果に対応する平均平方を、被験者内の残差平均平方で割った比として定義されます。
\[ F = \frac{MS_{treatment}}{MS_{error}} = \frac{SS_{treatment}/(k-1)}{SS_{error}/((n-1)(k-1))} \]
ここで \( n \) は被験者数、\( k \) は条件(時点)数です。自由度は条件側が \( k-1 \)、誤差側が \( (n-1)(k-1) \) となり、F分布 \( F_{k-1,\,(n-1)(k-1)} \) を用いて検定します。
| 要因 | 自由度 (df) | 平方和 (SS) | 平均平方 (MS) | F値 |
|---|---|---|---|---|
| 被験者間 | \( n-1 \) | \( SS_{between} \) | — | — |
| 被験者内:条件 | \( k-1 \) | \( SS_{treatment} \) | \( MS_{treatment} \) | \( MS_{treatment}/MS_{error} \) |
| 被験者内:誤差 | \( (n-1)(k-1) \) | \( SS_{error} \) | \( MS_{error} \) | — |
| 全体 | \( nk-1 \) | \( SS_{total} \) | — | — |
なぜ被験者内要因では誤差項が変わるのか
通常のANOVAと異なり、反復測定では被験者そのものを一種の「ブロック」と見なし、ランダム効果として吸収します。同じ被験者から得られた観測値は本来高く相関しますが、被験者効果を分散分解の中で取り除くことで、条件間の差を「個体内の純粋な変動」と比較できるようになります。結果として誤差項 \( MS_{error} \) は被験者間の個人差を含まず小さくなり、検出力が向上します。これは臨床試験のクロスオーバーデザインで個体内比較が好まれる理由と同じ発想です。
球面性(Sphericity)という仮定
反復測定ANOVAのF検定が妥当であるためには、球面性(Sphericity)と呼ばれる仮定が必要です。これは「すべての時点ペアの差の分散が等しい」という条件、すなわち \( \mathrm{Var}(Y_i – Y_j) \) が任意の \( i \neq j \) で一定であることを意味します。球面性は共分散構造のCompound Symmetry(CS)よりやや緩い条件で、いわば「差スコアに関する一般化された等分散性」と捉えられます。
この仮定が破れると、F統計量の分布が理論上のF分布から外れ、第一種過誤が名目水準 \( \alpha \) より膨らむことが知られています。特に時点が増えるほど球面性は崩れやすく、長期追跡データでは注意が必要です。そこで実務ではMauchlyの球面性検定で仮定を確認し、必要に応じてGreenhouse-Geisserなどの自由度補正を適用します。
では次節で、実際にRのafexパッケージを用いてこの分散分解と球面性検定を動かしてみましょう。
Rでの実装:afexパッケージで反復測定ANOVAを実行する
ここでは afex パッケージを用いて、被験者間要因(群)と被験者内要因(時点)が混在する混合計画の反復測定ANOVAを実装します。afexは内部で car::Anova() を呼び出してType III平方和を既定で計算し、球面性検定や補正もまとめて返してくれるため、製薬領域の解析で広く使われています。前処理は tidyverse、事後検定は emmeans を組み合わせるのが定番の構成です。
データ準備
3群(プラセボ/低用量/高用量)×4時点(baseline, week2, week4, week8)の被験者間×被験者内の混合計画を想定し、各群10例・合計N=30の仮想データを生成します。被験者ごとのランダム効果も加味し、用量依存的な経時変化を持たせています。
library(afex)
library(tidyverse)
library(emmeans)
set.seed(2025)
n_per_group <- 10
subjects <- 1:(n_per_group * 3)
dat <- expand_grid(
subject = subjects,
time = c("baseline","week2","week4","week8")
) %>%
mutate(
group = case_when(
subject <= 10 ~ "placebo",
subject <= 20 ~ "low",
TRUE ~ "high"
),
time_num = case_when(
time == "baseline" ~ 0,
time == "week2" ~ 2,
time == "week4" ~ 4,
time == "week8" ~ 8
),
value = 100
+ ifelse(group == "low", -2 * time_num, 0)
+ ifelse(group == "high", -4 * time_num, 0)
+ rnorm(n(), 0, 5)
+ rnorm(length(subject), 0, 8)[match(subject, subjects)]
) %>%
mutate(
subject = factor(subject),
group = factor(group, levels = c("placebo","low","high")),
time = factor(time, levels = c("baseline","week2","week4","week8"))
)
反復測定ANOVAでは、被験者ID・群・時点をすべて factor 化しておくことが重要です。文字列のままだと afex が警告を出したり、対比の順序が意図と異なる挙動を示すことがあります。
afex::aov_ez() の実行
データがロング形式に整っていれば、aov_ez() 一発で混合計画のANOVA表が得られます。引数は被験者ID、従属変数、被験者間要因、被験者内要因を文字列で指定するだけで、可読性が高いのが特長です。
fit_rm <- aov_ez(
id = "subject",
dv = "value",
data = dat,
between = "group",
within = "time"
)
summary(fit_rm)
結果の読み方
出力は以下のような形式で返されます(数値はイメージです)。
Anova Table (Type 3 tests)
Response: value
num Df den Df MSE F ges Pr(>F)
group 2 27 150.32 8.41 0.215 0.00142 **
time 3 81 45.67 32.18 0.408 < 2e-16 ***
group:time 6 81 45.67 9.05 0.225 3.4e-08 ***
各列の意味は次のとおりです。
- num Df:分子自由度。要因の水準数−1に対応します。
- den Df:分母自由度。被験者内要因では (水準数−1) × (被験者数−群数) などで決まります。
- MSE:誤差平均平方。F検定の分母に使われる残差分散です。
- F:F値。要因平均平方をMSEで割った検定統計量です。
- ges:一般化イータ二乗(generalized eta-squared)。デザインに依存しにくく、反復測定ANOVAでは partial η² よりgesが推奨 される効果量です(Bakeman, 2005)。
- Pr(>F):F分布から計算したp値。
上記の例では、group:time 交互作用が有意(p < 0.001, ges = 0.225)であり、用量によって経時変化のパターンが異なることが示唆されます。臨床試験の文脈では、この交互作用こそが「用量反応性を伴う薬効」を支持する一次的な証拠になります。
ここまでで球面性を前提とした検定が動きました。だが現実のデータではこの仮定が破れることが多く、そのまま読むとp値が過小評価される危険があります。次節ではMauchlyの球面性検定と、Greenhouse-Geisser・Huynh-Feldtによる自由度補正に進みます。
球面性違反への対処:Mauchly検定と補正法
反復測定ANOVAの妥当性を支える球面性の仮定とは、時点の全ペアにおける差の分散が等しい、という条件です。形式的には共分散構造に対する制約であり、この仮定が破れるとF統計量の分布が理論値からずれ、Type I errorが膨らみます。臨床試験のように時点が経過するにつれて測定値間の相関が変化するデータでは、球面性は破れやすいと考えるのが実務的に妥当です。
球面性を統計的に検証する手段がMauchly検定です。帰無仮説H0は「球面性が成立する」であり、p値が小さいときに球面性違反を疑います。afex::aov_ez()の出力では Mauchly Tests for Sphericity セクションに、要因ごとの検定統計量W、p値、そして補正に用いる\(\hat\varepsilon\)の推定値(GG・HF)が表示されます。具体的には、p値が0.05を下回れば球面性違反と判断する、というのが教科書的な解釈です。
ただし実務上は、Mauchly検定が検出力の低い検定である点に注意が必要です。サンプルサイズが小さい第I相・第II相試験のような状況では、真に球面性が破れていてもp>0.05となる場面が珍しくありません。このため、N=20前後の探索的試験では「Mauchly検定が有意でなくても、念のため補正をかける」というスタンスが推奨されます。下図のように球面性が破れると、検定の自由度を縮めて補正する必要が出てきます。
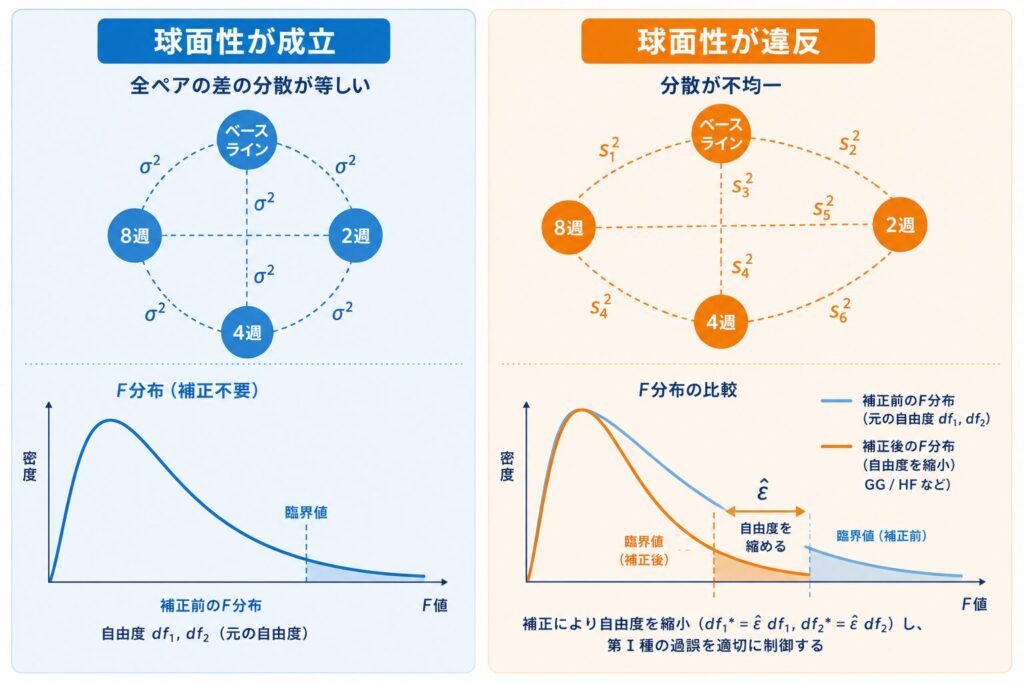
代表的な補正法は2つです。Greenhouse-Geisser補正(GG)は\(\hat\varepsilon_{GG}\)で自由度を縮める保守的な方法で、安全側に倒したいときに選びます。一方Huynh-Feldt補正(HF)は\(\hat\varepsilon_{HF}\)を用い、GGよりやや緩く、検出力を残したいときに有用です。使い分けの目安を下表にまとめます。
| 補正法 | 推奨条件 | 長所 | 短所 |
|---|---|---|---|
| Greenhouse-Geisser | \(\hat\varepsilon<0.75\)のとき推奨 | 保守的で安全、Type I error制御に強い | 検出力が低下しやすい |
| Huynh-Feldt | \(\hat\varepsilon\geq 0.75\)のとき推奨 | 検出力を維持しやすい | 違反が強いと補正不足のリスク |
| 補正なし | 球面性が成立しているとき | 元の検定統計量がそのまま使える | 違反時にType I errorが膨らむ |
afex::aov_ez()の出力では Sphericity Corrections セクションにGG・HF両方の調整後p値が並びます。読み方の手順としては、まず\(\hat\varepsilon\)の推定値を確認し、0.75を境にGGかHFを選び、対応する Pr(>F[GG]) あるいは Pr(>F[HF]) を最終的な有意性判断に用います。報告書では「どちらの補正を採用したか」と「\(\hat\varepsilon\)の値」を必ず明記するのが実務上の作法です。
もっとも、球面性違反が厳しいケースや欠測がある場合は、反復測定ANOVAそのものを諦めてMMRMに切り替える判断が要ります。次節で両者の使い分けをまとめます。
MMRMとの使い分け:実務での選択フロー
反復測定ANOVAを習得した次に気になるのは、「実務(特に検証的臨床試験)で使われているMMRMとどう違うのか」という点かと存じます。両者の位置づけを整理しておきましょう。
| 観点 | 反復測定ANOVA | MMRM |
|---|---|---|
| 共分散構造 | Compound Symmetry前提+球面性補正 | UN, AR(1), Toeplitzなど柔軟に指定可能 |
| 欠測の扱い | 完全データ前提(欠測者は被験者単位で除外) | MAR仮定の下で全データを活用 |
| 実装 | afex::aov_ez() | mmrm::mmrm() / SAS PROC MIXED |
| 推奨用途 | 教育用途・小規模実験・balanced設計 | 検証的臨床試験の経時データ解析 |
| 規制対応 | 原則として申請解析では使われない | FDA・PMDAでも推奨される標準手法 |
実務での判断フロー
- ステップ1:欠測がある、または共分散構造の柔軟な指定が必要 → MMRMを選択
- ステップ2:完全balancedデータで教育的・探索的な解析が目的 → 反復測定ANOVA+GG補正で十分
- ステップ3:球面性違反が著しく被験者数も少ない → Friedman検定などノンパラメトリック手法も検討
📚 より深く学ぶなら
反復測定ANOVAは「MMRMの古典版」と理解すると見通しが良くなります。記事末尾に紹介する書籍では混合モデル全体の枠組みから学べます。
まとめ
本記事では、Rのafexパッケージを用いて反復測定ANOVAを実装する流れを解説いたしました。要点を以下に整理いたします。
- 球面性の仮定は反復測定ANOVAの妥当性を支える前提であり、Mauchly検定で確認することが必須です。
- 球面性が棄却された場合はGreenhouse-Geisser補正(保守的)またはHuynh-Feldt補正を適用し、自由度を調整します。
afex::aov_ez()を使えば、被験者内要因の指定・球面性検定・補正p値の算出までを一括で実行でき、出力も解釈しやすい形式に整っています。- 欠測のある経時データや柔軟な共分散構造が必要な場面では、MMRMへ自然に発展させて考えることができます。
関連記事・次のステップ
- mmrmをRで実装する ― CRANの mmrm パッケージで反復測定混合モデルを動かす ―
反復測定ANOVAから一歩進めて、欠測がある経時データを正面から扱う標準手法をRで実装する記事です。 - mmrmをSASで実装する (2/2)
申請業務で標準的に用いられるSAS PROC MIXEDによるMMRM実装を、Rとの対応関係を意識しながら学べます。 - MMRM(反復測定混合モデル)と多重代入法の組み合わせ解析
欠測メカニズムがMARから外れる懸念がある場合に、MMRMと多重代入法を組み合わせる感度分析の実務的アプローチを解説しています。
最後までお読みいただきありがとうございました。