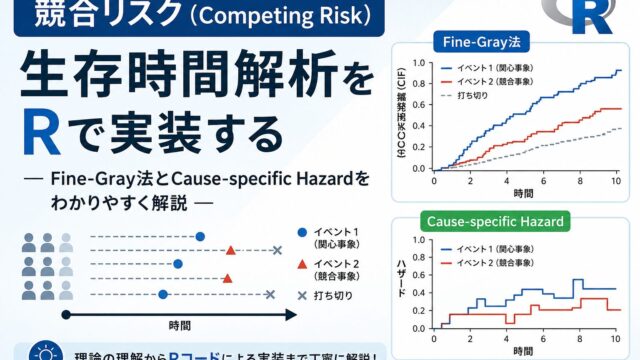
競合リスク(Competing Risks)とは ― Fine-Grayモデルと累積発生関数をRで実装 ―

この記事でわかること
・競合リスク(Competing Risks)とは何か ― 目的イベントの観測を妨げる「競合イベント」の考え方
・累積発生関数(CIF)と「1 − カプランマイヤー(1 − KM)」の違い ― なぜ後者は確率を過大評価するのか
・原因別ハザード(cause-specific hazard)と部分分布ハザード(Fine-Grayモデル)の考え方の違い
・R(tidycmprsk・survival パッケージ)/SASでの累積発生関数とFine-Grayモデルの実装方法
・原因別ハザードモデルとFine-Grayモデルの実務での使い分け(病因の解明か、絶対リスクの予測か)
はじめに
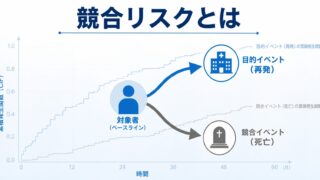
臨床試験や観察研究で「目的とするイベントがいつ起こるか」を解析する必要がある場面では、競合リスク(Competing Risks)への正しい対応が極めて重要になります。たとえば、がんの再発を目的イベントとした研究では、再発を観測する前に他病死が起こると、その被験者については再発をもはや観測できなくなります。このように、目的イベントの発生を妨げてしまうイベントを「競合イベント」と呼びます。
通常のカプランマイヤー法による生存時間推定についてやCox比例ハザードモデルでは、競合イベントを単なる「打ち切り(censoring)」として扱いがちです。しかしこの扱いは、目的イベントの累積発生確率を過大評価してしまうという深刻な問題を引き起こします。競合イベントで脱落した被験者を「いつか目的イベントを起こしうる人」として母数に残し続けてしまうためです。
本記事は、製薬企業で臨床試験を担当する生物統計家、臨床研究に携わる研究者、そして生存時間解析を学ぶ学生の方を主な対象としています。生存時間解析の前提となる考え方については生存時間解析の導入と基礎概念についてもあわせてご覧ください。以下では、競合リスクの概念から累積発生関数(CIF)・原因別ハザード・Fine-Grayモデルまでを体系的に整理し、RおよびSASによる実装と実務での使い分けを、図解とコードを交えてわかりやすく解説します。
競合リスクとは何か
競合リスク(Competing Risks)とは、ある被験者について複数の種類のイベントが起こりうり、そのうちのどれか一つが起こると他のイベントの観測が妨げられる、という状況を指します。このとき、目的イベント以外のイベントを「競合イベント(competing event)」と呼びます。各被験者は複数のイベントのいずれか一つに「先着順」で到達する、というイメージです。
実務では、次のような場面で競合リスクが現れます。
| 研究領域 | 目的イベント | 競合イベント |
|---|---|---|
| がん臨床試験 | がんの再発 | 他病死(がん以外の原因による死亡) |
| 循環器研究 | 心血管イベント(心筋梗塞など) | 非心血管死 |
| 骨髄移植研究 | 再発 | 移植関連死亡(TRM) |
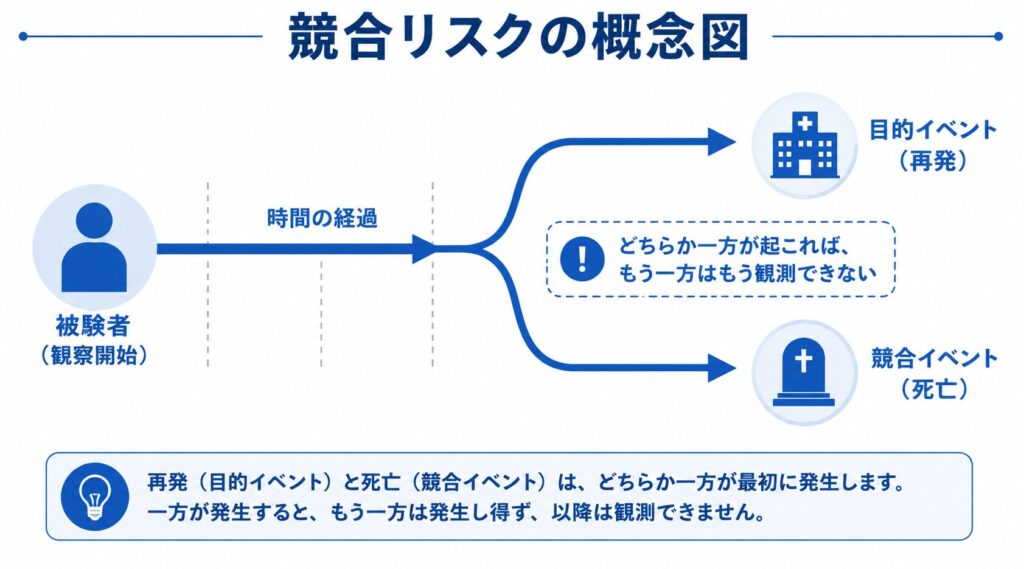
なぜ「1 − KM」がCIFを過大評価するのかを直感的に考えてみます。カプランマイヤー法は、打ち切りを「その後も目的イベントを起こしうるが、たまたま観測が途切れただけ」とみなし、独立な打ち切り(独立打ち切り)であることを前提にしています。ところが競合イベントは、起こった瞬間に「いつか目的イベントを起こす可能性」そのものを奪ってしまいます。たとえば他病死した被験者は、もう二度とがん再発を起こすことはありません。つまり競合イベントは独立な打ち切りではなく、これを単純に打ち切り扱いすると、目的イベントの発生確率が実際より高く見積もられてしまうのです。
そこで用いられるのが累積発生関数(CIF, Cumulative Incidence Function)です。CIFは「時刻 \( t \) までに、競合イベントに先を越されることなく目的イベントが実際に起こった確率」を表します。ここで重要なのは、CIFが競合イベントの存在を母数のなかに正しく織り込んでいる点です。すべての原因のCIFを足し合わせると、その時刻までに何らかのイベントが起こった確率に一致し、決して全体で1を超えることはありません。一方の「1 − KM」は競合イベントを無視するため、複数原因の確率を足すと1を超えてしまうことすらあり、絶対リスクの指標としては不適切になります。
競合イベント(死亡など)を単純な「打ち切り」として扱い、「1 − カプランマイヤー」で目的イベントの発生確率を推定すると、累積発生確率を過大評価してしまいます。競合イベントは独立な打ち切りではなく、目的イベントが起こる機会そのものを奪うためです。複数イベントが存在する解析では、必ず累積発生関数(CIF)を用いることが重要になります。
数理的背景:原因別ハザードと部分分布ハザード
競合リスクの統計モデルを正しく使い分けるには、「原因別ハザード」と「部分分布ハザード」という2つのハザードを区別することが出発点になります。両者は数式の上では似ていますが、リスク集合(risk set)の定義がまったく異なり、推定される量の解釈も変わります。
原因別ハザード(cause-specific hazard)
原因 \( k \) の 原因別ハザード \( \lambda_k(t) \) は、時点 \( t \) まですべてのイベントが起きずに生存している被験者の中で、原因 \( k \) のイベントが瞬間的に起こる率として、次のように定義されます。
\[ \lambda_k(t) = \lim_{\Delta t \to 0} \frac{1}{\Delta t}\, P\bigl(t \le T < t+\Delta t,\ D=k \mid T \ge t\bigr) \]
ここで \( T \) はイベント発生時刻、\( D \) はどの原因でイベントが起きたかを表します。重要なのは条件部分の \( T \ge t \) で、これは「時点 \( t \) の直前まで、どの原因のイベントも経験していない」被験者だけがリスク集合に含まれることを意味します。つまり、競合イベントを起こした被験者はその時点でリスク集合から外れます。この \( \lambda_k(t) \) をCoxモデルでモデル化したものが原因別Coxモデル(cause-specific Cox)です。
累積発生関数(CIF)との関係
実際に臨床で関心があるのは「ある時点までに原因 \( k \) のイベントが起きている確率」、すなわち 累積発生関数(CIF) \( F_k(t) = P(T \le t,\ D=k) \) です。CIFは原因別ハザードと全生存関数を使って次のように表されます。
\[ F_k(t) = \int_0^t S(u^-)\,\lambda_k(u)\,du \]
ここで \( S(u^-) = P(T \ge u) \) は、競合イベントを含む すべての原因 を考慮した全生存関数です。この式が示す本質は、CIFが「自分の原因別ハザード \( \lambda_k \)」だけでなく「競合イベントを含む全生存 \( S \)」にも依存するという点です。競合イベントのハザードが高ければ \( S(u^-) \) は早く下がり、その分だけ原因 \( k \) のCIFも抑えられます。この依存関係こそが、競合リスク下で \( 1-\text{KM}\)(カプラン・マイヤー)がCIFを過大評価してしまう本質的な理由です。なお、全原因のCIFを足し合わせると、いずれかのイベントが起きた確率に一致します。
\[ \sum_{k} F_k(t) = 1 – S(t) \]
これは「時点 \( t \) までに何らかのイベントが起きた確率」を意味します。
部分分布ハザードとFine-Gray
Fine-Grayモデルが用いる 部分分布ハザード \( \bar{\lambda}_k(t) \) は、CIFに直接対応するように設計されたハザードです。その特徴は、リスク集合に「すでに競合イベントを起こした被験者を、その後も残し続ける」という特殊な定義にあります。CIFと部分分布ハザードは次の関係で結ばれます。
\[ F_k(t) = 1 – \exp\Bigl\{-\int_0^t \bar{\lambda}_k(u)\,du\Bigr\} \]
この式は、通常の生存関数とハザードの関係式と同じ形をしており、\( \bar{\lambda}_k(t) \) を積分して指数変換すれば、そのままCIF \( F_k(t) \) が得られることを意味します。したがってFine-Gray回帰は、共変量が CIFに直接 比例的な効果を持つと仮定するモデルであり、共変量がリスクの絶対値(発生確率)をどう動かすかを直接モデル化できる点が利点です。
原因別Coxモデルと Fine-Grayモデルは「どちらが正しい」ものではなく、目的に応じて使い分けます。原因別ハザードは、リスク集合から競合イベント例を除外するため「その病態が起こるメカニズム・病因の理解」に向いており、生物学的・薬理学的な作用を議論したいときに適します。一方 部分分布ハザード(Fine-Gray)は、競合イベント例をリスク集合に残すことでCIFと直結するため「ある集団で実際にどれだけイベントが起こるか(絶対リスク)の予測・予後評価」に向いています。理想的には両方を報告し、メカニズムと絶対リスクの両面から結果を解釈することが推奨されます。
Rによる競合リスク解析
ここからは、R標準の survival パッケージに含まれる mgus2 データ(単クローン性ガンモパチー;MGUS患者の追跡データ)を用いて、競合リスク解析の一連の流れを確認します。関心のあるイベントは「形質細胞腫瘍への進展(pcm)」、競合イベントは「死亡(death)」です。多くの患者は pcm に進展する前に死亡するため、競合リスクを無視した解析では pcm のリスクを過大評価してしまいます。
ステップ1:データ準備
まず、追跡時間 etime と多値の状態変数 event を作成します。pcm 進展と死亡のどちらが先に起こったかを 1 つの状態に集約し、event を3水準(censor/pcm/death)の因子(factor)に変換します。
library(survival)
library(tidycmprsk)
# pcm進展(ptime/pstat)と死亡(futime/death)を1つの時間・状態に集約
mgus2$etime <- with(mgus2, ifelse(pstat == 0, futime, ptime))
mgus2$event <- with(mgus2, ifelse(pstat == 0, 2 * death, 1))
mgus2$event <- factor(mgus2$event, 0:2,
labels = c("censor", "pcm", "death"))
table(mgus2$event)
> table(mgus2$event)
censor pcm death
409 115 860
全1,384例のうち、pcm進展は115例(約8%)にとどまる一方、死亡が860例(約62%)と圧倒的に多いことが分かります。つまり大多数の患者はpcmに進展する前に死亡しており、死亡はpcmにとって典型的な競合イベントです。この「競合イベントが多数を占める」状況こそ、Kaplan-Meier法ではなく累積発生関数(CIF)を用いるべき場面になります。
ステップ2:累積発生関数(CIF)の推定
tidycmprsk::cuminc() を使い、性別(sex)ごとに各イベントのCIF(ある時点までにそのイベントが起きた確率)を推定します。
cif <- cuminc(Surv(etime, event) ~ sex, data = mgus2)
cif
> cif
time n.risk estimate std.error outcome
─────────────────────────────────────────────────
sex=F, outcome=pcm
60 588 0.025 0.005 pcm
120 378 0.044 0.007 pcm
240 96 0.067 0.011 pcm
sex=F, outcome=death
60 588 0.205 0.013 death
120 378 0.460 0.017 death
240 96 0.738 0.018 death
sex=M, outcome=pcm
60 623 0.029 0.005 pcm
120 356 0.055 0.008 pcm
240 82 0.078 0.012 pcm
sex=M, outcome=death
60 623 0.258 0.014 death
120 356 0.534 0.018 death
240 82 0.808 0.018 death
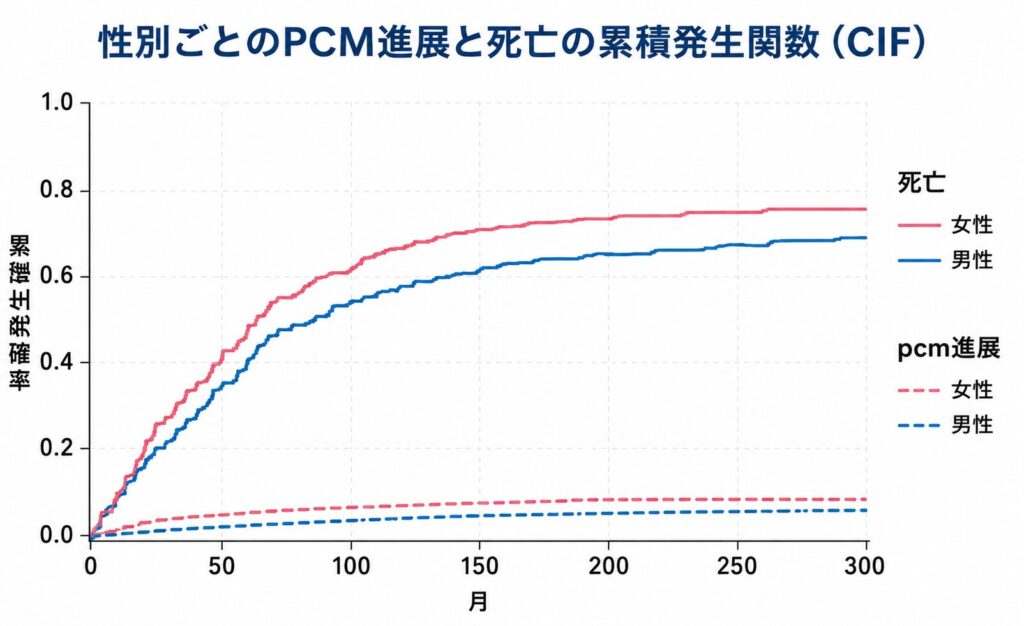
死亡のCIFは120か月時点で女性0.460・男性0.534と大きく立ち上がるのに対し、pcm進展のCIFは同時点で女性0.044・男性0.055と低水準で頭打ちになります。240か月でも死亡CIFは0.7〜0.8に達する一方、pcmは0.07〜0.08程度です。男性は死亡CIFがやや高く、その分pcmに進展する前に死亡で「取り除かれる」割合が大きいことが読み取れます。
CIF曲線は次の図で示します。描画コードのみ掲載します。
library(ggsurvfit)
cuminc(Surv(etime, event) ~ sex, data = mgus2) |>
ggcuminc(outcome = c("pcm", "death")) +
labs(x = "月", y = "累積発生確率")
ステップ3:Gray検定
群間でCIFが等しいかを検定するのがGray検定です。cuminc() の出力にはイベントごとの検定結果が含まれます。
cif$cmprsk
> cif$cmprsk
outcome statistic df p.value
─────────────────────────────────────────
pcm 1.42 1 0.234
death 7.38 1 0.007
pcm進展のGray検定はp=0.234で、性別によるCIFの差は統計的に有意ではありません。一方、死亡のCIFはp=0.007で有意差があり、男女で死亡の累積発生に明確な違いがあることを示しています。pcmそのものの発生確率は性別に依存しないが、競合イベントである死亡は性別の影響を強く受ける、という構造が見えてきます。
ステップ4:原因別ハザードモデル(cause-specific Cox)
特定の原因のハザードを年齢・性別でモデル化するのが原因別Cox回帰です。pcm進展を「イベント」、死亡を打ち切り扱いにして coxph() を当てはめます。
csc <- coxph(Surv(etime, event == "pcm") ~ age + sex, data = mgus2)
summary(csc)$conf.int
> summary(csc)$conf.int
exp(coef) exp(-coef) lower .95 upper .95
age 1.018 0.982 1.005 1.031
sexM 1.171 0.854 0.809 1.696
原因別ハザード比はageが1.018(1歳上がるごとにpcm発生ハザードが約1.8%上昇)、sexM(男性)が1.171です。ただし性別の95%信頼区間は0.809〜1.696と1をまたいでおり有意ではありません。原因別ハザードは「pcmへ進展する瞬間的な力」を表しており、病態のメカニズムを考えるうえで重要な量になります。
ステップ5:Fine-Gray(部分分布ハザード)回帰
Fine-Gray回帰は、CIFに直接対応する部分分布ハザード(subdistribution hazard)をモデル化します。tidycmprsk::crr() を使います。
fg <- crr(Surv(etime, event) ~ age + sex, data = mgus2)
fg
> fg
Variable Coef HR 95% CI p-value
──────────────────────────────────────────────────
age -0.014 0.986 0.974, 0.998 0.024
sexM -0.090 0.914 0.631, 1.323 0.633
部分分布ハザード比はageが0.986と、原因別Coxの1.018とは逆向き(1未満)になります。これは矛盾ではありません。高齢者ほど死亡(競合イベント)で早く取り除かれるため、結果として観察されるpcmのCIFはむしろ高齢で低くなる、という集団レベルの帰結を反映しています。原因別Cox(メカニズム)とFine-Gray(リスク予測)は問いが異なるため、両者を併記して目的に応じて使い分けることが極めて重要です。
両モデルのハザード比を整理すると次のとおりです。
| 変数 | 原因別HR(cause-specific) | 部分分布HR(Fine-Gray) | 解釈の対象 |
|---|---|---|---|
| age | 1.018 | 0.986 | 向きが逆転(競合の影響) |
| sexM | 1.171 | 0.914 | いずれも非有意 |
| 問い | 病態メカニズム(発生する力) | リスク予測(実際のCIF) | 目的で使い分け |
SASによる実装
SASでも同じ解析を PROC LIFETEST と PROC PHREG で実行できます。いずれも eventcode= オプションで「関心のあるイベント」を指定する点が競合リスク解析の鍵になります。ここでは event を 0=打ち切り、1=pcm進展、2=死亡とコード化したデータセット mgus2 を前提とします。
CIFの推定とGray検定は PROC LIFETEST で行います。eventcode=1 でpcm進展を関心イベントに指定し、strata sex で性別ごとに比較します。
proc lifetest data=mgus2 plots=cif(test);
time etime*event(0) / eventcode=1;
strata sex;
run;
time etime*event(0) は「event=0を打ち切り」とする指定で、eventcode=1 がpcm進展を関心イベント、それ以外(=2の死亡)を競合イベントとして扱うことを意味します。strata sex によりGray検定が実行され、Rの結果と同様にpcmではp≈0.23で有意差なしという出力が得られます。plots=cif(test) で性別ごとのCIF曲線も描画されます。Fine-Gray(部分分布ハザード)回帰は PROC PHREG の eventcode= で実行します。
proc phreg data=mgus2;
class sex (ref='F');
model etime*event(0) = age sex / eventcode=1;
hazardratio sex;
run;
model 文に eventcode=1 を付けるとFine-Gray回帰になり、ageの部分分布HRは約0.986とRの crr() と一致します。一方、eventcode= を外して死亡を打ち切り扱いにすれば、通常のCox回帰すなわち原因別ハザードモデル(ageのHR≈1.018)になります。同じ PROC PHREG で1行の違いにより両モデルを切り替えられる点が、SAS実装の大きな利点です。R と SAS の対応関係を整理すると次のとおりです。
| 解析 | R | SAS |
|---|---|---|
| CIF推定・Gray検定 | tidycmprsk::cuminc() | PROC LIFETEST(eventcode=) |
| 原因別Cox | coxph(Surv(.., event==”pcm”)) | PROC PHREG(eventcode=なし) |
| Fine-Gray回帰 | tidycmprsk::crr() | PROC PHREG(eventcode=) |
実務でのポイント
競合リスクの解析では、原因別ハザードモデル(cause-specific Cox)と部分分布ハザードモデル(Fine-Gray)のどちらを主役に据えるかが、しばしば最初の意思決定になります。両者は数学的にも解釈の上でも異なる量を推定しており、目的に応じた使い分けが欠かせません。
病因やメカニズムの理解、すなわち「ある共変量がその事象を直接的に引き起こすハザードを高めているのか」を知りたい場合は、原因別ハザードモデルが適切です。リスク集合から競合事象の発生者を除外し、その原因のハザードそのものを評価するため、生物学的・病態生理学的な解釈に向いています。
一方で、患者個人の絶対リスク(absolute risk)の予測や、規制当局へ提出する累積発生関数(CIF)にもとづくリスク提示が目的であれば、部分分布ハザードモデル(Fine-Gray)を選びます。Fine-Grayの回帰係数はCIFの形状に直接対応するため、「この共変量を持つ患者は、最終的にこの事象を経験する累積確率が高い/低い」という臨床的に直感的なメッセージにつながります。
実務上の合意として、両モデルを併せて報告することが国際的に推奨されています。原因別ハザードで病因への影響を示し、Fine-GrayでCIFへの影響を示すことで、ハザードへの作用と最終的な発生確率への作用を切り分けて読み手に伝えられるためです。共変量の係数が両モデルで符号や大きさが食い違うことも珍しくなく、その差異自体が競合事象を介した重要な臨床的示唆となります。
規制との関係では、ICH E9(R1)のestimand(推定目標)枠組みを意識する必要があります。死亡などの事象は、評価したいエンドポイントに対して中間事象(intercurrent event)となり得ます。これを競合リスクとして扱うのか、それとも別のストラテジー(治療方針ストラテジー等)で扱うのかを、解析計画書で事前に規定しておくことが、estimandの一貫性を保つうえで決定的に重要です。後付けで扱い方を決めると、結果の解釈が恣意的になり、規制審査でも問題視されます。
病因・メカニズムの理解が目的なら原因別ハザード(cause-specific Cox)、患者の絶対リスク予測や規制向けのCIFベースのリスク提示が目的なら部分分布ハザード(Fine-Gray)を選びます。実務では両者を併せて報告するのが推奨されます。さらにICH E9(R1)のestimand枠組みでは、死亡などの中間事象を競合リスクとして扱うかを解析計画段階で事前に規定しておくことが、結果の信頼性と規制対応の両面で不可欠です。
この記事をより深く理解するための参考書籍
統計・生物統計をさらに深く学びたい方に、おすすめの書籍をご紹介します。






関連記事
競合リスクの理解を深めるために、生存時間解析の基礎と関連手法もあわせてご覧ください。
- 生存時間解析の導入と基礎概念 — 打ち切りやハザードといった生存時間解析の出発点を、本記事の前提知識として復習できます。
- Cox比例ハザード性チェック完全ガイド — 原因別Coxを使う際に欠かせない比例ハザード性の確認方法を詳しく解説しています。
- 【徹底解説】RMST(制限付き平均生存時間)とは — 比例ハザードが成り立たない場面での代替指標として、競合リスクと並んで知っておきたい手法です。
まとめ
本記事では、競合リスクという概念から出発し、累積発生関数(CIF)が単純な \( 1-\text{KM} \) とは異なる理由、そして原因別ハザードモデルと部分分布ハザードモデル(Fine-Gray)の違いと使い分けまでを解説してきました。競合事象を無視して通常の生存時間解析を行うと、興味のある事象の発生確率を過大評価してしまうため、競合リスクの枠組みは臨床試験データの正しい解釈に不可欠です。
実務では、原因別ハザードで病因への作用を、Fine-GrayでCIFへの作用を示し、両者を併せて報告することで、読み手に誤解のないリスク像を伝えられます。さらにICH E9(R1)のestimand枠組みのもとで、死亡などの中間事象をどう扱うかを解析計画段階で明確に規定しておくことが、規制対応の品質を大きく左右します。RやSASでの実装は決して難しくありませんので、ぜひ手元のデータで \( \text{CIF} \) を描き、競合リスクを意識した解析を実践の中に取り入れていただければと思います。