ROC曲線とAUCをRで実装する ― 感度・特異度・最適カットオフから診断精度の評価まで ―

この記事でわかること
・ROC曲線とAUC(曲線下面積)が何を表す指標なのか、その基本的な考え方
・混同行列(2×2分割表)から求める感度・特異度・陽性的中率(PPV)・陰性的中率(NPV)の意味
・PPVとNPVが有病率(事前確率)に依存するという、診断検査で見落としがちな重要ポイント
・AUC = P(陽性者のスコア > 陰性者のスコア) という確率的解釈と、Mann-WhitneyのU統計量との数学的な等価性
・RのpROCパッケージによる実装、最適カットオフの決定、2つのROC曲線の群間比較の方法
はじめに
新しい診断バイオマーカーや予測モデルを開発したとき、「この指標はどれだけ正しく病気を見分けられるのか」という問いに必ず突き当たります。素朴な評価方法は、ある閾値(カットオフ値)を一つ決めて、感度(病気の人を正しく陽性と判定する割合)と特異度(健康な人を正しく陰性と判定する割合)を計算することです。しかしこの方法には弱点があります。感度と特異度はカットオフ値の選び方によって大きく変わってしまうため、「閾値をどこに置いたか」次第で性能評価が揺れてしまうのです。
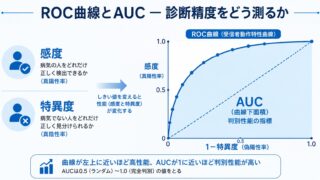
そこで役立つのが ROC曲線(Receiver Operating Characteristic curve、受信者操作特性曲線)と、その曲線下面積である AUC(Area Under the Curve)です。ROC曲線は、あらゆる閾値での感度と特異度を一枚の図にまとめ、AUCはそれを一つの数値に要約します。これにより、特定の閾値に依存せず判別性能を総合的に評価できます。
ROC/AUCは、コンパニオン診断やバイオマーカー探索といった製薬・体外診断の現場、そしてロジスティック回帰モデルの性能評価まで幅広く使われる重要な指標です。本記事では、RのpROCパッケージと実際の医療データを使い、手を動かしながらROC曲線とAUCの考え方を学んでいきます。
ROC曲線とAUCをやさしく理解する
製薬の臨床開発や臨床検査の現場では、「ある検査値(バイオマーカー)が病気のあり・なしをどれくらいうまく見分けられるか」を評価したい場面が頻繁にあります。たとえば、新しいバイオマーカーが疾患の有無を判別できるか、あるいはロジスティック回帰で構築した予測モデルがイベントの発生をどれだけ正しく分類できるか、といった「判別性能(discrimination)」の評価です。
こうした連続値のスコアを使った判別性能を、特定の閾値(カットオフ)に縛られずに総合評価できる代表的なツールが、ROC曲線(Receiver Operating Characteristic curve、受信者動作特性曲線)と、その曲線下面積であるAUC(Area Under the Curve)です。なぜ単一のカットオフではなく曲線で評価するのか、その理由を順を追って見ていきましょう。
まずは混同行列から
判別性能を考える出発点は、混同行列(confusion matrix、2×2分割表)です。実際の状態(疾患あり/なし)と、検査による判定(陽性/陰性)を掛け合わせると、次の4つのマスに分類できます。
| 実際:疾患あり | 実際:疾患なし | |
|---|---|---|
| 判定:陽性 | 真陽性 TP(正しく陽性) | 偽陽性 FP(誤って陽性) |
| 判定:陰性 | 偽陰性 FN(誤って陰性) | 真陰性 TN(正しく陰性) |
この4つの数(TP・FP・FN・TN)から、検査の性能を表すさまざまな指標が計算されます。
感度と特異度
まず押さえたいのが、感度と特異度です。
感度(Sensitivity、再現率とも呼ばれます)は、
\[ \text{感度} = \frac{TP}{TP + FN} \]
で定義されます。これは「実際に疾患を持つ人のうち、検査が正しく陽性と判定できた割合」です。感度が高い検査は病気を見逃しにくく、スクリーニング(ふるい分け)検査で特に重視されます。
特異度(Specificity)は、
\[ \text{特異度} = \frac{TN}{TN + FP} \]
で定義されます。これは「実際に疾患を持たない人のうち、検査が正しく陰性と判定できた割合」です。特異度が高い検査は健康な人を誤って陽性としにくく、確定診断(精密検査)で重視されます。
感度と特異度は、どちらも「実際の状態を出発点(分母)」とした指標である点が共通しています。つまり、検査を受ける集団の有病率(病気の人の割合)が変わっても、原則として値が変動しない安定した性質を持ちます。
陽性的中率PPVと陰性的中率NPV
一方、検査を受ける側(患者・臨床医)が本当に知りたいのは、「検査が陽性だったとき、本当に病気である確率はどれくらいか」です。これに答えるのが的中率です。
陽性的中率(PPV、Positive Predictive Value)は、
\[ \text{PPV} = \frac{TP}{TP + FP} \]
で、「検査が陽性だった人のうち、実際に疾患を持つ割合」を表します。陰性的中率(NPV、Negative Predictive Value)は、
\[ \text{NPV} = \frac{TN}{TN + FN} \]
で、「検査が陰性だった人のうち、実際に疾患を持たない割合」を表します。これらは「検査の判定結果を出発点(分母)」とした指標です。
PPVとNPVは、感度・特異度とは違い、有病率(事前確率)に強く依存します。まったく同じ感度・特異度を持つ検査でも、有病率が低い集団に適用するとPPVは大きく下がります(偽陽性が相対的に増えるため)。たとえばまれな疾患の集団検診では、感度・特異度が高くても「陽性なのに実は病気でない人」が多数を占めることが珍しくありません。論文や検査キットの添付文書でPPV/NPVを見るときは、必ずどの有病率を前提にした値かを確認してください。
ROC曲線とAUC
ここで本題に戻ります。感度と特異度は、検査のカットオフ(閾値)をどこに置くかで変化します。カットオフを下げて「陽性」と判定しやすくすれば感度は上がりますが、その分だけ偽陽性が増えて特異度は下がります。両者はトレードオフの関係にあるのです。
そこで、カットオフを連続的に動かしながら、そのつどの「感度(縦軸)」と「1−特異度(横軸、偽陽性率)」をプロットしたものがROC曲線です。カットオフという1つの選択に縛られず、あらゆる閾値での性能を一望できるのが利点です。
ROC曲線は左上の隅(感度=1、1−特異度=0)に近いほど良い判別性能を表します。逆に、左下から右上へ引いた対角線はランダムな判定(コイン投げと同じ)に相当します。
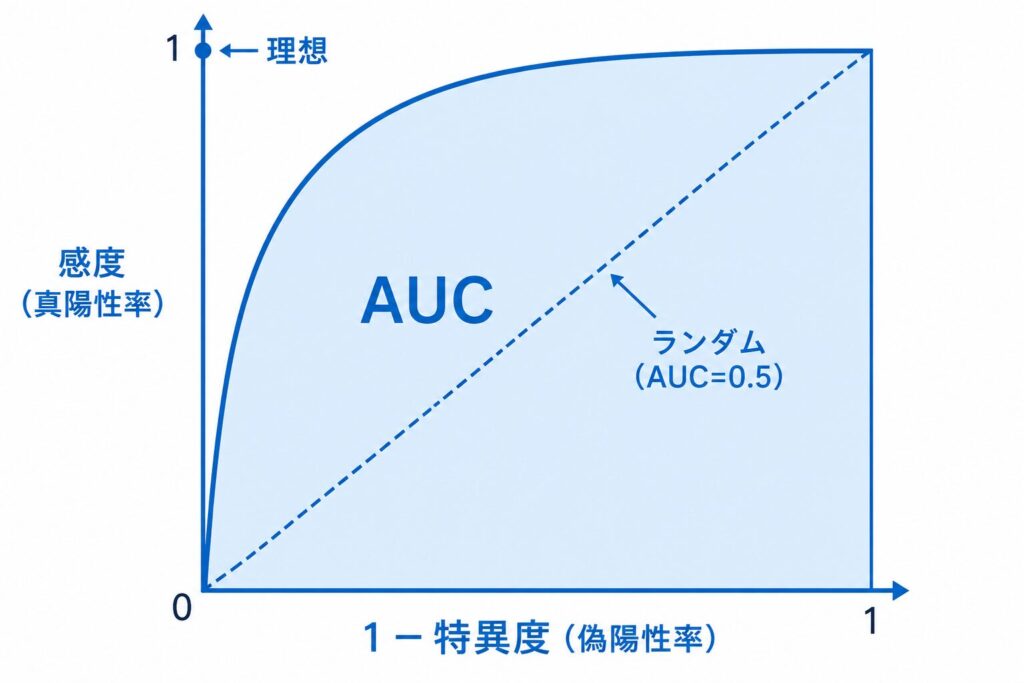
この曲線の下側の面積がAUC(曲線下面積)で、判別性能を1つの数値に要約した指標です。AUCは0.5〜1.0の値をとり、1に近いほど判別性能が高く、0.5なら完全にランダム(判別能力なし)を意味します。AUCの大まかな目安は次のとおりです。
| AUCの値 | 判別性能の目安 |
|---|---|
| 0.5 | 判別能力なし(ランダム) |
| 0.5 〜 0.7 未満 | 低い |
| 0.7 〜 0.8 未満 | 許容できる |
| 0.8 〜 0.9 未満 | 良好 |
| 0.9 以上 | 優秀 |
ただし、この目安はあくまで一般的な参考値です。臨床的にどの程度のAUCが「使える」かは、対象疾患や用途(スクリーニングか確定診断か)によって変わる点には注意してください。
ROC曲線とAUCの数理的背景
ここからは、ROC曲線とAUCを数式で少していねいに定式化し、AUCがなぜ「確率」として解釈できるのかを見ていきます。実装の理解にも、検定との関係を理解するうえでも役立つ部分です。
感度・特異度をカットオフの関数として表す
いま、連続値の検査スコアを確率変数 \( X \) とし、あるカットオフ \( c \) を決めて「\( X \ge c \) なら陽性、\( X < c \) なら陰性」と判定するとします。疾患あり群でのスコアを \( X_+ \)、疾患なし群でのスコアを \( X_- \) と書くことにします。
このとき感度と特異度は、カットオフ \( c \) の関数として次のように表せます。
\[ \text{感度}(c) = \mathrm{TPR}(c) = P(X_+ \ge c) \]
\[ \text{特異度}(c) = P(X_- < c) \]
上の式は「疾患あり群のスコアがカットオフ以上になる確率=真陽性率(TPR、True Positive Rate)」、下の式は「疾患なし群のスコアがカットオフ未満になる確率」を意味します。カットオフ \( c \) を大きくすれば陽性と判定されにくくなり、感度は下がり特異度は上がる、という先ほどのトレードオフが、ここでは \( c \) という1つの変数の動きとして表現されています。
ROC曲線を数式で表す
ROC曲線は、横軸に偽陽性率(FPR、False Positive Rate)、縦軸に真陽性率(TPR)をとった曲線でした。これらをカットオフ \( c \) の関数として書くと、
\[ \mathrm{FPR}(c) = 1 – \text{特異度}(c) = P(X_- \ge c) \]
\[ \mathrm{TPR}(c) = \text{感度}(c) = P(X_+ \ge c) \]
となります。ROC曲線とは、カットオフ \( c \) を \( +\infty \) から \( -\infty \) まで連続的に動かしたときに、点 \( \big(\mathrm{FPR}(c),\ \mathrm{TPR}(c)\big) \) が描く軌跡、すなわち \( c \) をパラメータとするパラメトリック曲線だと理解できます。\( c \) を動かすにつれて、点が左下 \((0,0)\) から右上 \((1,1)\) へと移動していきます。
AUCの確率的解釈(最重要)
AUCはこの曲線の下側の面積ですが、実は次のような非常に明快な確率的解釈を持ちます。これがAUCを理解するうえで最も重要なポイントです。
\[ \mathrm{AUC} = P(X_+ > X_-) \]
これは「無作為に選んだ疾患あり群の1人のスコア \( X_+ \) が、無作為に選んだ疾患なし群の1人のスコア \( X_- \) より大きい確率」を意味します。言い換えれば、AUCとは「ランダムに選んだ患者ペア(病気の人と健康な人)について、検査が正しく『病気の人のほうがスコアが高い』と順序づけられる確率」なのです。AUC=0.5が「コイン投げと同じ」になるのも、ランダムな2人ならどちらのスコアが高いかは五分五分だから、と納得できます。
Mann-WhitneyのU統計量との等価性
さらに重要なのは、この確率 \( P(X_+ > X_-) \) を標本から推定する自然な方法が、Mann-WhitneyのU統計量(Wilcoxonの順位和検定の統計量)と数学的に等価であるという事実です。
疾患あり群の標本を \( x_1, \dots, x_{n_+} \)(サイズ \( n_+ \))、疾患なし群の標本を \( y_1, \dots, y_{n_-} \)(サイズ \( n_- \))とします。すべての群間ペア \((x_i, y_j)\)(全部で \( n_+ \times n_- \) 通り)について、陽性側のスコアが大きいペアを数え上げると、U統計量は
\[ U = \sum_{i=1}^{n_+} \sum_{j=1}^{n_-} \left[ \mathbf{1}(x_i > y_j) + \tfrac{1}{2}\mathbf{1}(x_i = y_j) \right] \]
と書けます(同点のペアは0.5として数えます)。そして、標本から計算されるAUCは次の関係を満たします。
\[ \mathrm{AUC} = \frac{U}{n_+ \times n_-} \]
つまりAUCは「陽性スコアが陰性スコアを上回ったペアの割合」そのものであり、これはまさに先ほどの確率 \( P(X_+ > X_-) \) の自然な推定値になっています。全 \( n_+ \times n_- \) ペアのうち、正しく順序づけられたペアが占める割合、という直感どおりの量なのです。
AUCがMann-WhitneyのU統計量と等価であることには、実務上うれしい含意がいくつもあります。第一に、AUCはスコアの順位(大小関係)だけで決まるため、スコアの分布に正規性などの仮定を置かないノンパラメトリックな指標です。第二に、順位ベースなので外れ値や単調変換に頑健です(たとえばスコアを対数変換してもAUCは変わりません)。第三に、この等価性のおかげで「AUCが0.5と有意に異なるか」の検定を、確立されたWilcoxon順位和検定の枠組みで行えます。RのpROCパッケージがDeLong法などでAUCの信頼区間や群間比較を計算できるのも、この理論的な土台があるからです。
RでROC曲線を描き、AUCを評価する
ここからは、実際の医療データを使ってRでROC曲線を描き、AUCの算出・信頼区間・最適カットオフ・群間比較までを一通り実装します。理論で見た「感度・特異度のトレードオフ」「AUCの確率的解釈」が、コードと出力でどう現れるかを確認していきましょう。
使用するのは、ROC解析の定番パッケージである pROC と、同パッケージに同梱されている aSAH データセットです。aSAHは、くも膜下出血(aneurysmal SubArachnoid Hemorrhage)の患者113名について、入院時のバイオマーカーと退院後の予後(outcome:Good=良好/Poor=不良)を記録した実データです。ここでは、脳損傷マーカーである s100b(血中S100βタンパク濃度) が、予後不良(Poor)をどれだけ判別できるかを評価します。
ステップ1:パッケージとデータの準備
まずpROCを読み込み、aSAHデータの規模と予後の内訳を確認します。
# pROCパッケージの読み込み(未インストールなら install.packages("pROC"))
library(pROC)
data(aSAH)
# データの規模と予後(outcome)の内訳を確認
dim(aSAH)
table(aSAH$outcome)
> dim(aSAH)
[1] 113 7
> table(aSAH$outcome)
Good Poor
72 41
113名・7変数のデータで、予後良好(Good)が72名、予後不良(Poor)が41名です。s100b や ndka は連続値のバイオマーカーで、これらの値の大小から「予後不良かどうか」をどれだけ判別できるかを、以降のROC解析で評価していきます。
ステップ2:ROC曲線とAUCを求める
roc() 関数にアウトカムと予測変数を渡すだけでROCオブジェクトが作られ、AUCも同時に計算されます。
# s100bによる予後不良(Poor)判別のROC
roc_s100b <- roc(aSAH$outcome, aSAH$s100b,
levels = c("Good", "Poor"), # control=Good, case=Poor
direction = "<") # Poorほどs100bが高い
print(roc_s100b)
Call:
roc.default(response = aSAH$outcome, predictor = aSAH$s100b, levels = c("Good", "Poor"), direction = "<")
Data: aSAH$s100b in 72 controls (aSAH$outcome Good) < 41 cases (aSAH$outcome Poor).
Area under the curve: 0.7314
AUCは 0.7314 でした。先に確認した確率的解釈に従えば、これは「無作為に選んだ予後不良の患者1名のs100bが、無作為に選んだ予後良好の患者1名のs100bより高い確率が約73%」であることを意味します。AUCの目安(0.7〜0.8=許容できる)に照らすと、s100b単独でも一定の判別能力を持つことがわかります。
ステップ3:AUCの95%信頼区間(DeLong法)
点推定だけでなく、AUCのばらつきを信頼区間で評価します。pROCはDeLong法による信頼区間を標準で計算します。
# AUCの95%信頼区間(DeLong法)
ci.auc(roc_s100b)
95% CI: 0.6301-0.8326 (DeLong)
AUCの95%信頼区間は 0.6301〜0.8326 です。下限が0.63とランダム(0.5)を上回っているため、s100bの判別能力は偶然では説明しにくいといえます。ただし区間の幅が広く、症例数113名という規模では推定の不確実性が残る点にも注意が必要です。
ステップ4:最適カットオフ(Youden index)
臨床で実際に「陽性/陰性」を分けるには、具体的なカットオフ値が必要です。感度+特異度−1(Youden index)を最大化する点を求めます。
# Youden indexを最大化する最適カットオフ
coords(roc_s100b, x = "best", best.method = "youden",
ret = c("threshold", "specificity", "sensitivity"))
threshold specificity sensitivity
1 0.205 0.8055556 0.6341463
最適カットオフは s100b = 0.205 で、このとき特異度0.806・感度0.634となります。この閾値以上を「予後不良の疑いあり」と判定すれば、予後良好の約81%を正しく陰性とし、予後不良の約63%を正しく拾い上げられます。感度・特異度のどちらを優先すべきかは、後述のとおり検査の目的次第です。
ステップ5:2つのバイオマーカーのAUCを比較(DeLong検定)
s100bと、もう一つのマーカー ndka(神経損傷マーカー)の判別性能を比較します。同一患者から測った相関のある2つのROC曲線の比較には、DeLong検定を用います。
# ndkaのROC
roc_ndka <- roc(aSAH$outcome, aSAH$ndka,
levels = c("Good", "Poor"), direction = "<")
# 2つのAUCの差をDeLong検定で比較
roc.test(roc_s100b, roc_ndka, method = "delong")
DeLong's test for two correlated ROC curves
data: roc_s100b and roc_ndka
Z = 1.3908, p-value = 0.1643
alternative hypothesis: true difference in AUC is not equal to 0
95 percent confidence interval:
-0.04887061 0.28769174
sample estimates:
AUC of roc1 AUC of roc2
0.7313686 0.6120663
s100bのAUC(0.7314)はndkaのAUC(0.6121)より見かけ上0.12ほど高いものの、DeLong検定の p値は0.1643 で、有意水準5%では「2つのAUCに差がある」とは言えません。AUCの差の95%信頼区間も −0.049〜0.288 と0をまたいでいます。数値の大小だけで「s100bのほうが優れたマーカーだ」と結論づけるのは早計であり、検定や信頼区間まで確認することの重要性がよくわかる例です。
ROC曲線の描画
最後に、2つのROC曲線を重ねて描画します。
# 2本のROC曲線を重ねて描画
plot(roc_s100b, col = "#2E86C1", lwd = 2, legacy.axes = TRUE,
xlab = "1 - 特異度(偽陽性率)", ylab = "感度(真陽性率)",
main = "s100b と ndka のROC曲線")
plot(roc_ndka, col = "#E74C3C", lwd = 2, add = TRUE)
abline(0, 1, lty = 2, col = "gray") # ランダム判定の対角線
legend("bottomright",
legend = c("s100b(AUC=0.731)", "ndka(AUC=0.612)"),
col = c("#2E86C1", "#E74C3C"), lwd = 2)
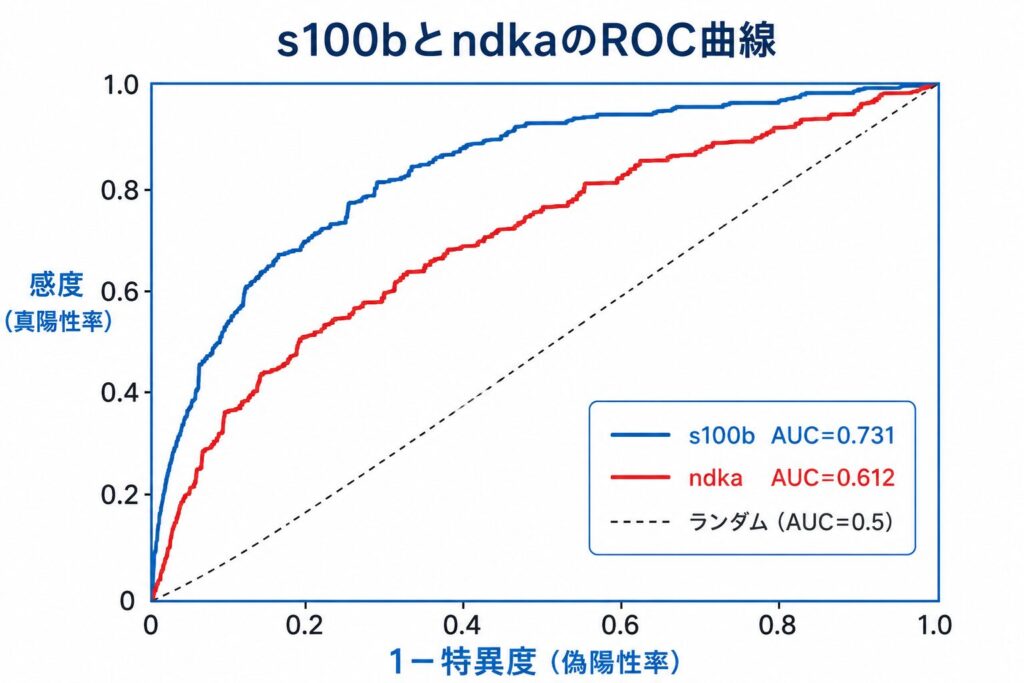
左上の隅に近い曲線ほど判別性能が高く、s100b(青)のほうがndka(赤)より全体に左上に位置しています。点線の対角線はAUC=0.5(ランダム判定)を表します。ただしステップ5で見たとおり、この見た目の差が統計的に有意とは限らない点に留意してください。
実務でのポイント
ROC曲線とAUCは便利な指標ですが、数値を鵜呑みにすると判断を誤ります。製薬・診断の現場で押さえておきたい論点を整理します。
AUCの数値の大小だけで「こちらのバイオマーカーが優れている」と結論づけてはいけません。2つのAUCに見かけ上の差があっても、それが統計的に意味のある差とは限らないからです。本記事の実装で扱ったDeLong検定(2つのROC曲線のAUCを比較する検定)では、AUCに差があるように見えてもp=0.16となり、有意差ありとは言えない例が登場しました。AUCを比較するときは、点推定値だけでなく検定や信頼区間まで含めて判断することが不可欠です。
カットオフは目的によって変えるものです。最適カットオフの定番である Youden index(感度+特異度−1を最大化する点)はあくまで一つの基準にすぎません。見逃しを避けたいスクリーニング検査では感度を重視し、偽陽性による不要な精密検査・不安を避けたい確定診断では特異度を重視します。臨床的な誤判定のコストや対象集団の有病率を踏まえて閾値を選ぶ姿勢が求められます。
PPV・NPVは有病率に依存する点も実務上きわめて重要です。陽性的中率(PPV:陽性と判定された人が実際に病気である割合)と陰性的中率(NPV:陰性と判定された人が本当に健康である割合)は、感度・特異度やAUCが同じでも、有病率が変わると大きく変動します。とくに有病率の低い集団へスクリーニングを適用すると、感度・特異度が良好でもPPVが想像以上に下がり、「陽性と出ても実際は病気でない人」が多数を占めることがあります。
臨床的に意味を持つのが高特異度域だけ、という場面もあります。このときは曲線全体ではなく一部だけの面積を評価する 部分AUC(partial AUC) という考え方が有効です。また診断薬の承認やバイオマーカーqualification(規制当局による有用性の認定)では、AUCの点推定だけでなく、信頼区間と、事前に取り決めたカットオフでの感度・特異度の提示が求められます。「後付けで最良の閾値を選ぶ」のではなく、事前規定(pre-specification)が信頼性の鍵になります。
📚 この記事をより深く理解するための参考書籍
統計・生物統計をさらに深く学びたい方に、診断精度・ROC曲線の理解を助けるおすすめの書籍をご紹介します。






関連記事
- ロジスティック回帰モデルの判別性能をROCで評価する流れの全体像をつかみたい方は、2値変数とロジスティック回帰:理論・実装・解釈までの実践ガイドもあわせてご覧ください。モデル構築からROC評価までが一本につながります。
- 感度・特異度の土台となる2×2分割表の解析を基礎から確認したい方には、分割表の独立性の検定:製薬統計の現場での理論と実装が参考になります。診断精度の指標を支える分割表の考え方が身につきます。
- 「どれだけ効くか・どれだけ判別できるか」を数値で測る指標の発想を広げたい方は、効果量(Effect Size)を理解すると統計が一気に実務的になるもおすすめです。AUCを「判別力の効果量」として捉える視点が得られます。
まとめ
本記事では、診断バイオマーカーや予測モデルの判別性能を、特定の閾値に縛られず総合評価するための道具として、ROC曲線とAUCを学びました。単一カットオフでの感度・特異度が閾値の選び方に左右されてしまうのに対し、ROC曲線はあらゆる閾値での感度と特異度を一枚に描き、AUCはそれを一つの数値へ要約します。RのpROCパッケージを使えば、医療データからROC曲線を描き、AUCとその95%信頼区間を求め、Youden indexで最適カットオフを探し、さらにDeLong検定で2つのバイオマーカーのAUCを比較するところまで、一連の流れを実装できることを確認しました。
実務では、AUCの数値の大小だけで優劣を決めず、カットオフは検査の目的(スクリーニングか確定診断か)に応じて選び、PPV・NPVが有病率に依存することにも注意する——こうした視点が、診断バイオマーカーの評価やロジスティック回帰モデルの性能評価で確かな判断につながります。AUCを点推定だけでなく信頼区間まで含めて報告し、カットオフを事前規定する習慣は、規制対応やバリデーションの場面であなたの強みになります。
判別性能の評価をモデル構築の側からさらに深めたい方は、上で紹介した「2値変数とロジスティック回帰」の記事を、感度・特異度の土台を固めたい方は「分割表の独立性の検定」の記事を続けて読んでいただければと思います。