順序ロジスティック回帰(比例オッズモデル)とは ― 順序カテゴリのアウトカムをRで解析する ―

この記事でわかること
・順序カテゴリ(有害事象グレード、QOLスコア、改善度など)のアウトカムを扱う順序ロジスティック回帰(比例オッズモデル)の考え方がわかります
・通常の(名義)ロジスティック回帰との違い、そして「累積確率」という発想を直感的に理解できます
・モデルの根幹である比例オッズ(proportional odds)の仮定が何を意味するのかを説明できるようになります
・累積ロジットモデルの数式(しきい値 θ_j と共通の回帰係数 β)を、意味とともに読み解けるようになります
・製薬・臨床試験の実務で、なぜこのモデルが頻繁に登場するのかがわかります
はじめに
臨床試験のデータを眺めていると、「順序はあるけれど間隔が等しいとは言えない」アウトカムに数多く出会います。たとえば有害事象の重症度グレード(Grade 1〜5)、QOL(生活の質)を測る5段階スコア、治療効果の改善度(著明改善・改善・不変・悪化)などです。これらは「軽い→重い」「悪い→良い」といった明確な順序を持ちますが、Grade 1 と Grade 2 の差が Grade 3 と Grade 4 の差と同じ大きさである保証はどこにもありません。
こうした順序カテゴリ変数(ordinal categorical variable)を、無理に連続量とみなして線形回帰にかけたり、順序を捨てて多項(名義)ロジスティック回帰で扱ったりすると、データが持つ大切な情報を歪めてしまいます。ここで登場するのが、本記事のテーマである順序ロジスティック回帰(ordinal logistic regression)、なかでも最も広く使われる比例オッズモデル(proportional odds model)です。
この記事は、製薬企業で解析を担う生物統計担当者、SAS や R を使う実務家、そして統計を学ぶ学生の方を対象に書いています。順序尺度のアウトカムは臨床試験にきわめて頻繁に登場するため、比例オッズモデルは実務で必ず押さえておきたい手法のひとつです。前半となるこのパートでは、まずモデルの概念と数理的背景を丁寧に解説します。累積確率とは何か、比例オッズの仮定とは何を約束しているのかを、数式と日本語の両面から腹に落としていきましょう。後半では、これを実際に R で動かし、結果を解釈するところまで進みます。
順序ロジスティック回帰とは
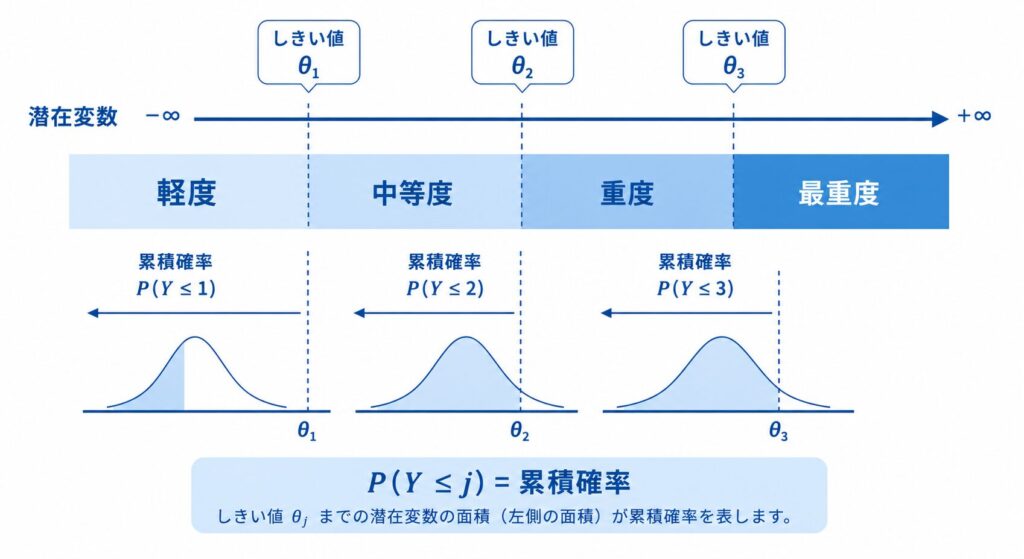
順序ロジスティック回帰を理解する近道は、まず通常の(名義)ロジスティック回帰との違いを押さえることです。
名義ロジスティック回帰(多項ロジスティック回帰)は、「A型・B型・O型」のように順序のないカテゴリを予測するための手法です。カテゴリ間に順序がないので、それぞれのカテゴリに対して別々の回帰係数を推定します。カテゴリが K 個あれば、係数の組も (K−1) 組必要になり、パラメータの数は一気に増えます。
一方で順序ロジスティック回帰は、カテゴリに順序があるという情報を積極的に使います。「軽度 < 中等度 < 重度」という並びをモデルに組み込むことで、より少ないパラメータで、より解釈しやすい結果を得られるのが最大の魅力です。 この「順序を使う」ための鍵が累積確率(cumulative probability)という考え方です。あるカテゴリ j 以下に入る確率、すなわち「軽度以下である確率」「中等度以下である確率」…を順番に考えていきます。順序があるからこそ「j 以下」という言い方に意味が生まれ、この累積確率をロジット変換してモデル化するのが、次章で扱う累積ロジットモデルです。
そしてこのモデルの土台となる大切な約束が、比例オッズ(proportional odds)の仮定です。ざっくり言えば「説明変数の効果は、どのカテゴリの境界で区切っても同じ大きさである」という仮定です。たとえば「薬剤 A は症状を1段階軽くする」という効果が、軽度/中等度の境界でも、中等度/重度の境界でも、同じ強さで働いていると想定します。だからこそ回帰係数 β をカテゴリ間で共有でき、モデルがシンプルになるのです。
比例オッズの仮定は「便利だから」で無条件に受け入れてよいものではありません。この仮定は「説明変数のオッズ比が、すべてのカテゴリ境界で共通(一定)」であることを要求します。もし実際のデータで、ある薬剤が軽症→中等症の移行には強く効くのに重症→最重症の移行にはほとんど効かない、といったことが起きていれば、この仮定は破れています。仮定が成り立たない場合、共通の β を当てはめると効果を誤って推定してしまいます。そのため実務では、後半で扱うように比例オッズの仮定を必ず検証(例:Brant 検定や尤度比検定)し、破れている場合は部分比例オッズモデルや名義ロジスティックへの切り替えを検討します。
数理的背景 ― 累積ロジットと比例オッズ
それでは、累積ロジットモデルを数式で定式化しましょう。アウトカム \( Y \) が \( K \) 個の順序カテゴリ \( 1, 2, \dots, K \)(値が大きいほど「重い/良い」など一方向に並ぶ)をとるとします。
まず累積確率を次のように定義します。
\[ P(Y \le j \mid \mathbf{x}) = \pi_1 + \pi_2 + \cdots + \pi_j, \quad j = 1, 2, \dots, K-1 \]
ここで \( \pi_j \) はカテゴリ \( j \) に入る確率、\( \mathbf{x} \) は説明変数のベクトルを意味します。つまり「カテゴリ \( j \) 以下に入る確率」を、カテゴリ 1 から \( j \) までの確率の合計として表しています。最上位のカテゴリまで足せば必ず 1 になるので、境界は \( K-1 \) 個だけ考えれば十分です。
この累積確率にロジット変換(対数オッズ)を施し、説明変数の線形結合で表したものが累積ロジットモデルです。
\[ \text{logit}\bigl[P(Y \le j \mid \mathbf{x})\bigr] = \log \frac{P(Y \le j \mid \mathbf{x})}{1 – P(Y \le j \mid \mathbf{x})} = \theta_j – \boldsymbol{\beta}^{\top}\mathbf{x} \]
ここで \( \theta_j \) は各カテゴリ境界に固有のしきい値(切片、threshold)を、\( \boldsymbol{\beta} \) は説明変数にかかる回帰係数のベクトルを意味します。左辺は「カテゴリ \( j \) 以下になるオッズの対数」です。右辺の右側の項にマイナス符号が付いているのは慣例で、こうしておくと \( \beta \) が正のとき「説明変数が大きいほど、より上位(重い/良い)のカテゴリに入りやすくなる」と自然に解釈できます(R の MASS::polr もこの符号定義を採用しています)。
ここで注目してほしいのは、しきい値 \( \theta_j \) は境界ごとに異なる(\( \theta_1 < \theta_2 < \cdots < \theta_{K-1} \))のに対し、回帰係数 \( \boldsymbol{\beta} \) には添字 \( j \) が付いていないという点です。これがまさに比例オッズの仮定の数式表現です。すなわち、説明変数の効果 \( \boldsymbol{\beta} \) はどのカテゴリ境界 \( j \) を選んでも共通であり、境界の位置(\( \theta_j \))だけが上下にずれていく、という構造になっています。
なぜこれが「比例オッズ」と呼ばれるのかを、オッズ比で確認しておきましょう。説明変数を1単位増やしたときの累積オッズ比は次のようになります。
\[ \frac{\text{odds}(Y \le j \mid \mathbf{x}+1)}{\text{odds}(Y \le j \mid \mathbf{x})} = e^{-\beta} \]
ここで左辺は「説明変数を1単位増やす前後での、カテゴリ \( j \) 以下になる累積オッズの比」を意味します。この比が \( e^{-\beta} \) となり、境界 \( j \) にまったく依存しない一定値であることがポイントです。つまり、どのカテゴリの区切りで見てもオッズ比が同じ(比例している)――これが「比例オッズ」という名前の由来です。この一定性こそが、モデルをシンプルにし、単一の \( \beta \) で効果を語れるようにしてくれる源泉なのです。
最後に、この構造を潜在変数(latent variable)の視点から眺めると、いっそう直感的になります。観測される順序カテゴリ \( Y \) の背後に、連続的な潜在変数 \( Y^{*} = \boldsymbol{\beta}^{\top}\mathbf{x} + \varepsilon \) があり、それがしきい値 \( \theta_j \) を超えるたびに観測カテゴリが1段階上がる、と考えるのです。
\[ Y = j \quad \Longleftrightarrow \quad \theta_{j-1} < Y^{*} \le \theta_j \]
ここで \( Y^{*} \) は目には見えない連続的な「症状の重さ・状態の良さ」を、\( \theta_j \) はカテゴリを区切るしきい値を意味します。誤差項 \( \varepsilon \) がロジスティック分布に従うと仮定すると、先ほどの累積ロジットモデルがちょうど導かれます。有害事象グレードや改善度といった順序アウトカムを、「連続的に変化する潜在的な状態を、いくつかのしきい値で区切って観測したもの」と捉える――この見方が、比例オッズモデルの心臓部です。
Rによる実装 ― MASS::polrで比例オッズモデルを推定する
順序ロジスティック回帰(比例オッズモデル)を R で推定する最も標準的な方法は、MASS パッケージの polr() 関数です。ここでは R に組み込まれている MASS::housing データセット を題材に、モデル推定からオッズ比の解釈、予測確率の算出までを一気通貫で確認していきます。
このデータは、コペンハーゲンの住宅入居者を対象に「住宅への満足度(Sat: Low < Medium < High)」を、影響度(Infl)、住居タイプ(Type)、管理者との接触(Cont)別に集計したもので、各行に度数(Freq)が付いた集計形式になっています。順序アウトカムの解析の練習にうってつけのデータです。 まずはデータを読み込み、アウトカム Sat が正しく「順序付き因子」になっているかを確認します。
library(MASS)
# housing データの構造を確認
data(housing)
str(housing)
# アウトカム Sat が Low < Medium < High の順序因子か確認
levels(housing$Sat)
is.ordered(housing$Sat)
> str(housing)
'data.frame': 72 obs. of 5 variables:
$ Sat : Ord.factor w/ 3 levels "Low"<"Medium"<..: 1 2 3 1 2 3 1 2 3 1 ...
$ Infl: Factor w/ 3 levels "Low","Medium",..: 1 1 1 2 2 2 3 3 3 1 ...
$ Type: Factor w/ 4 levels "Tower","Apartment",..: 1 1 1 1 1 1 1 1 1 2 ...
$ Cont: Factor w/ 2 levels "Low","High": 1 1 1 1 1 1 1 1 1 1 ...
$ Freq: int 21 21 28 34 22 36 10 11 36 61 ...
> levels(housing$Sat)
[1] "Low" "Medium" "High"
> is.ordered(housing$Sat)
[1] TRUE
Sat は
Ord.factor(順序付き因子)で、Low < Medium < High の順序が保持されています。polr() はアウトカムが順序因子であることを前提とするため、この確認が最初の関門です。もし普通の因子(factor)のままだとエラーになるので、その場合は factor(x, levels = ..., ordered = TRUE) で順序を明示してください。Freq は各セルの人数(度数重み)で、モデル推定時に weights 引数に渡します。続いて polr() でモデルを推定します。Hess = TRUE を指定しておくと、後で summary() を呼んだときに標準誤差を計算するためのヘッセ行列が保存され、係数の検定が可能になります。
# 比例オッズモデルの推定(Freq を度数重みとして使用)
m <- polr(Sat ~ Infl + Type + Cont,
weights = Freq, data = housing, Hess = TRUE)
summary(m)
Call:
polr(formula = Sat ~ Infl + Type + Cont, data = housing, weights = Freq,
Hess = TRUE)
Coefficients:
Value Std. Error t value
InflMedium 0.5664 0.10465 5.412
InflHigh 1.2888 0.12716 10.135
TypeApartment -0.5724 0.11924 -4.800
TypeAtrium -0.3662 0.15537 -2.357
TypeTerrace -1.0910 0.15149 -7.202
ContHigh 0.3603 0.09554 3.771
Intercepts:
Value Std. Error t value
Low|Medium -0.4961 0.1248 -3.9743
Medium|High 0.6907 0.1255 5.5028
Residual Deviance: 3479.149
AIC: 3495.149
係数(Coefficients)はすべて ロジットスケールで、正の値ほど「満足度が高い方向」への効果を意味します。
・
InflHigh = 1.289:影響度が高い入居者は、影響度が低い人に比べて満足度が高い方向に強く効いています(t 値 10.1 と非常に有意)。InflMedium = 0.566 も正で、影響度が上がるほど満足度が上がるという自然な関係が読み取れます。・
ContHigh = 0.360:管理者との接触が多いほど満足度が高い方向(正の効果、t = 3.77)。・
TypeTerrace = -1.091:基準の Tower(高層塔)に比べ、テラスハウス住まいは満足度が低い方向に大きく効いています。閾値(Intercepts)の
Low|Medium = -0.496、Medium|High = 0.691 は、隣り合うカテゴリを分ける2本のカットポイントです。t 値は Wald 検定ですが、polr() は p 値を直接出さないため、後述のオッズ比と信頼区間で判断するのが実務的です。t 値だけでは有意性の判断がしづらいので、係数を オッズ比(= exp(係数)) に変換し、95% 信頼区間とあわせて確認します。
# オッズ比と 95% 信頼区間
OR <- exp(coef(m))
CI <- exp(confint(m)) # プロファイル尤度に基づく信頼区間
round(cbind(OR = OR, CI), 3)
Waiting for profiling to be done...
OR 2.5 % 97.5 %
InflMedium 1.762 1.436 2.166
InflHigh 3.628 2.831 4.665
TypeApartment 0.564 0.446 0.712
TypeAtrium 0.693 0.511 0.940
TypeTerrace 0.336 0.249 0.452
ContHigh 1.434 1.189 1.729
比例オッズモデルのオッズ比は「ある閾値より上のカテゴリに入るオッズが何倍になるか」を表し、どの閾値(Low|Medium でも Medium|High でも)でも共通と仮定されます。
・
InflHigh のオッズ比 3.63(95%CI 2.83–4.67):影響度が高い人は低い人に比べ、より高い満足度カテゴリに入るオッズが約 3.6 倍。信頼区間が 1 を大きく上回り明確に有意です。・
ContHigh のオッズ比 1.43(95%CI 1.19–1.73):管理者接触が多いと、より高い満足度に入るオッズが約 1.4 倍。・
TypeTerrace のオッズ比 0.34(95%CI 0.25–0.45):テラスハウスは基準の Tower に比べ、高い満足度に入るオッズが約 3 分の 1 に下がります。信頼区間が 1 をまたがない変数は、満足度と統計的に有意な関連があると判断できます。最後に、特定のプロフィールを持つ入居者について、各満足度カテゴリに入る 予測確率 を算出してみます。
# 予測したいプロフィールを指定
newdata <- data.frame(
Infl = factor(c("Low", "High"), levels = levels(housing$Infl)),
Type = factor(c("Tower", "Tower"), levels = levels(housing$Type)),
Cont = factor(c("Low", "High"), levels = levels(housing$Cont))
)
# 各カテゴリの予測確率
round(predict(m, newdata, type = "probs"), 3)
Low Medium High
1 0.558 0.241 0.201
2 0.219 0.221 0.560
1 行目(影響度 Low・接触 Low の Tower 住まい)は「Low 満足度」の確率が 約 56% と最も高く、High 満足度はわずか 20% です。一方、2 行目(影響度 High・接触 High)では High 満足度の確率が 約 56% まで跳ね上がり、Low は 22% に下がります。
このように予測確率まで出すと、係数やオッズ比だけでは伝わりにくい「実際にどのくらい満足度分布が変わるか」を直感的に示せます。臨床試験や患者報告アウトカム(PRO)の解析でも、共変量を動かしたときの各カテゴリ確率を提示すると説得力が増します。
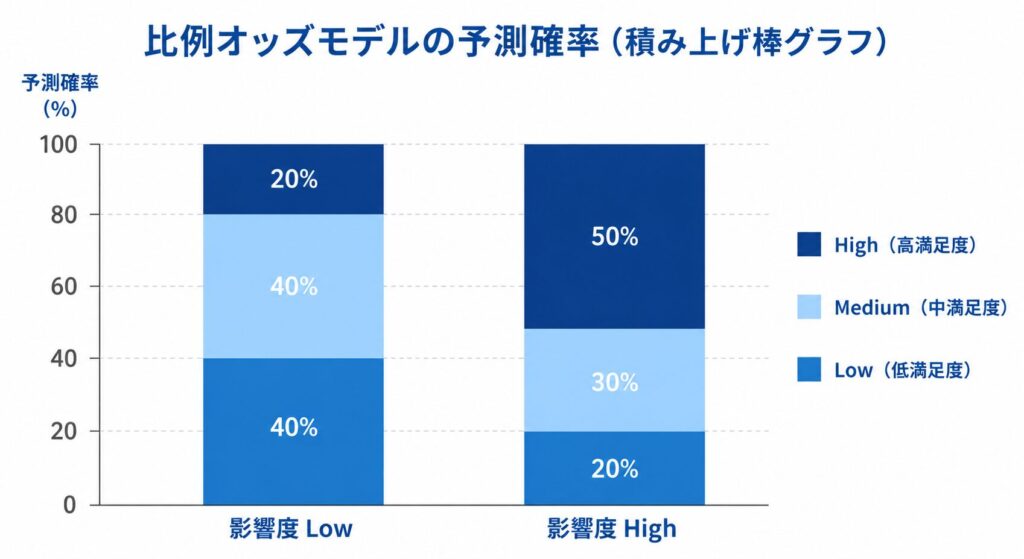
比例オッズの仮定を検証する ― Brant検定と対処法
比例オッズモデルは「すべての閾値でオッズ比が共通(=説明変数の効果がカテゴリ境界によらず一定)」という強い仮定の上に成り立っています。この 比例オッズ性(平行性)の仮定 が崩れていると、共通のオッズ比という要約が誤解を招くため、モデルを信頼する前に必ず検証すべきです。代表的な方法が Brant 検定 です。
# install.packages("brant")
library(brant)
# 比例オッズの仮定を検定
brant(m)
--------------------------------------------
Test for X2 df probability
--------------------------------------------
Omnibus 49.03 6 0
InflMedium 2.25 1 0.13
InflHigh 5.60 1 0.02
TypeApartment 5.20 1 0.02
TypeAtrium 1.86 1 0.17
TypeTerrace 4.20 1 0.04
ContHigh 1.44 1 0.23
--------------------------------------------
H0: Parallel Regression Assumption holds
Brant 検定の帰無仮説 H0 は「比例オッズ(平行性)の仮定が成り立つ」です。
・Omnibus(モデル全体)の p 値が 0(<0.001)と有意で、全体としては平行性の仮定が疑わしいという結果です。
・変数ごとに見ると、
InflHigh(p = 0.02)、TypeApartment(p = 0.02)、TypeTerrace(p = 0.04)が仮定を満たさない疑いがあります。一方 ContHigh(p = 0.23)や InflMedium(p = 0.13)は問題なさそうです。このように「一部の変数だけ仮定が崩れる」ケースはよくあり、その変数についてだけ効果がカテゴリ境界で変わることを許す部分比例オッズモデルが有力な選択肢になります。
仮定が破綻していた場合の対処としては、次のような選択肢があります。
| 対処法 | R での実装 | 考え方 |
|---|---|---|
| 部分比例オッズモデル | VGAM::vglm(..., cumulative(parallel = FALSE ~ x)) | 仮定が崩れた変数だけ効果を閾値ごとに推定 |
| 順序回帰の柔軟な枠組み | ordinal::clm() | scale効果やnominal項で不均一性を吸収 |
| 多項ロジスティック回帰 | nnet::multinom() | 順序性を捨て、各カテゴリを個別にモデル化 |
ここでは、仮定が崩れた Infl と Type だけ平行性を外した 部分比例オッズモデル を VGAM で推定する例を示します。
library(VGAM)
# Infl と Type だけ比例オッズを外す(Cont は平行のまま)
m_ppo <- vglm(Sat ~ Infl + Type + Cont,
family = cumulative(parallel = FALSE ~ Infl + Type),
weights = Freq, data = housing)
# 係数のみ確認
coef(m_ppo, matrix = TRUE)[, 1:2]
logitlink(P[Y<=1]) logitlink(P[Y<=2])
(Intercept) 0.4956953 -0.68932353
InflMedium -0.5636910 -0.56692855
InflHigh -1.1198688 -1.42993846
TypeApartment 0.4260092 0.68635240
TypeAtrium 0.3223198 0.38321457
TypeTerrace 0.9498462 1.19819158
ContHigh -0.3609404 -0.36094039
部分比例オッズモデルでは、平行性を外した変数の係数が2本の閾値(P[Y≤1] と P[Y≤2])で別々に推定されます。たとえば
InflHigh は -1.12 と -1.43 でカットポイントごとに値が異なり、比例オッズが成り立たないことが数値からも読み取れます(polr では両方まとめて 1 つの値に押し込んでいたわけです)。一方、平行を保った ContHigh は両列とも -0.361 で共通です。VGAM は累積確率 P[Y≤k] を直接モデル化するため符号の向きが polr と逆になる点に注意してください。Brant 検定をはじめとする比例オッズ性の検定は、サンプルサイズが大きいと些細なずれでも「有意」になりやすく(検出力過剰)、逆に小さいと崩れを見逃すという性質があります。さらに変数ごとに何度も検定すると多重性の問題も生じます。したがって検定の p 値だけで機械的に判断するのは危険です。各カテゴリの観測比率と予測確率の図示、変数ごとのオッズ比が閾値間でどれだけ乖離するかの可視化、そして「その変数の効果がカテゴリ境界で変わることが臨床的・実務的に妥当か」という文脈判断を必ず併せて行ってください。仮定のわずかな逸脱が結論に影響しないなら、解釈しやすい比例オッズモデルを採用する判断も十分に合理的です。
実務でのポイント
順序ロジスティック回帰(比例オッズモデル)は、製薬・臨床試験の現場で扱うアウトカムの多くが「順序をもつカテゴリ」であるため、実務での出番が非常に多い手法です。ここでは、実際に解析計画を立てたり結果を報告したりする際に押さえておきたいポイントを整理します。
まず代表的な適用場面が 有害事象グレード(CTCAE Grade 1〜4) の解析です。有害事象は「Grade 1 < Grade 2 < Grade 3 < Grade 4」という明確な順序をもちますが、間隔は等しいと仮定できません。このようなアウトカムを平均値の比較(t検定・ANOVA)で扱うと順序情報を歪めてしまうため、累積ロジットに基づく順序ロジスティック回帰が適切な選択肢になります。同様に、QOL/PRO(患者報告アウトカム)の順序尺度(「非常に良い〜非常に悪い」の5段階など)、疾患重症度(軽症・中等症・重症)、mRS(modified Rankin Scale)のような機能予後スケールも典型的な適用対象です。
一方で、比例オッズの仮定が崩れやすい場面には注意が必要です。比例オッズモデルは「共変量の効果がすべての累積ロジットで共通(オッズ比が一定)」という強い仮定を置いています。カテゴリ数が多い、あるいは端のカテゴリで効果の向きや大きさが変わるようなデータでは、この仮定が満たされないことがあります。仮定が疑わしいときは、Brant検定などで比例オッズ性を検証し、崩れている場合は 部分比例オッズモデル(partial proportional odds) や、順序を仮定しない 多項ロジスティック回帰、あるいは連続比モデル・隣接カテゴリモデルへの切り替えを検討します。
サンプルサイズとセル度数も実務では見落とせません。カテゴリごとの症例数が極端に少ない(特に最重症カテゴリに数例しかいない)と、閾値パラメータの推定が不安定になり、標準誤差が過大になったり収束しなかったりします。事前に各カテゴリの度数分布を確認し、必要に応じて 隣接する境界カテゴリを統合(例:Grade 3 と Grade 4 を「Grade 3以上」にまとめる)することも現実的な対応です。ただしカテゴリ統合は臨床的な解釈可能性と解析計画(SAP)での事前規定が前提であり、結果を見てから統合するのは避けるべきです。欠測についても、PRO では特に脱落に伴う欠測が問題になりやすいため、欠測メカニズムの想定と感度分析をあらかじめ計画に含めておきます。
SAS での実装は、PROC LOGISTIC が累積ロジットをデフォルトで扱い、比例オッズの検定(Score test for proportional odds)も自動出力されます。
proc logistic data=ae;
class trt (ref='Placebo') / param=ref;
model grade = trt age / link=clogit;
run;
出力の「Score Test for the Proportional Odds Assumption」が有意(小さいp値)であれば比例オッズが疑われるため、上記の代替モデルを検討します。
・有害事象グレード・QOL/PRO・疾患重症度など「順序カテゴリ」のアウトカムに第一選択となる手法です。
・比例オッズの仮定は必ず検証を。崩れていれば部分比例オッズ・多項ロジットへ切り替えます。
・最重症カテゴリのセル度数不足に注意。カテゴリ統合はSAPで事前規定してから行います。
・SASでは
PROC LOGISTIC が累積ロジットをデフォルトで扱い、比例オッズのScore testも自動出力されます。📚 この記事をより深く理解するための参考書籍
順序ロジスティック回帰は、一般化線形モデル(GLM)とカテゴリカルデータ解析の交差点に位置する手法です。理論的背景から実装まで体系的に学びたい方に、次の3冊をおすすめします。






関連記事・次のステップ
順序ロジスティック回帰は、2値のロジスティック回帰を「順序カテゴリ」へ拡張したものです。土台となる2値ロジスティック回帰の理論・実装・解釈を復習したい方は、2値変数とロジスティック回帰:理論・実装・解釈までの実践ガイドを先に読んでおくと、累積ロジットの理解がぐっと深まります。
また、本記事で繰り返し触れた比例オッズモデルは一般化線形モデル(GLM)の一員です。GLMが従来の線形モデルと何が違うのかを整理したい方には、一般線形モデルと一般化線形モデルの違いを徹底解説が全体像の把握に役立ちます。
一方、順序をもつ多群を「群間で分布に傾向差があるか」という観点から検定したい場合には、ノンパラメトリックなJonckheereの順位和検定を徹底解説:順序をもつ多群比較に最適なノンパラメトリック手法が有力な選択肢になります。回帰による調整とノンパラ検定を使い分けられるようにしておくと、解析の引き出しが広がります。
まとめ
本記事では、順序カテゴリをもつアウトカムを扱う順序ロジスティック回帰(比例オッズモデル)について、その考え方からRでの実装、結果の解釈、そして実務上の注意点までを一通り解説しました。累積ロジットを用いることで、順序情報を失わずに共変量の効果を1つのオッズ比として簡潔に表現できる点が、この手法の大きな魅力です。
製薬・臨床試験の現場では、有害事象グレードやQOL・PROといった順序尺度のアウトカムが数多く登場します。これらを安易に連続量として平均比較したり、順序を無視して多項ロジットで扱ったりするのではなく、データの性質に合ったモデルを選ぶことが、解析の妥当性と結果の説得力を左右します。同時に、比例オッズの仮定の検証、セル度数や欠測への配慮を怠らない姿勢が、信頼される解析結果につながります。
順序ロジスティック回帰を自在に使いこなし、仮定の妥当性まで丁寧に確認できることは、順序アウトカムに向き合う生物統計家にとって確かな強みになります。