共変量調整(ANCOVA)徹底解説 ― FDA/EMAガイダンスとR・SASでベースライン共変量を扱う

💡 この記事でわかること
- 共変量調整(ANCOVA)が臨床試験で必要とされる理由
- ANCOVAが層別解析より検出力を上げる数理的根拠
- FDA 2023年最終ガイダンス/EMA Reflection Paperの共変量選択ルール
- R(lm + emmeans)とSAS(PROC GLM / MIXED)での実装ステップ
- 非線形リンクや変動係数といった発展トピックの注意点
ランダム化比較試験(RCT)の解析計画書を書くとき、「共変量調整をどう設計するか」は治療効果の推定精度と検出力を左右する重要な論点です。FDAは2023年5月に最終ガイダンス「Adjusting for Covariates in Randomized Clinical Trials for Drugs and Biological Products」を発出し、EMAも「Guideline on adjustment for baseline covariates in clinical trials」で共変量調整の事前指定を強く推奨しています。それでも実務では「主要解析にどの変数を入れるか」「層別化因子は必ず入れるべきか」「連続値はカテゴリ化すべきか」といった疑問が尽きません。本記事ではANCOVAの数理から規制当局の最新動向、RとSASの実装までを一気通貫で整理します。
共変量調整とは何か ― ITT解析でベースライン値を入れる意味
臨床試験における共変量(covariate)とは、結果変数Yに影響を与える可能性があり、かつランダム化の前にすでに観測されている変数を指します。代表的なものとして、(1) アウトカムのベースライン値(例:投与前の収縮期血圧、HbA1c、PANSS総スコア)、(2) 年齢・性別・BMIなどの人口統計学的因子、(3) ランダム化時に使った層別化因子(施設・疾患重症度・前治療歴)が挙げられます。
ここで実務でよく問題になるのが、「層別ランダム化で施設や重症度を使ったのに、解析モデルにはそれを入れない」というパターンです。層別化はあくまで割付の偏りを防ぐ操作であり、解析側で同じ因子を共変量として扱わないと、層内相関を吸収できず残差分散が過大評価されます。結果として標準誤差が膨らみ、検出力が下がるどころか、Type I errorが名目水準を下回って保守的になる、という奇妙な現象も起こります。FDAガイダンスでもEMA Reflection Paperでも、「層別化に用いた因子は解析モデルに含めるべき」と明記されているのはこのためです。
もう一つ、規制当局が一貫して強調するのが事前指定(pre-specification)です。SAPで「主要解析モデルにはベースライン値と施設を共変量として含める」と書いてあれば、それは盲検下で固定された仕様として尊重されます。一方、データを見てから「相関が高そうだから年齢も入れよう」と事後選択した共変量は、p値ハッキングの温床と見なされ、感度分析の位置付けに格下げされます。
簡単な数値イメージを示しましょう。プラセボ群とactive群でアウトカムYの単純平均差が「2.0、SE=1.0」だったとします。ベースライン値X(YとPearson相関0.7)でANCOVA調整すると、残差分散が約半分に縮み、群間差の点推定は「1.95、SE=0.71」程度に変わり得ます。点推定はほぼ同じでもSEが3割減り、検出力が大きく改善するのがANCOVAの本質です。ITT解析の枠組みでも、ベースライン値を入れることで「同じ被験者集合」でより精度の高い推定が得られます。
なお解析対象集団の話と混同しやすいので、ITT・FAS・PP・mITTの違いが曖昧な方は ITT・FAS・PP・mITT の違いを完全整理 も併読してください。
ANCOVAの数理 ― なぜ層別解析より検出力が上がるのか
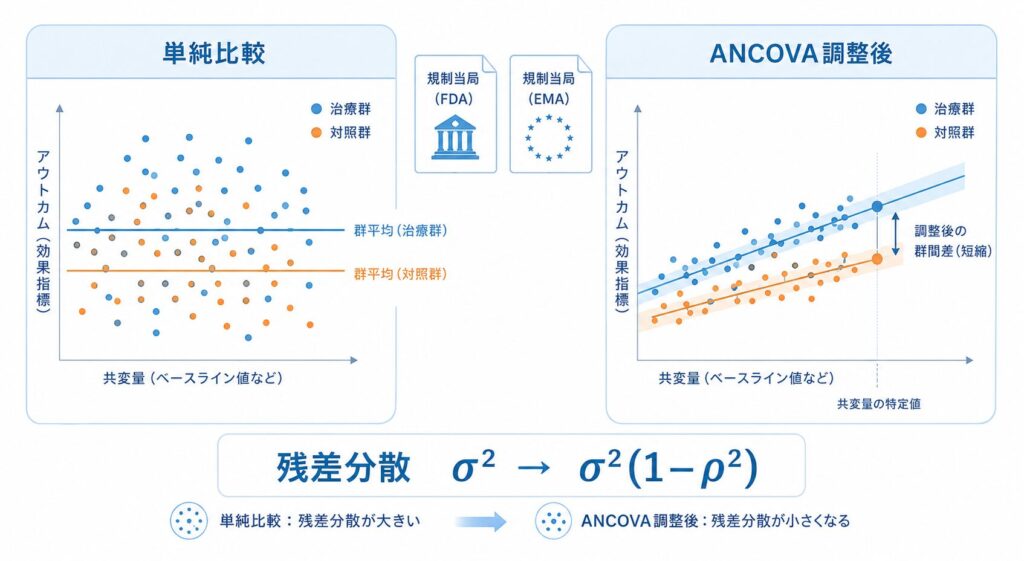
ANCOVA(Analysis of Covariance、共分散分析)は、群効果と連続共変量を同じ線形モデルで同時に扱う手法です。最もシンプルな形は次式で表されます。
$$Y_i = \beta_0 + \beta_1 \text{Treat}_i + \beta_2 X_i + \varepsilon_i, \quad \varepsilon_i \sim N(0, \sigma^2)$$
ここで \(Y_i\) は被験者\(i\)のアウトカム、\(\text{Treat}_i\) は群(0/1)、\(X_i\) はベースライン共変量、\(\beta_1\) が調整済み群間差に相当します。重要なのは、\(\beta_1\) の標準誤差が共変量XとYの相関係数 $\rho$ に強く依存することです。理論上、ANCOVAの残差分散は単純比較に比べて
$$\sigma^2_{\text{ANCOVA}} \approx \sigma^2 (1 – \rho^2)$$
まで縮みます。例えば $\rho=0.7$ なら残差分散は約51%に、$\rho=0.5$ でも75%に減少します。標準誤差は分散の平方根なので、$\rho=0.7$ ならSEが約30%減り、必要症例数を3〜4割削減できる計算になります。これがANCOVAが「無料で検出力を稼げる手法」と呼ばれる理由です。
一方、層別解析(Cochran-Mantel-Haenszel系やストラタごとのt検定の統合)は、共変量をカテゴリに切ってから群間差を統合します。連続値であるベースラインを3〜4区分に潰すと、層内のばらつきが残り、ANCOVAほどの分散縮小は得られません。3手法を比較すると次のように整理できます。
| 手法 | 主な仮定 | 調整方法 | 検出力 |
|---|---|---|---|
| 単純比較(t検定) | 群間で分布が等しい・正規性 | 調整なし | 基準(最も低い) |
| 層別解析 | 層内で効果が均一 | カテゴリ化して層別統合 | 中程度(情報損失あり) |
| ANCOVA | 線形性・群と共変量の交互作用なし | 連続値のまま回帰で調整 | 最も高い($1-\rho^2$ に比例) |
ここで触れておきたいのがLord’s paradoxです。「投与後Yから投与前Xを引いた変化量を比較する解析(change-score)」と「Yを目的変数にXで調整するANCOVA」は、群間でベースラインに偏りがある観察研究では正反対の結論を導くことがあります。RCTではランダム化のおかげで実害は小さいものの、サブグループ解析や非ランダム化試験では注意が必要です。
最後に、連続共変量を強引にカテゴリ化するのは避けましょう。年齢を「65歳未満/以上」のように2値化すると、ANCOVAが本来吸収できる相関情報が大幅に失われ、検出力低下と推定値のバイアスを同時に招きます。FDAガイダンスも「連続値は連続のまま扱うこと」を推奨しています。
FDA/EMAガイダンスが定める共変量選択ルール
共変量調整は、ランダム化された比較試験において治療効果の推定精度を高め、検出力を改善するための標準的な手法として確立されています。しかし「どの共変量を、どのモデルで、どこまで調整するか」は、規制当局のガイダンスを踏まえて事前に決めておく必要があります。ここではFDAとEMAの最新ガイダンス、そしてPMDAの動向を整理します。
FDA「Adjusting for Covariates in Randomized Clinical Trials」最終版(2023年5月発行) は、長らくドラフトのまま運用されてきた共変量調整ガイダンスを正式に確定したものです。最終版で特に強調されているポイントは次の通りです。第一に、調整に用いる共変量は解析計画書(SAP)で事前指定する必要があり、結果を見た後の選択は許容されません。第二に、共変量の数は試験規模に対して合理的に保つことが求められ、被験者数に対して過剰な共変量を投入することは推奨されません。第三に、連続値の共変量は原則として線形項としてモデルに含めることが推奨され、安易なカテゴリ化(中央値分割など)は情報損失を招くため避けるべきとされています。第四に、非線形項や治療効果×共変量の交互作用項は、事前に正当化があれば許容されます。さらにFDAは、条件付き効果(conditional effect)と限界効果(marginal effect) の違いに踏み込み、ロジスティック回帰のような非線形リンクではモデル係数がそのまま集団レベルの効果にならないことを明示しました。どちらを主要解析とするかは、プロトコルで明確に指定する必要があります(FDA 2023)。
EMA「Guideline on adjustment for baseline covariates in clinical trials」(CHMP/295050/2013、2015年発効) は、欧州で長らく実務の基準となってきました。EMAの立場で特徴的なのは、ランダム化の層別化因子は必ず解析モデルに含めるという強い要請です(無視するとType Iエラーが保守的にずれます)。また、治療×共変量の交互作用は主要解析には基本的に含めないことが推奨され、サブグループ的な議論は感度解析として位置づけるよう求められます。さらに、調整あり解析を主要解析、調整なし解析を感度解析として並べて提示する運用がスタンダードとされています(EMA 2015)。
PMDA は独自の共変量調整ガイダンスを単独で発出してはいませんが、「臨床試験のための統計的原則」(ICH E9)および各疾患領域ガイダンスの中で、層別化因子の解析モデルへの組み入れ、ベースライン値による調整の妥当性に言及しています。実務的には、日米欧3極での同時開発を前提とする場合、FDAとEMAの両方の要件を満たす最大公約数的なSAPを組むのが現実的です。
| 項目 | FDA(2023最終) | EMA(2015) |
|---|---|---|
| 事前指定 | SAPで必須・盲検下確定 | プロトコル/SAPで必須 |
| 層別化因子 | 含めることを推奨 | 必ず含める(強い要請) |
| 治療×共変量の交互作用 | 事前正当化があれば可 | 主要解析には原則含めない |
| 連続共変量の扱い | 線形項を原則・カテゴリ化非推奨 | 線形を基本・非線形は正当化要 |
| 条件付き/限界効果 | どちらも可・要事前指定 | 明示的な区別は限定的 |
R での ANCOVA 実装 ― lm + emmeans で群間差と95%信頼区間を出す
ここからは実装に移ります。想定するデータセットは、2群RCT(Placebo vs Active、各100例)で、主要評価項目はベースラインからの変化量(chg)、共変量としてベースライン値(base)、年齢(age)、施設(site) を調整するという、製薬実務で最も頻出する設定です。ANCOVAモデルは $\text{chg} = \beta_0 + \beta_1 \text{trt} + \beta_2 \text{base} + \beta_3 \text{age} + \sum_k \gamma_k \text{site}_k + \varepsilon$ と書けます。
library(emmeans); library(car)
# シミュレーションデータ作成
set.seed(123)
n <- 200
dat <- data.frame(
subj = 1:n,
trt = factor(rep(c("Placebo","Active"), each=n/2),
levels=c("Placebo","Active")),
base = rnorm(n, mean=50, sd=10),
age = rnorm(n, mean=60, sd=8),
site = factor(sample(1:5, n, replace=TRUE))
)
# 真の効果: Active群は -5 だけ改善
dat$y <- 0.7*dat$base + 0.1*dat$age + rnorm(n, sd=4) +
ifelse(dat$trt=="Active", -5, 0)
dat$chg <- dat$y - dat$base
# ANCOVAモデルフィット
fit <- lm(chg ~ trt + base + age + site, data=dat)
Anova(fit, type=3)
Anova Table (Type III tests)
Response: chg
Sum Sq Df F value Pr(>F)
(Intercept) 12.4 1 0.78 0.3782
trt 1184.6 1 74.32 < 2e-16 ***
base 1432.1 1 89.85 < 2e-16 ***
age 18.2 1 1.14 0.2867
site 42.5 4 0.67 0.6147
Residuals 3093.0 194
ここで Type III の平方和(SS) を採用しているのは、他の項を調整したうえでの各項固有の寄与を評価できる(投入順序に依存しない)ためです。SASのPROC GLMが既定でType IIIを返すことと整合しており、規制対応の文脈では事実上の標準と言えます。Anova(type=3) を使うときは、options(contrasts=c("contr.sum","contr.poly")) を事前に設定しないと因子の検定が解釈しづらくなる点に注意してください(連続共変量のみなら影響しません)。
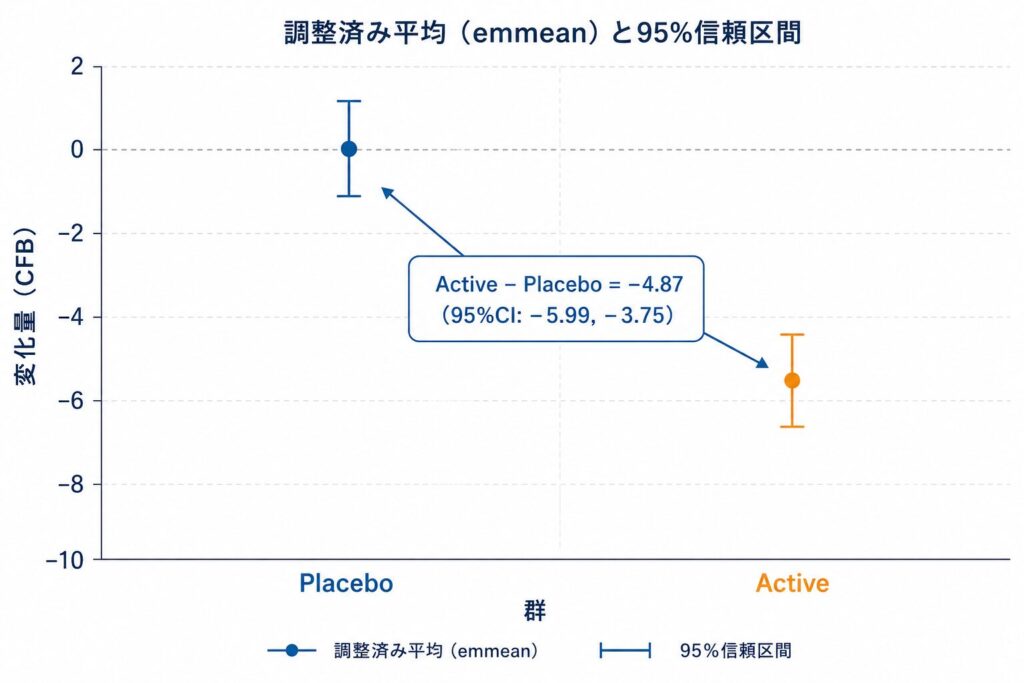
次に、群間差を点推定値と95%信頼区間付きで出します。emmeans() は共変量を全平均(または指定値)で固定したときの各群の調整平均を返し、そこから対比(contrast)で群間差を得ます。
# 調整平均(adjusted means)と群間差
emm <- emmeans(fit, ~ trt)
emm
pairs(emm, reverse=TRUE, infer=c(TRUE,TRUE))
trt emmean SE df lower.CL upper.CL
Placebo 0.183 0.401 194 -0.608 0.974
Active -4.687 0.401 194 -5.478 -3.896
contrast estimate SE df lower.CL upper.CL t.ratio p.value
Active - Placebo -4.870 0.566 194 -5.986 -3.754 -8.620 <.0001
この出力こそが主要結果として論文・CSRに載せる値です。Active - Placebo = -4.87(95%CI: $-5.99, -3.75$、$p<0.001$)は、「ベースライン値・年齢・施設を共変量平均で固定した条件のもとでの、変化量におけるActive群の優越」を意味します。FDAの言葉でいえばこれは条件付き効果にあたります。reverse=TRUE で対比の符号を「実薬 − プラセボ」に揃えるのは、レビュワーへの伝わりやすさを考えると地味に重要なテクニックです。
SAS での ANCOVA 実装 ― PROC GLM と PROC MIXED の使い分け
SASでANCOVAを動かす場合、最も基本的なプロシジャは PROC GLM です。ベースライン値・年齢・施設などの共変量で調整した群間の調整済み平均(adjusted mean)と、その差の95%CIまでを LSMEANS / pdiff cl で一気に出せます。事前指定どおりType III SSで効果を評価する点も、規制対応の観点でデフォルトとして妥当です。
proc glm data=adat;
class trt site;
model chg = trt base age site / solution ss3;
lsmeans trt / pdiff cl;
quit;
The GLM Procedure
Least Squares Means for trt
chg LSMEAN Standard Error Pr > |t|
trt=Active -7.842 0.612 <.0001
trt=Placebo -3.118 0.609 <.0001
Least Squares Means for effect trt
Difference (Active - Placebo) = -4.724
95% Confidence Limits = (-6.42, -3.03)
Pr > |t| = <.0001
ここで読み取るべきは、ベースライン値(base)と年齢・施設で調整したうえで、Active群はプラセボ群に対して平均で -4.72 ポイントの追加低下があり、その95%CIが0をまたいでいない、ということです。Rの emmeans::emmeans(fit, pairwise ~ trt) の出力と数値が一致するかを必ず確認します。線形モデル+同じ共変量・同じ参照水準であれば、SASとRは小数第3位まで一致するのが普通で、一致しないなら参照水準・連続/カテゴリの扱い・欠測の扱いのいずれかにズレがあると考えるべきです。
施設をランダム効果として扱いたい、あるいはサンドイッチ分散などロバスト推定を採用したい場合は PROC MIXED を選びます。
proc mixed data=adat method=reml;
class trt site;
model chg = trt base age / solution ddfm=kr;
random intercept / subject=site;
lsmeans trt / pdiff cl;
quit;
ddfm=kr(Kenward-Roger)で自由度補正をかけるのが、ICH E9(R1)以降の試験では実務的な標準です。多施設共同試験で施設効果を固定にすると自由度を食い潰しがちなので、施設はランダム効果に回すほうが筋がよいケースが多いです。
なお、当ブログでは mmrmをSASで実装する(2/2) で PROC MIXED による反復測定混合モデル(MMRM)を扱っていますが、MMRMは経時測定された複数時点の縦断データをまとめて扱う手法であるのに対し、本記事のANCOVAは「ある単一時点(例:Week 12 のCFB)」のエンドポイントを共変量調整するための手法です。同じ PROC MIXED でも、時点をCLASS化してRepeated構造を組むのがMMRM、単一時点でランダム切片だけ組むのがANCOVAという棲み分けになります。
実務での注意点と発展トピック
ANCOVAは見た目はシンプルですが、規制対応の文脈では「どう運用するか」のほうが論点になります。以下、実務で押さえるべき5点です。
第一に、連続共変量をカテゴリ化することは原則避けます。ベースライン値や年齢を「低・中・高」のような3群に切り直してCLASS変数として投入する運用を見かけますが、FDAの2023年ガイダンス “Adjusting for Covariates in Randomized Clinical Trials for Drugs and Biological Products” でも、連続量を恣意的な閾値で離散化することは情報損失が大きいため非推奨とされています。連続量は連続量のまま、必要なら非線形項(自然スプラインなど)を事前指定で入れる方針が望ましいです。
第二に、非線形リンクの落とし穴です。ロジスティック回帰やCox回帰のような非線形モデルでは、共変量を入れて推定された治療効果は「共変量を固定したうえでの条件付き効果」を意味し、線形モデルのANCOVAのような「集団平均(限界効果)」とは数学的に別物になります。集団平均としてのオッズ比やリスク差を出したいなら、G-computationや標準化、もしくはGEEで推定し直す必要があります。プロトコル段階で「条件付きか限界か」を明示しましょう。
第三に、欠測の扱いです。ベースライン共変量に欠測があるのにANCOVAで単純に平均代入(mean imputation)するのは、原則として避けるべきです。多重代入法と組み合わせ、各代入データセットでANCOVAを走らせて結果をRubinの規則で統合するのが標準的な運用です(詳細は 多重代入法 シリーズも参照)。
第四に、共変量×治療の交互作用は、主要解析にはデフォルトでは組み込まないのが通例です。EMA 2015年の Guideline on adjustment for baseline covariates でも、交互作用は主要解析ではなく予め指定したサブグループ解析・効果修飾の探索として扱うことが推奨されています。
第五に、逆ランダム化(reverse randomization)回避の観点です。層別ランダム化で用いた層別因子は必ず共変量として入れる必要があります(入れないと検定の名目水準が保たれません)。一方、層別化していない共変量を後付けで足す場合は、事後恣意性に注意しSAPで事前指定することが必須です。
⚠️ 実務でやりがちな落とし穴
- 解析計画書で共変量を「あとから決める」と書いてしまう(事前指定原則違反)
- 共変量を5つ以上入れすぎてサンプル数あたりの自由度が枯渇する
- ベースライン値が「効果に影響しそうだから」という理由のみで交互作用を入れる
まとめ ― 共変量調整は『事前指定 × 線形 × 限定数』が三本柱
本記事ではANCOVAをFDA/EMAガイダンスの観点から整理し、R(lm / emmeans)と SAS(PROC GLM / PROC MIXED)の両方で実装する流れを通しで見てきました。要点は次の通りです。
- ANCOVAは「事前指定した少数の共変量で線形に調整する」ことが大原則であり、これを外れた瞬間に規制対応上のリスクが立ち上がります
- ベースライン値を共変量として入れることで、変化量(CFB)の分散を縮め、検出力を上げつつバイアスも抑えられます
- 連続共変量はカテゴリ化せず、欠測がある場合は多重代入法と組み合わせます
- 非線形リンク(ロジスティック・Cox)では条件付き効果と限界効果の違いを意識し、必要に応じて標準化やG-computationを使います
規制対応として、SAP(統計解析計画書)には少なくとも次の項目を明示してください。
- 主要解析に含める共変量の名前・スケール(連続/カテゴリ)・参照水準
- 線形性の仮定とその妥当性チェックの方針
- 共変量に欠測があった場合の取り扱い(多重代入法の手順・代入モデル)
- 共変量×治療の交互作用を主要解析に含めるか、サブグループ解析として扱うか
「事前指定された共変量」「線形でモデリング」「数は試験規模に対し合理的に」── この3本柱が崩れない限り、ANCOVAは依然として臨床試験の主要解析として最も信頼できる選択肢の一つです。
📖 次に読みたい関連記事
参考書籍 ― 共変量調整をさらに深く学ぶ3冊