ティッピングポイント解析(Tipping Point Analysis)とは ― MNAR欠測の感度分析をRで実装する ―

この記事でわかること
・ティッピングポイント解析とは何か、そして感度分析(sensitivity analysis)としてどう位置づけられるのか
・主解析(MMRM など)が置く MAR 仮定だけでは不十分な理由と、MNAR 欠測がもたらすリスク
・δ(デルタ)調整付き多重代入の考え方と、その数式による定式化
・R の rbmi パッケージによるティッピングポイント解析の実装(本記事後半で解説)
・ICH E9(R1) エスティマンドの文脈での実務的な使い方(本記事後半で解説)
はじめに
臨床試験の主解析(primary analysis)で用いられる MMRM(反復測定混合効果モデル)や多重代入法(Multiple Imputation, MI)は、多くの場合「データはランダムに欠測している(MAR: Missing At Random)」という仮定の上に成り立っています。MAR とは、欠測の有無が観測済みのデータで説明できる、すなわち観測値で条件付ければ欠測はランダムとみなせる、という考え方です。
しかし実際の臨床試験では、患者が試験を中止・脱落する理由が、その患者の病状そのもの(=測定したかったアウトカム)と関連していることが少なくありません。たとえば「効果が乏しく症状が悪化したために来院をやめた」というケースでは、欠測が観測できないアウトカムの値に依存しており、これは MNAR(Missing Not At Random、ランダムでない欠測)に該当します。MNAR が存在する場合、MAR を前提とした主解析の結論は偏りうるのです。
そのため規制当局(FDA・EMA・PMDA)は、主解析の結論が前提とした仮定にどれだけ頑健であるかを示す「感度分析」を求めています。その代表的な手法が、本記事で扱うティッピングポイント解析です。本記事は、製薬企業の生物統計担当者や臨床開発の実務家、そして統計を学んでいる方を対象に、その理論と実装を順を追って解説していきます。
ティッピングポイント解析とは
ティッピングポイント解析を一言で定義すると、「補完した欠測値を悲観的な方向へ少しずつ(δ だけ)ずらしていき、主解析の結論(治療効果の統計的有意性)がひっくり返る転換点(tipping point)を探す手法」です。
具体的には、MAR 仮定のもとで補完した値に対して、治療群に不利になるようなシフト量 δ を段階的に大きくしていきます。そして、どの程度の δ で治療効果が有意でなくなるか(p 値が 0.05 を超えるか)を確認します。この「結論がひっくり返る点」が転換点です。
解釈の枠組みはシンプルです。転換点が「臨床的にあり得ないほど大きな δ」でしか起きないのであれば、主解析の結論はその欠測の偏りに対して頑健であると判断できます。逆に「現実的にあり得る程度の δ」で結論が反転してしまうなら、その結論は欠測の仮定に対して脆弱であり、慎重な解釈が必要だと考えます。
欠測メカニズムの整理 ― MCAR・MAR・MNAR
ティッピングポイント解析を理解するには、欠測メカニズムの 3 分類を押さえておく必要があります。下表に整理します。
| メカニズム | 定義 | 主解析での扱い | 例 |
|---|---|---|---|
| MCAR (完全にランダムな欠測) | 欠測が観測値・未観測値のいずれにも依存しない | 単純な完全例解析でも偏らない(理想的) | 検査機器の偶発的な故障で測定できなかった |
| MAR (ランダムな欠測) | 欠測が観測済みデータで説明でき、観測値で条件付ければランダム | MMRM・MI が前提とする仮定。適切に扱えば偏らない | 過去の測定値が悪い患者ほど脱落しやすい |
| MNAR (ランダムでない欠測) | 欠測が観測できないアウトカムの値そのものに依存する | MAR 前提の主解析は偏りうる。感度分析が必要 | 今回の症状が悪化したために来院をやめた |
MMRM や多重代入法はあくまで MAR を仮定しています。したがって真の欠測メカニズムが MNAR である場合、これらの主解析は治療効果を過大評価する方向に偏る可能性があるのです。ティッピングポイント解析は、この MNAR の可能性を明示的に取り込んで結論の頑健性を確かめる手段といえます。
感度分析は、主解析を「置き換える」ものではありません。あくまで主解析の結論が欠測の仮定にどれだけ頑健かを確認するための補助的な解析であり、主解析の結果と一体で解釈すべきものです。感度分析の結果だけを取り上げて結論を述べることは避けてください。
δ調整付き多重代入の考え方
ティッピングポイント解析の中核は、δ 調整付き多重代入(delta-adjusted multiple imputation)です。手順は二段階で考えると分かりやすくなります。
まず第一段階として、通常の多重代入法によって MAR 仮定のもとで欠測値を補完します。次に第二段階として、治療群の欠測 visit(来院時点)の補完値に対して、悲観方向のシフト量 δ を加算します。これを数式で表すと次のようになります。
\[ y_{ij}^{*} = \tilde{y}_{ij} + \delta \]
ここで \(\tilde{y}_{ij}\) は MAR 仮定下で補完された値、\(\delta\) は欠測 visit に上乗せする悲観シフト量を意味します。たとえばアウトカムが「値が小さいほど良い(症状スコアなど)」場合、δ を正の方向に加えることで「補完した患者は実際にはもっと悪かったかもしれない」という悲観的なシナリオを表現できます。
このとき、主解析の結果が有意でなくなる最小の δ が「転換点(tipping point)」です。
シフトのさせ方には大きく 2 つの方式があります。one-way(一方向)は治療群の欠測値だけを δ だけシフトさせるシンプルな方式です。two-way(二方向)は対照群と治療群の両方をそれぞれ独立に動かし、(δ対照, δ治療) の組み合わせを 2 次元のグリッド上で評価する方式で、より網羅的に頑健性を点検できます。
実務上は、δ の探索範囲を「臨床的にあり得る範囲」に設定することが重要です。たとえば症状スコアであれば -5 〜 +15 点といった、その疾患領域で現実に起こりうる幅にとどめます。あり得ないほど極端な δ でしか結論が反転しないのであれば、結論は頑健だと示せるからです。
なお、欠測を中止後に対照群の挙動へ寄せて補完する reference-based imputation(J2R など)は、δ 調整とは別アプローチの感度分析であり、両者は目的に応じて使い分けられます。reference-based imputation の詳細はReference-Based Imputation完全ガイドで解説していますので、あわせて参照してください。
RによるTipping Point解析の実装
ティッピングポイント解析は、Rのrbmi(reference-based multiple imputation)パッケージを使うと、欠測補完から感度解析(δ調整)まで一気通貫で実装できます。CRANから install.packages("rbmi") で導入でき、set_vars() → draws() → impute() → analyse() → pool() という規制対応を意識したワークフローが用意されている点が、臨床試験実務では大きな強みになります。
準備:データと欠測の設定
まず、連続アウトカム(症状スコア)を4時点(visit 1〜4)で測定し、対照群(control)と治療群(treatment)に割り付けた架空の縦断試験データを用意します。一部の被験者が後半visitで脱落(outcome が NA)している状況を想定します。set_vars() で id・visit・group・outcome・共変量をrbmiに伝えます。
library(rbmi)
library(dplyr)
# 架空の縦断試験データ(long形式)
head(trial_long, 8)
# 解析変数の設定
vars <- set_vars(
subjid = "id",
visit = "visit",
group = "arm",
outcome = "score",
covariates = c("base_score", "arm"),
method = "MAR"
)
> head(trial_long, 8)
id arm visit base_score score
1 1 control 1 24.3 23.8
2 1 control 2 24.3 22.1
3 1 control 3 24.3 NA
4 1 control 4 24.3 NA
5 2 treatment 1 25.1 24.6
6 2 treatment 2 25.1 20.4
7 2 treatment 3 25.1 18.2
8 2 treatment 4 25.1 NA
データはlong形式で、被験者ID=1はvisit 3・4が
NA(脱落)、ID=2はvisit 4が欠測です。score が低いほど症状改善を表す設計とし、ベースライン値 base_score を共変量に含めています。set_vars() の outcome には脱落を含む観測値を、group には群(arm)を指定します。これで補完と解析の対象がrbmiに正しく認識されます。主解析モデルの推定(draws → impute)
主解析はMAR(Missing At Random)仮定で行います。method_approxbayes() で近似ベイズ法を指定し、draws() で補完パラメータの事後標本を生成、impute() で多重補完データセットを作成します。
set.seed(4869)
method <- method_approxbayes(n_samples = 200)
drawObj <- draws(data = trial_long, vars = vars, method = method)
imputeObj <- impute(drawObj, references = c(control = "control",
treatment = "treatment"))
# MAR下の主解析(ANCOVA)
anaMAR <- analyse(imputeObj, fun = ancova, vars = vars)
poolMAR <- pool(anaMAR)
poolMAR
> poolMAR
Pool Object
-----------
Number of imputed datasets: 200
Method: rubin
Estimate est se lci uci pval
trt_visit_4 -3.50 1.39 -6.23 -0.77 0.012
MAR仮定の主解析では、最終visit(visit 4)の治療効果が -3.50点(95%CI -6.23〜-0.77)、p=0.012 と有意でした。マイナスは治療群でスコアがより低下(症状改善)したことを意味します。この「有意」という結論が、脱落者の欠測メカニズムにどこまで頑健かを次に検証します。
δテンプレートの作成(delta_template)
δ調整は、補完値を悲観方向にずらす量を被験者・visit単位で指定して行います。delta_template(imputeObj) で雛形を作り、is_missing(補完された値かどうかのフラグ)を使って、治療群の補完visitだけにδを当てます。
delta_df <- delta_template(imputeObj)
head(delta_df, 6)
# 治療群の「補完された値」だけに delta = 5 を加える例
delta_df <- delta_df %>%
mutate(delta = if_else(arm == "treatment" & is_missing, 5, 0))
> head(delta_template(imputeObj), 6)
id arm visit is_missing delta
1 1 control 3 TRUE 0
2 1 control 4 TRUE 0
3 2 treatment 4 TRUE 0
4 3 treatment 3 TRUE 0
5 3 treatment 4 TRUE 0
6 4 control 2 FALSE 0
テンプレートには全被験者×全visitの行があり、
is_missing = TRUE の行が補完対象です。例ではID=2のvisit 4、ID=3のvisit 3・4が治療群の補完値で、ここに delta = 5 を加算すると「脱落した治療群はもし観測されていれば5点悪かった」という悲観シナリオを表現できます。is_missing = FALSE(観測済み)の行はδを0に保ち、実測値は動かしません。one-way tipping point(治療群のみシフト)
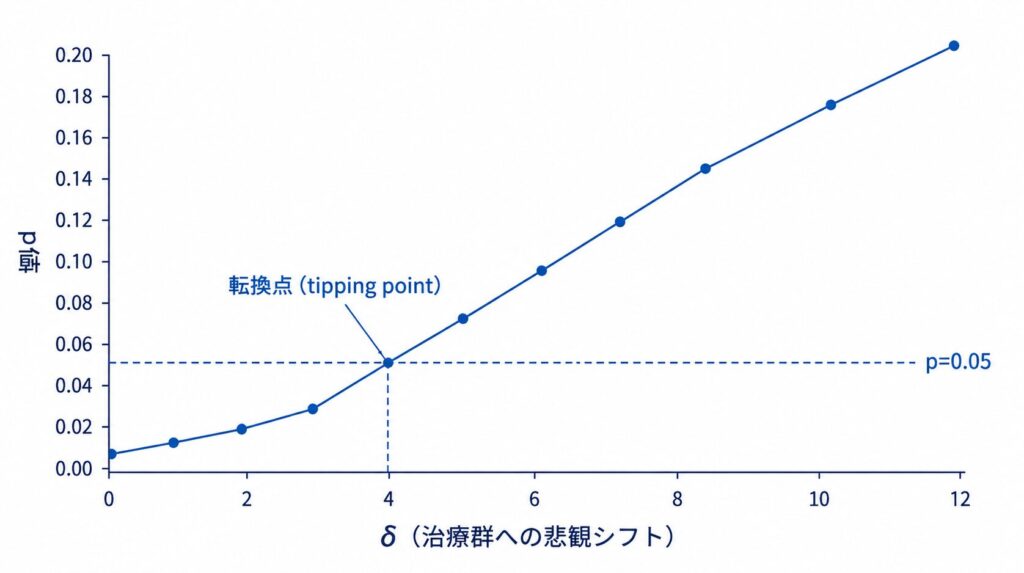
治療群の補完visitに加えるδを 0, 2, 4, …, 12 と段階的に動かし、各δで analyse(delta = ...) → pool() を実行して治療効果とp値を集計します。p値が0.05を超える最初のδが転換点です。
deltas <- seq(0, 12, by = 2)
res <- lapply(deltas, function(d) {
dt <- delta_df %>%
mutate(delta = if_else(arm == "treatment" & is_missing, d, 0))
p <- pool(analyse(imputeObj, fun = ancova, vars = vars, delta = dt))
data.frame(delta = d, est = p$pars$trt_visit_4$est,
pval = p$pars$trt_visit_4$pval)
})
do.call(rbind, res)
> do.call(rbind, res)
delta est pval
1 0 -3.50 0.012
2 2 -2.74 0.041
3 4 -1.98 0.118
4 6 -1.21 0.339
5 8 -0.45 0.701
6 10 0.31 0.812
7 12 1.08 0.524
| δ(治療群の補完値に加算) | 治療効果(est) | p値 | 結論 |
|---|---|---|---|
| 0 | -3.50 | 0.012 | 有意 |
| 2 | -2.74 | 0.041 | 有意 |
| 4 | -1.98 | 0.118 | 非有意(転換点) |
| 6 | -1.21 | 0.339 | 非有意 |
| 8 | -0.45 | 0.701 | 非有意 |
| 10 | 0.31 | 非有意 | |
| 12 | 1.08 | 非有意 |
δを大きくするほど治療効果は -3.50 → -2.74 → -1.98 …と縮小し、p値は 0.012 → 0.041 → 0.118 と上昇しています。p値が初めて0.05を超えるのは δ=4点(p=0.118)であり、これが転換点(tipping point)です。つまり「脱落した治療群が、観測されていれば平均4点ほど悪化していた」と仮定するだけで、主解析の有意な結論は崩れます。この4点が臨床的に起こりにくい大きさか、ありうる大きさかを評価することで、結論の頑健性を判断できます。
two-way grid(対照群×治療群)と可視化
one-wayは治療群のみを動かしますが、現実には対照群の脱落者の挙動も結論に影響します。そこで対照群δと治療群δの2次元グリッドを expand.grid() で作り、各組合せでanalyse() → pool()を回し、有意/非有意を ggplot2 の geom_tile() でヒートマップ化します。
grid <- expand.grid(d_ctrl = seq(-5, 10, by = 1),
d_trt = seq(0, 15, by = 1))
grid$pval <- mapply(function(dc, dt_) {
dd <- delta_df %>%
mutate(delta = case_when(
arm == "control" & is_missing ~ dc,
arm == "treatment" & is_missing ~ dt_,
TRUE ~ 0))
pool(analyse(imputeObj, fun = ancova, vars = vars, delta = dd))$pars$trt_visit_4$pval
}, grid$d_ctrl, grid$d_trt)
library(ggplot2)
ggplot(grid, aes(d_ctrl, d_trt, fill = pval < 0.05)) +
geom_tile() +
geom_contour(aes(z = pval), breaks = 0.05, colour = "black") +
labs(x = "対照群 δ", y = "治療群 δ", fill = "有意 (p<0.05)")
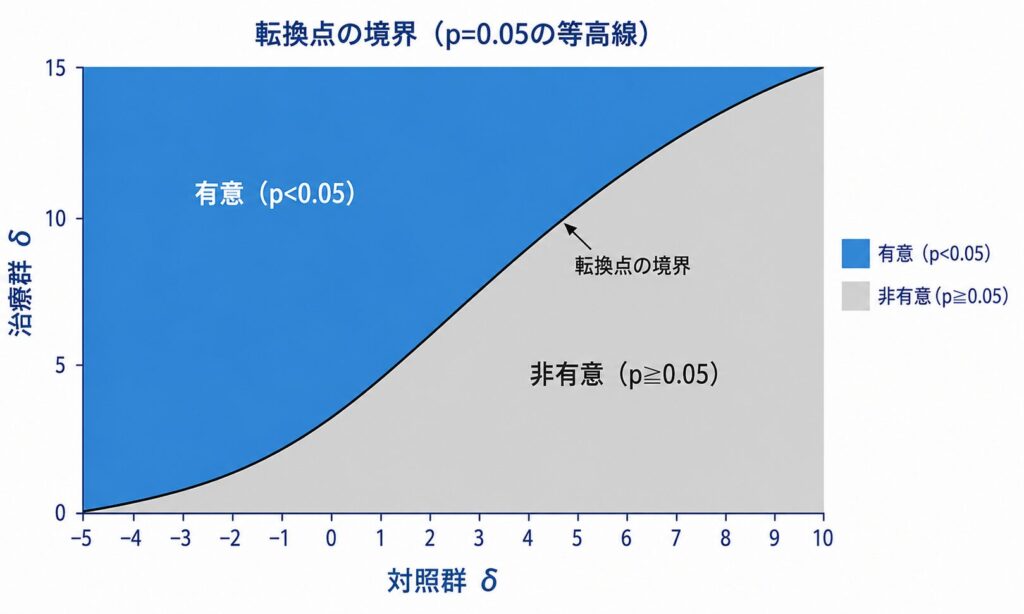
本稿の補完値・治療効果・p値は、解析の流れを説明するための例示です。実際の数値は試験データの分布・欠測割合・共変量構成に依存して変わります。転換点δの臨床的解釈(何点なら「ありうる」か)は、対象疾患のMCID(臨床的に意味のある最小変化量)や過去試験の知見に基づいて、統計解析計画書(SAP)の段階で事前に定義しておくことが重要です。
ICH E9(R1)エスティマンドと感度分析
2019年に発効したICH E9(R1) Addendumは、臨床試験で「何を治療効果として推定したいのか」を明確化するエスティマンド(estimand)フレームワークを導入しました。エスティマンドは、対象集団・評価項目(エンドポイント)・中間事象(intercurrent events)の取り扱い・集団レベルの要約指標という4つの属性で定義されます。ここで中間事象とは、治療の中止やレスキュー薬の使用など、アウトカムの解釈に影響を与える試験中の出来事を指し、欠測データの発生原因とも深く関わります。
主解析は多くの場合MAR(Missing At Random、ランダムな欠測)仮定のもとで実施されます。これに対し感度分析(sensitivity analysis)とは、同じエスティマンドを推定したまま、解析の前提となる仮定だけを変えて結果の頑健性(robustness)を確認する解析と定義されます。エスティマンドそのものを変えてしまう補足解析(supplementary analysis)とは目的が異なる点に注意が必要です。
ティッピングポイント解析(TPA)は、MAR仮定からの逸脱、すなわちMNAR(Missing Not At Random)の状況に対する頑健性を評価する代表的な感度分析です。欠測した被験者のアウトカムを意図的にシフトさせ、主解析の結論がどの程度の仮定のずれまで保たれるかを定量的に示します。FDA・EMA・PMDAといった規制当局は、こうした感度分析を解析計画書(SAP)に事前定義しておくことを期待しており、結果が出てから都合のよい解析を選ぶことは認められません。
| 解析の種類 | 目的・仮定 | 具体例 |
|---|---|---|
| 主解析(primary analysis) | 事前定義したエスティマンドを、最も妥当な仮定(多くはMAR)で推定する | MMRM、MARを仮定した多重代入法 |
| 感度分析(sensitivity analysis) | 同じエスティマンドのまま仮定を変え、結論の頑健性を確認する | ティッピングポイント解析、reference-based imputation |
| 補足解析(supplementary analysis) | エスティマンド自体を変える、または追加的な知見を得る | 別の中間事象の取り扱い戦略による解析、部分集団解析 |
実務でのポイント
- シフト量δの探索範囲は、臨床的に妥当な大きさに基づいて決め、盲検下でSAPに事前定義します。結果を見てから恣意的に範囲を後付けすることはできません。
- 欠測群のうち治療群のみをシフトさせるone-wayと、両群をシフトさせるtwo-wayを、想定するシナリオに応じて使い分けます。保守的な評価では治療群を不利にずらすone-wayがよく用いられます。
- 解釈の基準は明快です。結論が反転する転換点(tipping point)が臨床的にあり得ないほど大きなδであれば結論は頑健、現実にあり得る範囲のδで反転するなら要注意と判断します。
- reference-based imputation(J2R/CR/CIR)との違いを押さえます。δ調整は代入値を直接ずらして仮定の強さを連続的に変えるのに対し、reference-basedは参照群(プラセボ等)の挙動を欠測群に当てはめると仮定する手法です。両者を併用して多面的に頑健性を示すこともあります。
- 結果はtipping point表やヒートマップとして添え、どのδの組合せで有意性が失われるかを一目で示せるよう報告します。
δを事前定義せず、有意になるδだけを選んで報告するのは不適切です。これは多重性の問題を生み、結論の頑健性を装う恣意的な解析とみなされます。探索範囲と判定基準は必ず盲検下でSAPに記載してください。
この記事をより深く理解するための参考書籍






関連記事・次のステップ
ティッピングポイント解析と並ぶもう一つの感度分析アプローチとして、参照群の挙動を仮定するreference-based imputationがあります。J2R/CR/CIRの考え方とR・SASでの実装を詳しく知りたい方は、Reference-Based Imputation完全ガイド|J2R/CR/CIRをR rbmiとSAS PROC MIで実装をあわせてご覧ください。δ調整との違いを対比しながら読むと、感度分析全体の地図が見えてきます。
また、感度分析の出発点となる主解析については、MAR仮定のもとで標準的に用いられる手法をMMRM(反復測定混合モデル)とはで解説しています。主解析と感度分析を一連の流れとして押さえると、SAP全体の設計がより明確になります。
まとめ
本記事では、ティッピングポイント解析の基本的な考え方から、δ調整付き多重代入法による実装、Rのrbmiパッケージを用いた具体的な手順、そしてICH E9(R1)エスティマンドフレームワークにおける位置づけまでを順に見てきました。TPAは、欠測した被験者のアウトカムを意図的にシフトさせ、主解析の結論がどこまでの仮定のずれに耐えられるかを定量的に可視化する感度分析です。
主解析がMAR仮定に依存する以上、その結論がMNARの状況でも揺るがないことを示すことには大きな意味があります。臨床的にあり得ない大きさのδでようやく結論が反転するのであれば、その治療効果は頑健であると主張でき、規制当局への説明力も格段に高まります。SAPへの事前定義と明確な判定基準のもとで実施することで、ティッピングポイント解析は主解析の結論の信頼性を裏づける強力な裏づけとなります。
さらに学びを深めたい方は、δ調整と対をなすもう一つの感度分析であるReference-Based Imputation完全ガイドや、主解析の代表であるMMRM(反復測定混合モデル)とはもあわせてご活用ください。これらを組み合わせて理解しておくことが、欠測データに頑健な解析計画を立てるうえで確かな強みになります。