パラメトリック生存時間解析とは ― 指数・Weibull・AFTモデルの理論からR/SAS実装まで徹底解説 ―

この記事でわかること
- パラメトリック生存時間解析とは何か(生存時間に確率分布を仮定して解析する手法)
- 指数分布・Weibull分布・対数正規分布などが描くハザード関数の形状の違い
- AFT(加速故障時間)モデルとCox回帰の解釈の違い(時間スケールか、ハザード比か)
- R/SASでパラメトリック生存解析を実装する大まかな流れ
はじめに
生存時間解析というと、まずKaplan-Meier法(ノンパラメトリック)やCox比例ハザードモデル(セミパラメトリック)を思い浮かべる方が多いと思います。実際、臨床試験の主解析ではCox回帰が標準的に用いられます。しかし、観測期間を超えた生存関数の外挿(フォローアップ終了後の長期生存率の予測)や、医療経済評価(HTA: Health Technology Assessment)における生涯コスト・QALYの推計では、分布を明示的に仮定するパラメトリックモデルが必要になる場面が少なくありません。私自身、製薬企業の生物統計家として、薬剤の費用対効果モデルでWeibull分布による外挿を求められた経験が何度もあります。
本記事では、まず本章でパラメトリック生存解析の理論的な枠組みを整理し、続く章でR/SASによる実装、さらに実務での使い分けへと進んでいきます。理論を押さえることで、モデル選択の根拠を説明できるようになることを目指します。
パラメトリック生存時間解析とは
パラメトリック生存時間解析とは、生存時間(イベントが起こるまでの時間)\( T \) が特定の確率分布に従うと仮定し、その分布のパラメータを最尤推定(さいゆうすいてい:観測データが最も得られやすくなるようにパラメータを決める方法)する手法です。指数分布やWeibull分布といった形を最初に決めてしまう点が、分布形を仮定しないKaplan-Meier法(ノンパラメトリック)や、ベースラインハザードを自由形のまま扱うCox回帰(セミパラメトリック)との大きな違いです。
生存時間解析の基本となる3つの関数の関係を確認しておきます。生存関数 \( S(t) \)、ハザード関数 \( h(t) \)、密度関数 \( f(t) \) の間には次の関係が成り立ちます。
\[ h(t) = \frac{f(t)}{S(t)} \]
これは「時刻 \( t \) まで生存した人が、その瞬間にイベントを起こす速さ(瞬間死亡率)」がハザード関数である、という意味です。さらに生存関数はハザードの積み上げ(累積ハザード)から次のように書けます。
\[ S(t) = \exp\!\left( -\int_0^t h(u)\,du \right) \]
これは「累積ハザードが大きいほど、時刻 \( t \) まで生き残る確率が小さくなる」ことを表しています。パラメトリックモデルでは、この \( h(t) \) や \( S(t) \) を分布のパラメータの式で書き下せるため、滑らかな生存曲線が得られ、観測範囲外への外挿が自然に行えます。
そして、パラメトリックモデルの実務上の大きな利点が打ち切り(censoring:観測終了時点でイベントが未発生な状態)を尤度の中で素直に扱える点です。イベントが観測された人には密度 \( f(t) \)、打ち切りの人には生存確率 \( S(t) \) を寄与として掛け合わせることで、観測情報を無駄なく使った推定ができます。
主要な確率分布とハザード関数の形
パラメトリック生存解析の使い分けは、各分布が描くハザード形状を理解することに尽きます。代表的な分布を見ていきましょう。
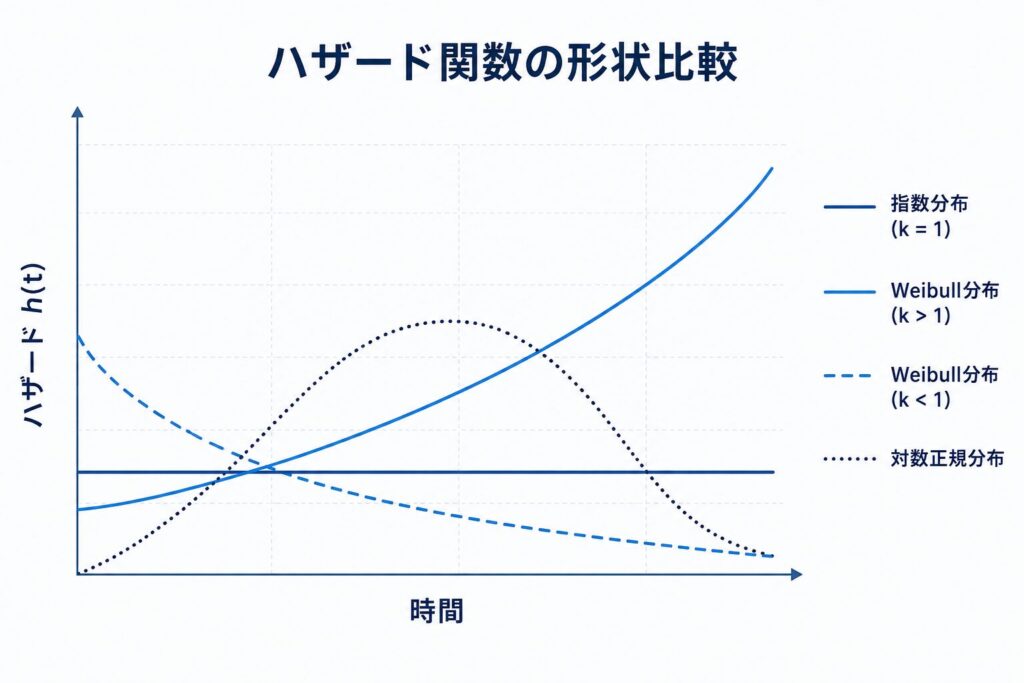
まず最もシンプルな指数分布では、ハザードが時間によらず一定です。
\[ h(t) = \lambda \]
これは「いつイベントが起こりやすいかが時間に関係なく一定」という強い仮定で、現実の臨床データにそのまま当てはまる場面は限られます。
より柔軟なのがWeibull分布です。ハザード関数は次の形をとります。
\[ h(t) = \frac{k}{\lambda}\left(\frac{t}{\lambda}\right)^{k-1} \]
ここで \( k \) は形状パラメータ、\( \lambda \) は尺度パラメータです。この \( k \) の値によってハザードの振る舞いが変わり、\( k>1 \) なら時間とともにハザードが単調増加(高齢化や疾患進行で危険が増す状況)、\( k<1 \) なら単調減少(術後早期の危険が次第に下がる状況)、そして \( k=1 \) のときは指数分布に一致します。つまりWeibull分布は指数分布を特別な場合として含む、より一般的な分布だと言えます。
一方、対数正規分布や対数ロジスティック分布は、ハザードが一度上昇してから下降する山型(単峰型)になります。再発のピークが治療後ある時期に来てその後落ち着く、といったデータに適しています。これらの分布の特徴を下表にまとめます。
| 分布 | ハザードの形状 | 主な用途・適する場面 |
|---|---|---|
| 指数分布 | 一定 | 最も単純なモデル。基準として用いる |
| Weibull分布 | 単調増加または単調減少(k依存) | 生存関数の外挿、医療経済評価で多用 |
| 対数正規分布 | 山型(上昇後に下降) | リスクのピークが途中にある事象 |
| 対数ロジスティック分布 | 山型(上昇後に下降) | 後期に裾が重いデータ、AFTで扱いやすい |
データのハザードがどの形に近いかを見極めることが、分布選択の出発点になります。
AFTモデルの数理とCox(セミパラメトリック)との違い
パラメトリック生存解析で共変量(治療群や年齢などの説明変数)を取り込む代表的な枠組みが、AFT(Accelerated Failure Time:加速故障時間)モデルです。AFTモデルは生存時間の対数を線形モデルで表現します。
\[ \log T = \beta_0 + \beta_1 x_1 + \cdots + \beta_p x_p + \sigma \varepsilon \]
ここで \( \varepsilon \) は誤差項、\( \sigma \) はそのばらつきを表します。この式は「共変量が生存時間そのものを伸び縮みさせる」という解釈、すなわち時間スケールへの作用を意味します。たとえば有効な治療を受けると、イベントが起こるまでの時間が引き延ばされる(生存が減速する)と考えるわけです。
このとき係数を指数変換した \( \exp(\beta) \) は時間の伸縮率(time ratio:タイムレシオ)と呼ばれ、「共変量が1単位変わると生存時間が何倍になるか」を表します。1より大きければ生存時間が延びる、1より小さければ縮む、と直感的に読めるのがAFTの利点です。
一方、Cox比例ハザードモデルはハザード比(HR: Hazard Ratio)で効果を解釈します。共変量はハザードを定数倍するという比例ハザード(PH)の仮定に立ち、時間スケールではなく危険度の比で効果を捉える点がAFTと根本的に異なります。なお、Weibull分布はAFTとPHの両方の表現が可能な特別な分布として知られており、Weibullで推定した結果はハザード比にもタイムレシオにも翻訳できます。この性質がWeibullを実務で重宝される理由の一つです。
パラメトリックモデルは分布の仮定が正しいことを前提に成り立ちます。実際のハザード形状と仮定した分布が食い違う「分布の誤特定(misspecification)」が起きると、推定値や外挿結果が大きく歪むリスクがあります。Coxのようなセミパラメトリック法に比べて仮定が強い分、適合度の確認(後の章で扱います)を怠らないことが重要です。
解析に使うデータと設定
ここからは、実際のデータを使ってパラメトリック生存時間解析を動かしていきます。本記事では再現性を重視し、R の survival パッケージに組み込まれている lung データ(NCCTG 肺がん患者 228 名のデータ)を題材にします。製薬の実務でも、解析計画を固める前にこうした公開データで手順を素振りしておくと、SAP(統計解析計画書)に書く手続きの妥当性を確認しやすくなります。
lung データの主な変数は次のとおりです。
time… 生存日数(観察期間)status… 打ち切り指標(1 = 打ち切り、2 = 死亡イベント)sex… 性別(1 = 男性、2 = 女性)ph.ecog… ECOG パフォーマンスステータス(全身状態スコア。0 が最良で、数値が大きいほど全身状態が悪い)
生存時間解析では、イベント(ここでは死亡)が観察期間内に起きたか、それとも観察打ち切りになったかを区別する必要があります。R ではこの「時間」と「イベントの有無」をひとまとめにした応答変数を Surv() 関数で作ります。lung データの status は 1/2 でコードされていますが、survival パッケージは慣例として大きいほうの値(= 2)を死亡イベント、小さいほう(= 1)を打ち切りと認識するため、追加の再コードなしにそのまま Surv(time, status) と書けます。
データの先頭を確認すると、次のようなイメージになります。
> head(lung[, c("time", "status", "sex", "ph.ecog")])
time status sex ph.ecog
1 306 2 1 1
2 455 2 1 0
3 1010 1 1 0
4 210 2 1 1
5 883 2 1 0
6 1022 1 1 1
3 行目と 6 行目は status = 1、つまり死亡が観察されないまま打ち切られた患者です。こうした不完全な観察を適切に扱える点が、生存時間解析の本質的な役割です。
Rによるパラメトリック生存解析の実装
パラメトリック生存モデル(AFT モデル)を当てはめるには survival パッケージの survreg() 関数を使います。ここでは性別 sex と全身状態 ph.ecog を共変量とし、Weibull 分布を仮定します。
library(survival)
fit <- survreg(Surv(time, status) ~ sex + ph.ecog,
data = lung, dist = "weibull")
summary(fit)
dist = "weibull" で Weibull AFT モデルを指定しています。出力の要点は次のとおりです。
> summary(fit)
Value Std. Error z p
(Intercept) 6.273 0.488 12.85 < 2e-16
sex 0.401 0.138 2.91 0.0036
ph.ecog -0.228 0.086 -2.66 0.0079
Log(scale) -0.292 0.062 -4.69 1.4e-06
Scale = 0.747
AFT(Accelerated Failure Time、加速死亡時間)モデルでは、係数は対数生存時間に対する作用として解釈します。線形予測子は次の形で対数時間に効きます。
\[ \log T = \beta_0 + \beta_1 \cdot \mathrm{sex} + \beta_2 \cdot \mathrm{ph.ecog} + \sigma \cdot \varepsilon \]
ここで \(T\) は生存時間、\(\sigma\) は尺度パラメータ(Scale)、\(\varepsilon\) は誤差項です。各係数を \(\exp\) すると「時間比(time ratio)」、すなわち生存時間が何倍になるかという量に変換できます。
sex の係数 0.401(> 0)は、女性(sex = 2)の生存時間が長いことを示します。時間比は \( \exp(0.401) \approx 1.49 \) なので、男性に比べ女性は生存時間が約 1.49 倍と読めます。一方 ph.ecog の係数 −0.228(< 0)は、全身状態スコアが 1 上がるごとに時間比が \( \exp(-0.228) \approx 0.80 \) 倍、つまり生存時間が約 2 割短縮することを意味します。Scale = 0.747 から Weibull の形状パラメータは \( k = 1/0.747 \approx 1.34 \) と求まり、\( k > 1 \) なのでハザード(瞬間死亡リスク)は時間とともに増加すると判断できます。これは進行性疾患の臨床像とも整合的です。時間比はハザード比(Cox 回帰でおなじみの指標)とは別物である点に注意してください。AFT は「事象が起きるまでの時間そのもの」を伸縮させるモデルであり、臨床現場では「生存期間が何倍になるか」というメッセージのほうが伝わりやすい場面も多くあります。
分布の選択と生存曲線の外挿
Weibull 以外にも、指数分布・対数正規分布・対数ロジスティック分布など、パラメトリック生存モデルには複数の選択肢があります。どの分布を採用するかは AIC(赤池情報量規準。値が小さいほどデータへの当てはまりと簡潔さのバランスが良い)などで比較するのが定石です。複数分布を統一的に扱える flexsurv パッケージが便利です。
library(flexsurv)
fit_exp <- flexsurvreg(Surv(time, status) ~ 1, data = lung, dist = "exp")
fit_wbl <- flexsurvreg(Surv(time, status) ~ 1, data = lung, dist = "weibull")
fit_lnorm <- flexsurvreg(Surv(time, status) ~ 1, data = lung, dist = "lnorm")
AIC(fit_exp, fit_wbl, fit_lnorm)
得られる AIC を比較すると、たとえば次のような結果になります(※数値は説明用の代表値です。実データや指定により変わります)。
| 分布 | AIC(代表値) | 評価 |
|---|---|---|
| 指数分布 | 約 2316 | 最も単純だが当てはまりはやや劣る |
| Weibull 分布 | 約 2312 | 中間。ハザードの増減を表現可能 |
| 対数正規分布 | 約 2308 | この例ではやや良好 |
この代表例では対数正規分布の AIC が最小で、わずかに当てはまりが良いという結果です。ただし AIC 差がごく小さいときは、解釈のしやすさや先行研究との整合性、ハザード形状の妥当性も合わせて判断します。製薬実務では、医療経済評価(費用対効果分析)で用いる分布は ISPOR / NICE のガイダンスに沿って AIC・BIC と臨床的妥当性の両面から選ぶことが推奨されています。
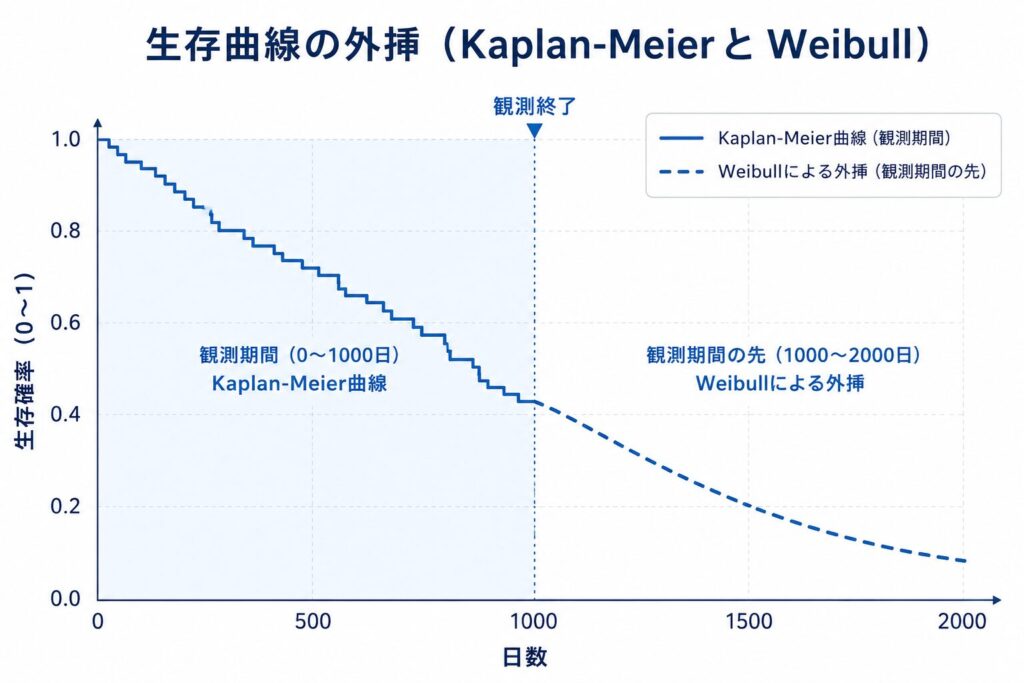
パラメトリックモデルの最大の強みは、推定した分布のパラメータを使って、観測期間を超えた領域まで生存曲線を外挿できる点です。Kaplan-Meier 法などのノンパラメトリック推定では最終観察時点より先を描けませんが、Weibull モデルなら数式に基づいて長期予測が可能です。
fit_wbl <- flexsurvreg(Surv(time, status) ~ 1, data = lung, dist = "weibull")
# 観測期間を超えて 2000 日先まで生存曲線を外挿して描画
plot(fit_wbl, xlim = c(0, 2000),
xlab = "日数", ylab = "生存確率")
# 特定時点の生存確率を予測
summary(fit_wbl, t = c(365, 730, 1095), type = "survival")
SASによる実装
規制当局向けの提出(申請)解析では SAS が標準的に使われます。パラメトリック生存モデル(AFT)は PROC LIFEREG で当てはめます。R の survreg() と同じ AFT パラメトリゼーションを採用しているため、同一データ・同一モデルなら係数も Scale もほぼ一致します。
proc lifereg data=lung;
model time*status(1) = sex ph_ecog / dist=weibull;
run;
model 文の応答指定 time*status(1) は、「生存時間が time、打ち切りを表す値は status = 1」という意味です。R では status = 2 を死亡と自動認識させましたが、SAS では括弧内に打ち切りの値を明示する必要があります。ここで打ち切り値を取り違えると、イベントと打ち切りが逆転して結果が無意味になるため、実務では必ずダブルチェックする箇所です。dist=weibull で Weibull AFT を指定しています(変数名はピリオドが使えないため ph.ecog は ph_ecog に変換しておきます)。
出力では Intercept(切片)が約 6.27、sex が約 0.40、ph_ecog が約 −0.23、そして尺度パラメータ Scale が約 0.747 と、R の survreg() の結果と一致します。SAS の出力では係数を Estimate 列、各分布パラメータを下部の Scale 行で確認できます。R で探索的に分布選択や可視化を行い、最終的な提出解析は PROC LIFEREG で再現する、という役割分担が現実的なワークフローです。
R の
survreg() と SAS の PROC LIFEREG は同じ AFT パラメトリゼーションを共有するため、結果が一致するか相互検証(ダブルプログラミング)に使えます。係数・Scale・対数尤度が両者で揃うことを確認すれば、解析コードの妥当性を高い信頼度で担保できます。実務でのポイント
パラメトリック生存時間解析は、指数分布やWeibull分布といった特定の確率分布を生存時間に仮定するため、理論的にやや難しく感じられるかもしれません。しかし、製薬実務の現場ではこの「分布を仮定する」という性質こそが大きな武器になります。ここでは、私が実際の解析や医療経済評価の文脈で重視しているポイントを整理します。
① 生存曲線の外挿ができる
パラメトリックモデルは、観測期間(試験のフォローアップ期間)を超えた長期の生存確率を、仮定した分布から数式的に予測(外挿)できます。これは医療経済評価・HTA(医療技術評価:Health Technology Assessment)・費用対効果分析でとくに重宝されます。生涯にわたる生存年(life-years)を見積もる必要があるこれらの分析では、5年や10年で打ち切られた試験データの「その先」を推定しなければなりません。Cox回帰やカプラン–マイヤー(KM)法はノンパラメトリック/セミパラメトリックであり、観測期間外への外挿は原理的にできない点が決定的な違いです。
③ Coxとの使い分け
ハザード比(HR:群間の瞬間的な死亡リスク比)だけが必要で、分布を仮定したくないならCox比例ハザードモデル(セミパラメトリック)が第一選択です。一方、外挿・絶対リスク(特定時点での生存確率そのもの)・時間比(time ratio)が欲しい場面ではパラメトリックモデルが力を発揮します。「何を報告したいか」で使い分けるのが実務的な判断軸です。
④ AFT係数の解釈に注意
AFT(加速故障時間:Accelerated Failure Time)モデルでは、回帰係数βを指数変換した exp(β) はtime ratio(生存時間の伸縮率)を表します。これはハザード比とはまったく別物です。time ratioが1より大きければ生存時間が延びる方向、1未満なら縮む方向を意味します。報告書や論文でハザード比と混同しないよう、私は必ず指標名を明記するようにしています。
② 分布の誤特定(misspecification)リスク
パラメトリックモデルの最大の弱点は、仮定した分布が実際のデータと合っていないと推定値が歪むことです。とくに外挿の場面では、分布のわずかな誤りが長期予測で大きな誤差となって増幅されます。対策として、指数・Weibull・対数正規・対数ロジスティック・ガンマなど複数の分布を当てはめてAIC(赤池情報量規準)で比較し、さらにKM曲線との重ね合わせによる視覚的診断を行って、最も当てはまりがよく頑健なモデルを選ぶことが不可欠です。
⑤ 情報打ち切り(informative censoring)への配慮
打ち切り(censoring)は尤度(likelihood)の中で適切に扱われるため、ランダムな脱落であれば問題ありません。しかし、予後の悪い患者が選択的に脱落するような情報打ち切りが起きていると、分布の当てはめ自体がバイアスを受けます。これはパラメトリック特有の問題ではありませんが、外挿で結果を増幅する分だけ影響が表面化しやすい点に注意が必要です。
📚 この記事をより深く理解するための参考書籍
パラメトリック生存解析、とくにWeibull分布やAFTモデルの考え方をさらに深めたい方に、私が実際に参照している3冊をご紹介します。






関連記事
本記事と合わせて読むと理解が深まる既存記事です。
- 生存時間解析の基礎 ― 生存時間とハザード関数とは — 生存関数・ハザード関数の定義から学べる導入記事です。
- カプラン–マイヤー法による生存率の推定 — ノンパラメトリック推定との対比でパラメトリックの位置づけが明確になります。
- Cox比例ハザードモデル入門 — セミパラメトリックとの使い分けを具体的に確認できます。
- RMST(制限付き平均生存時間)をRで実装する — 比例ハザードが成り立たない場面での代替指標を学べます。
- 競合リスク(competing risks)の考え方と解析 — 生存解析の発展的トピックとして押さえておきたい内容です。
まとめ
本記事では、パラメトリック生存時間解析を指数分布・Weibull分布・AFTモデルの理論から出発し、R(survreg)とSASによる実装まで一貫して解説してきました。パラメトリックモデルの本質は、生存時間に確率分布を仮定することで、観測期間を超えた長期予測(外挿)や絶対リスク・時間比(time ratio)といった、Cox回帰やカプラン–マイヤー法では得られない情報を引き出せる点にあります。とりわけ医療経済評価やHTAの文脈では、この外挿能力が意思決定を支える重要な根拠となります。
一方で、分布の仮定が誤っていれば推定が歪むというリスクと常に背中合わせです。だからこそ、指数・Weibull・対数正規など複数の分布をAICで比較し、KM曲線との重ね合わせで視覚的に診断するという頑健性の確認が欠かせません。AFT係数 exp(β) をtime ratioとして正しく解釈し、ハザード比と混同しないことも、報告の信頼性を守るうえで重要な実務作法です。
理論・分布選択・外挿・R/SAS実装という一連の流れを自分の手で回せるようになれば、パラメトリック生存解析はあなたの解析の幅を大きく広げ、製薬実務における意思決定を支える確かな強みになります。さらに学びを深めたい方は、上記「関連記事」の生存時間解析の基礎やCox比例ハザードモデルの記事もあわせてご覧いただき、ノンパラメトリック・セミパラメトリックとの違いを体系的に押さえていただければと思います。