統計検定準1級「回帰分析」攻略 ― 重回帰・多重共線性・変数選択・ロジスティック回帰の典型出題対策 ―

この記事でわかること
・回帰分析の基礎理論(最小二乗法・偏回帰係数・決定係数)を、記号の定義から丁寧に理解できます
・多重共線性(説明変数どうしの強い相関による推定の不安定化)と、VIF・AIC/BIC を使った変数選択の考え方がわかります
・ロジスティック回帰とオッズ比の意味、そして「対数オッズが線形」という発想を整理できます
・統計検定準1級で頻出の回帰分析の典型出題パターンを、例題と段階的な解答つきで確認できます
・R を使った単回帰・重回帰・ロジスティック回帰の実装方法を身につけられます
はじめに
回帰分析は、統計検定準1級で最も頻出の領域の一つです。ある変数から別の変数を予測・説明するというシンプルな発想でありながら、出題範囲は非常に広く、単回帰・重回帰にとどまらず、多重共線性への対処、AIC/BIC を用いた変数選択、さらには 2 値の結果を扱うロジスティック回帰まで問われます。計算問題も理論の穴埋めも、どちらの形式でも登場する重要テーマです。
本記事では、まず回帰分析の基礎理論を数式の記号定義から丁寧に整理し、続いて準1級で狙われやすい典型出題パターンを例題とともに確認し、最後に R による実装まで体系的にまとめていきます。統計検定準1級の受験者はもちろん、製薬・臨床開発の実務でモデルを扱う方、統計学を学ぶ大学生の方まで、独学で回帰分析を追い切れる構成を目指します。それでは、単回帰から順に見ていきましょう。
回帰分析の基礎 ― 単回帰から重回帰へ
単回帰モデルと最小二乗推定
まずは説明変数が 1 つの単回帰モデルから始めます。観測値の組 \((x_i, y_i)\)(\(i=1,\dots,n\))に対して、単回帰モデルは次のように書けます。
\[ y_i = \beta_0 + \beta_1 x_i + \varepsilon_i \]
ここで \(y_i\) は目的変数(予測したい値)、\(x_i\) は説明変数、\(\beta_0\) は切片、\(\beta_1\) は傾き(回帰係数)、\(\varepsilon_i\) は誤差項です。つまり「\(y\) を \(x\) の 1 次式で説明し、そのズレを誤差 \(\varepsilon\) が吸収する」という形になっています。
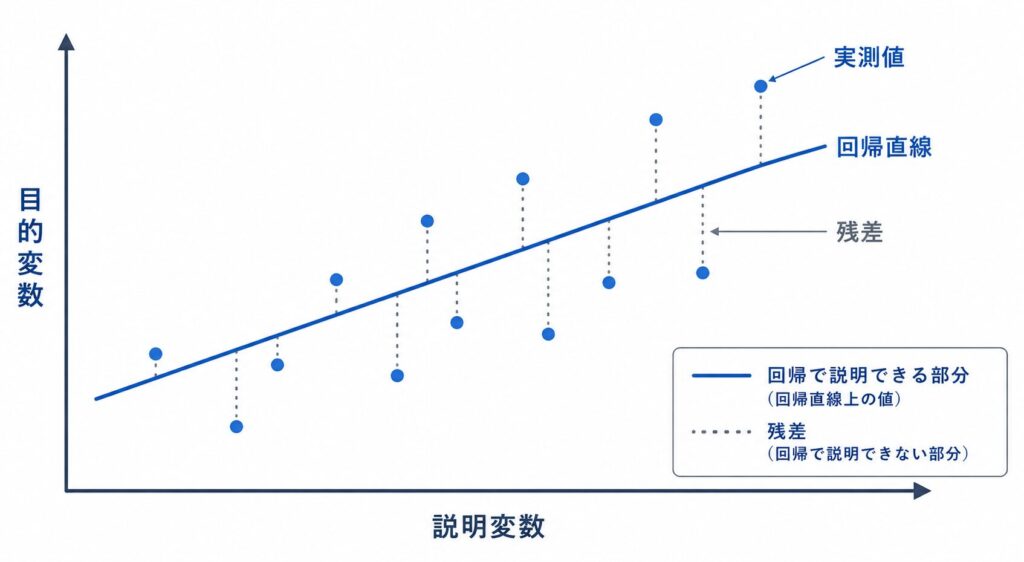
このモデルのパラメータ \(\beta_0, \beta_1\) を、実データからどう決めるのか。ここで使うのが最小二乗法(Ordinary Least Squares、OLS)です。これは「予測値と実測値のズレの二乗和を最小にするように係数を選ぶ」方法で、残差平方和 \(\sum_{i=1}^{n}(y_i – \beta_0 – \beta_1 x_i)^2\) を最小化します。この最小化問題を解くと、推定量は次の形で与えられます。
\[ \hat\beta_1 = \frac{S_{xy}}{S_{xx}}, \qquad \hat\beta_0 = \bar y – \hat\beta_1 \bar x \]
ここで登場する \(S_{xx}\) と \(S_{xy}\) は、それぞれ次のように定義される「偏差の積和」です。
\[ S_{xx} = \sum_{i=1}^{n} (x_i – \bar x)^2, \qquad S_{xy} = \sum_{i=1}^{n} (x_i – \bar x)(y_i – \bar y) \]
\(S_{xx}\) は \(x\) の散らばり(平方和)、\(S_{xy}\) は \(x\) と \(y\) が一緒に動く度合い(積和)を表します。\(\bar x, \bar y\) はそれぞれ \(x, y\) の標本平均です。傾きの推定量 \(\hat\beta_1 = S_{xy}/S_{xx}\) が「共変動を \(x\) の変動で割ったもの」になっている点は、準1級の計算問題で直接使うので必ず押さえておきましょう。また切片の式 \(\hat\beta_0 = \bar y – \hat\beta_1 \bar x\) から、回帰直線は必ず重心 \((\bar x, \bar y)\) を通ることもわかります。
重回帰モデルと行列表現
説明変数が複数ある場合が重回帰モデルです。説明変数を \(x_{1}, \dots, x_{p}\) とすると、モデルは次のように拡張されます。
\[ y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \cdots + \beta_p x_{ip} + \varepsilon_i \]
説明変数が増えると添え字が煩雑になるため、行列を使ってまとめて表すのが定石です。目的変数のベクトル \(\mathbf y\)、計画行列(デザイン行列)\(\mathbf X\)、係数ベクトル \(\boldsymbol\beta\)、誤差ベクトル \(\boldsymbol\varepsilon\) を用いると、モデル全体は次の 1 本の式で書けます。
\[ \mathbf y = \mathbf X\boldsymbol\beta + \boldsymbol\varepsilon \]
ここで \(\mathbf X\) は各行が 1 つの観測、各列が 1 つの説明変数(切片用の 1 の列を含む)に対応する \(n \times (p+1)\) 行列です。この表現のもとで最小二乗法を適用すると、残差平方和 \((\mathbf y – \mathbf X\boldsymbol\beta)^\top (\mathbf y – \mathbf X\boldsymbol\beta)\) を最小にする条件から正規方程式 \(\mathbf X^\top \mathbf X \boldsymbol\beta = \mathbf X^\top \mathbf y\) が導かれ、その解は次のようになります。
\[ \hat{\boldsymbol\beta} = (\mathbf X^\top \mathbf X)^{-1} \mathbf X^\top \mathbf y \]
この \((\mathbf X^\top \mathbf X)^{-1}\) が計算できること、すなわち \(\mathbf X^\top \mathbf X\) が正則(逆行列を持つ)であることが推定の大前提です。後で述べる多重共線性は、まさにこの逆行列が「ほとんど計算できない状態」に近づく現象で、推定を不安定にする原因になります。
単回帰の \(\hat\beta_1 = S_{xy}/S_{xx}\) は、重回帰の \(\hat{\boldsymbol\beta} = (\mathbf X^\top \mathbf X)^{-1}\mathbf X^\top \mathbf y\) の特別な場合です。行列表現に慣れておくと、説明変数が何個になっても同じ枠組みで扱えます。
偏回帰係数・決定係数と検定
重回帰における各係数 \(\hat\beta_j\) は偏回帰係数と呼ばれます。「偏」という字が付くのは、他の説明変数をすべて一定に保ったときに、\(x_j\) が 1 単位増えると \(y\) が平均的にどれだけ変化するか、という「その変数だけの純粋な効果」を表すためです。単回帰の係数(他の変数を無視した全体的な効果)とは意味が異なる点に注意しましょう。
ただし偏回帰係数は、各説明変数の単位(cm、kg、円など)に依存するため、係数の大小をそのまま比べても「どの変数が効いているか」はわかりません。そこで各変数を標準化(平均 0・分散 1 に変換)してから回帰したときの係数を標準化偏回帰係数と呼び、これを使うと単位に左右されずに変数間の影響の大きさを比較できます。
モデルの当てはまりの良さを測る代表的な指標が決定係数 \(R^2\) です。予測値を \(\hat y_i\) として、次のように定義されます。
\[ R^2 = 1 – \frac{\sum_{i=1}^{n}(y_i – \hat y_i)^2}{\sum_{i=1}^{n}(y_i – \bar y)^2} \]
分母は \(y\) の全変動、分子は回帰で説明しきれなかった残差変動です。したがって \(R^2\) は「全変動のうちモデルが説明できた割合」を意味し、0 から 1 の値をとり、1 に近いほど当てはまりが良いと解釈します。
ここで注意が必要なのは、\(R^2\) は説明変数を増やすほど(たとえ無意味な変数でも)必ず増加してしまう性質を持つことです。そこで重回帰では、変数の数によるペナルティを課した自由度調整済み決定係数 \(\bar R^2\)(adjusted \(R^2\))を見ます。
\[ \bar R^2 = 1 – \frac{(1 – R^2)(n – 1)}{n – p – 1} \]
ここで \(n\) は標本サイズ、\(p\) は説明変数の数です。分母の \(n – p – 1\) は残差の自由度で、\(p\) が増えると調整済み \(\bar R^2\) は必ずしも増えません。役に立たない変数を追加すると \(\bar R^2\) はむしろ下がることがあり、この点が変数の要不要を見極める手がかりになります。両者の違いを次の表にまとめます。
| 指標 | 意味 | 変数を増やすと | 主な用途 |
|---|---|---|---|
| 決定係数 \(R^2\) | 全変動のうちモデルが説明できた割合 | 必ず増加(減らない) | 単回帰・当てはまりの目安 |
| 自由度調整済み \(\bar R^2\) | 変数の数でペナルティを課した \(R^2\) | 無意味な変数なら下がりうる | 重回帰・モデル比較 |
回帰モデルの有意性は、分散分析(ANOVA)の枠組みで検定します。目的変数の全変動は、次のように回帰変動(モデルで説明された部分)と残差変動(説明できなかった部分)に分解できます。
\[ \underbrace{\sum_{i=1}^{n}(y_i – \bar y)^2}_{\text{全変動}} = \underbrace{\sum_{i=1}^{n}(\hat y_i – \bar y)^2}_{\text{回帰変動}} + \underbrace{\sum_{i=1}^{n}(y_i – \hat y_i)^2}_{\text{残差変動}} \]
この分解に基づき、「すべての回帰係数が 0(\(\beta_1 = \cdots = \beta_p = 0\))」という帰無仮説を検定するのが F 検定で、モデル全体が意味を持つかどうかを判定します。一方、個々の係数については t 検定を行い、帰無仮説 \(\beta_j = 0\)(その変数は \(y\) に効いていない)を検定します。F 検定は「モデル全体」、t 検定は「変数一つひとつ」を見る、という役割分担を押さえておきましょう。
最後に、これらの推定・検定が妥当であるためには、回帰分析がいくつかの前提を満たしている必要があります。すなわち、①線形性(\(y\) と説明変数が線形の関係にある)、②誤差の独立性(各観測の誤差が互いに独立)、③等分散性(誤差の分散がどこでも一定=ホモスケダスティシティ)、④正規性(誤差が正規分布に従う)の 4 つです。特に F 検定や t 検定の妥当性は正規性の仮定に支えられており、残差プロットなどで前提を確認することが実務でも重要になります。
多重共線性と変数選択
重回帰分析では説明変数を複数投入しますが、その説明変数どうしが強く相関している状態を 多重共線性(multicollinearity) と呼びます。たとえば「身長」と「座高」を同時に説明変数に入れると、両者はほぼ同じ情報を持つため、モデルはどちらの変数に「効果」を割り振ってよいか判断できなくなります。
多重共線性があると、次のような困った現象が起こります。
- 回帰係数の推定が不安定になり、データをわずかに変えただけで係数が大きく揺れます。
- 各係数の標準誤差が膨張(inflation) し、本来は意味のある変数が「有意でない」と判定されやすくなります。
- 符号が直感と逆転する(正の効果を期待した変数の係数が負になる)ことがあります。
厄介なのは、モデル全体の当てはまり(決定係数 \( R^2 \) や予測精度)はむしろ良好に見える場合がある点です。つまり「予測はできるが、個々の係数の解釈は信頼できない」という状態に陥ります。
分散拡大係数 VIF による診断
多重共線性の代表的な診断指標が 分散拡大係数(Variance Inflation Factor, VIF) です。説明変数 \( x_j \) について、
\[
\mathrm{VIF}_j = \frac{1}{1 – R_j^2}
\]
と定義します。ここで \( R_j^2 \) は、説明変数 \( x_j \) を目的変数とみなし、残りの説明変数すべてで回帰したときの決定係数です。\( x_j \) が他の変数でよく説明できてしまう(=強く相関している)ほど \( R_j^2 \) は 1 に近づき、VIF は大きくなります。
目安として、
- VIF が 10 以上なら多重共線性が強いと判断するのが一般的です(\( R_j^2 = 0.9 \) に相当)。
- より厳しく 5 を目安とすることもあります。
VIF の「10」「5」という基準はあくまで慣習的な目安であり、絶対的な合格ラインではありません。VIF が閾値を下回っていても解釈上の不安定さが残ることはありますし、逆に高くても分析目的(予測のみか、係数の解釈まで踏み込むか)によっては許容されることもあります。数値を機械的に見るのではなく、変数の意味と分析目的に照らして判断してください。
補助的な診断として、説明変数間の 相関行列を眺めて相関の高いペアを見つける方法もよく使われます。ただし相関行列は 2 変数間の関係しか見ないため、3 つ以上の変数が絡み合う多重共線性は見逃すことがあります。偏相関(partial correlation)(他の変数の影響を取り除いたうえでの 2 変数間の相関)を併用すると、より丁寧に関係を把握できます。VIF はこうした多変数の絡みをまとめて捉えられる点で優れています。
変数選択の方法
説明変数の候補が多いとき、どの変数をモデルに残すかを決めるのが 変数選択(variable selection) です。代表的な手法は次の 4 つです。
- 総当たり法(all subsets / best subset):候補変数の組み合わせをすべて試し、規準が最良のモデルを選びます。網羅的ですが、変数が \( p \) 個あると \( 2^p \) 通りを調べる必要があり計算量が膨大です。
- 前進選択法(forward selection):変数なしの状態から出発し、規準を最も改善する変数を 1 つずつ追加していきます。
- 後退消去法(backward elimination):全変数を入れた状態から出発し、規準への貢献が最も小さい変数を 1 つずつ除いていきます。
- ステップワイズ法(stepwise):前進と後退を組み合わせ、追加と削除を交互に検討しながらモデルを更新します。
選択規準
どのモデルが「良い」かを測る規準として、準1級では次のものを押さえておきましょう。いずれも「当てはまりの良さ」と「モデルの複雑さ(パラメータ数)」のバランスを取る発想です。
赤池情報量規準(AIC):
\[
\mathrm{AIC} = -2\ln L + 2k
\]
ここで \( L \) は最大尤度(モデルがデータをどれだけうまく説明するかの最大値)、\( k \) はパラメータ数です。第 1 項が小さいほど当てはまりが良く、第 2 項がパラメータ数に対する罰則(ペナルティ)です。AIC は小さいほど良いモデルとされます。
ベイズ情報量規準(BIC, SBC とも呼ぶ):
\[
\mathrm{BIC} = -2\ln L + k\ln n
\]
\( n \) は標本サイズです。罰則項が \( 2k \) ではなく \( k\ln n \) となっている点が AIC との違いです。\( n \) が大きいほど \( \ln n \) が大きくなり、パラメータを増やすことへの罰則が重くなるため、BIC は AIC よりも単純なモデルを選びやすい傾向があります(\( n \ge 8 \) で \( \ln n > 2 \) となり、BIC の罰則が AIC を上回ります)。
そのほか、
- 自由度調整済み決定係数(adjusted \( R^2 \)):通常の \( R^2 \) は変数を増やすほど必ず上がってしまうため、パラメータ数で調整して「増やし損」を反映させた指標です。大きいほど良いとされます。
- Mallows’ \( C_p \):予測誤差(バイアスと分散の和)を評価する規準で、良いモデルではおおむね \( C_p \approx k \)(パラメータ数付近)になることを目安に選びます。
ステップワイズ法は便利ですが、乱用には強い批判があります。第一に、同じデータで変数を選んでから計算した p 値や信頼区間(CI)は、そのままでは正しく解釈できません。有意になりやすい変数を選び抜いた後で有意性を語るのは「二度おいしい」検定であり、p 値は過小に、CI は過度に狭く出ます。第二に、統計的に選ばれた変数がそのまま因果関係を意味するわけではありません。交絡や偶然の相関で選ばれることもあり、変数選択は「予測に有用な変数」を探す作業であって「原因」を特定する作業ではない、と切り分けて考えてください。
| 規準 | 定義・式 | 特徴 | 傾向 |
|---|---|---|---|
| AIC | \( -2\ln L + 2k \) | 予測の良さを重視。小さいほど良い | やや複雑なモデルを選びやすい |
| BIC(SBC) | \( -2\ln L + k\ln n \) | 標本サイズに応じ罰則が増大。小さいほど良い | \( n \) が大きいほど単純なモデルを選びやすい |
| 自由度調整済み \( R^2 \) | \( 1-\dfrac{(1-R^2)(n-1)}{n-k-1} \) | 変数増加の「増やし損」を調整。大きいほど良い | 無意味な変数追加ではむしろ低下 |
| Mallows’ \( C_p \) | 予測誤差(バイアス+分散)を評価 | \( C_p \approx k \) となるモデルが望ましい | 過小・過大なモデルの発見に有用 |
最後に 過学習(overfitting) の視点も欠かせません。変数を増やせば手元のデータへの当てはまり(\( R^2 \))はいくらでも良くできますが、それはデータに含まれる偶然のノイズまで拾ってしまっている可能性があります。こうしたモデルは、新しいデータに対する予測精度(汎化性能, generalization) が逆に悪化します。AIC・BIC・\( C_p \) といった規準や、自由度調整済み \( R^2 \) は、まさにこの「当てはまりの良さ」と「複雑さによる過学習リスク」のトレードオフを数値化して、汎化性能の高いモデルを選ぶための道具立てなのです。
ロジスティック回帰 ― 二値アウトカムを扱う回帰
これまでの重回帰は目的変数が連続量(血圧・身長など)の場合でしたが、医学・製薬の現場では「治療が奏効したか(1)/しなかったか(0)」「有害事象が起きたか/否か」といった 二値アウトカム(0/1) を扱う場面が非常に多くあります。こうした二値の結果を、通常の線形回帰でそのまま予測するのは適切ではありません。
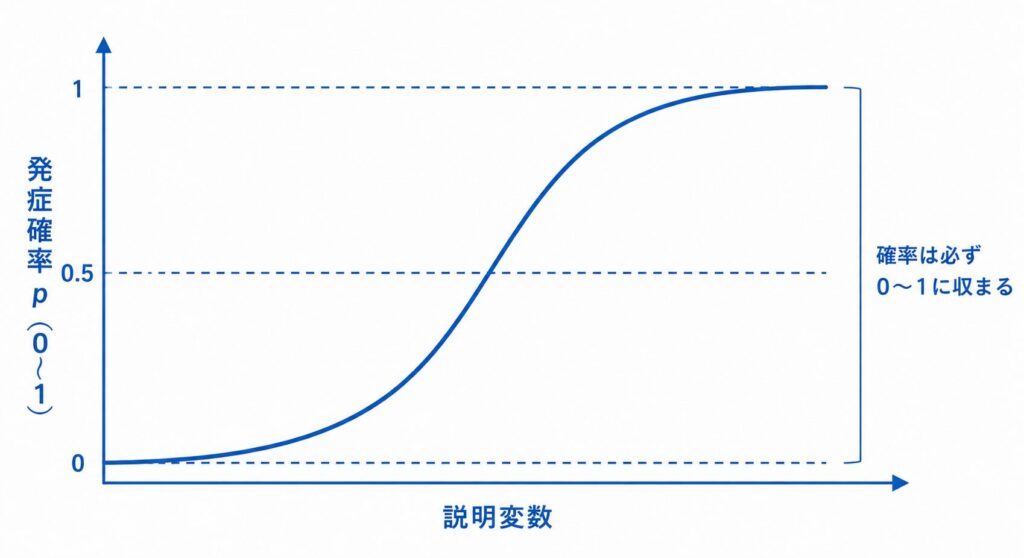
理由はいくつかあります。線形回帰 \( y = \beta_0 + \beta_1 x + \cdots \) では、右辺は \( x \) の値しだいで \( -\infty \) から \( +\infty \) まで取り得ます。ところが確率は本来 \( [0,1] \) の範囲に収まるべきもので、予測値が 1 を超えたり負になったりして「確率」として解釈できなくなってしまいます。また、二値データでは分散が平均に依存する(分散が一定でない)ため、線形回帰が前提とする等分散性も満たされません。
ロジットリンクとオッズ
そこで登場するのが ロジスティック回帰(logistic regression) です。事象が起こる確率を \( p \) とし、次のように ロジット(logit) を線形式に結びつけます。
\[
\log\frac{p}{1-p} = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_k x_k
\]
ここで \( p \) は「事象が起こる確率」、\( x_1,\dots,x_k \) は説明変数、\( \beta_0,\dots,\beta_k \) は回帰係数です。左辺の \( \dfrac{p}{1-p} \) を オッズ(odds) と呼びます。オッズは「起こる確率」と「起こらない確率」の比で、たとえば \( p = 0.8 \) ならオッズは \( 0.8/0.2 = 4 \)(起こる方が起こらない方の 4 倍起こりやすい)を意味します。そのオッズの対数(=ロジット)を線形式で表すのがロジスティック回帰の骨格です。
この変換のおかげで、右辺が \( -\infty \sim +\infty \) のどんな値を取っても、逆算した \( p \) は必ず \( [0,1] \) に収まります(\( p = \dfrac{1}{1+e^{-(\beta_0+\beta_1 x_1+\cdots)}}\))。これで「確率が範囲外」という線形回帰の問題が解消されます。
オッズ比 ― 係数の解釈
ロジスティック回帰では、係数 \( \beta_j \) をそのまま「確率の増分」とは読めません。代わりに、係数を指数変換した オッズ比(Odds Ratio, OR)
\[
\mathrm{OR} = e^{\beta_j}
\]
が解釈の中心になります。これは「説明変数 \( x_j \) が 1 単位増えたとき、オッズが何倍になるか」を表します。
具体例を挙げましょう。ある説明変数の係数が \( \beta = 0.7 \) だったとすると、
\[
\mathrm{OR} = e^{0.7} \approx 2.01
\]
となり、その変数が 1 単位増えるごとに事象のオッズが約 2 倍になる、と解釈できます。逆に \( \beta \) が負ならオッズ比は 1 未満となり、事象が起こりにくくなる方向を意味します(\( \beta = 0 \) なら \( \mathrm{OR} = 1 \) で影響なし)。
オッズ比は「オッズ(確率の比)がさらに何倍になるか」を表す指標で、リスク比(確率そのものの比)とは別物です。事象がまれ(\( p \) が小さい)なときは両者は近い値になりますが、\( p \) が大きい場合はオッズ比がリスク比よりも 1 から離れた(大きめ・小さめの)値になります。「OR が 2 倍」を「確率が 2 倍」と早合点しないよう注意してください。
推定と検定
線形回帰の係数が最小二乗法で求まったのに対し、ロジスティック回帰の係数は 最尤推定(Maximum Likelihood Estimation, MLE) で求めます。これは「観測されたデータ(0/1 の並び)が最も起こりやすくなるように」係数を選ぶ方法で、その最大値が前述の尤度 \( L \) です。解析的には解けないため、反復計算(数値最適化)で求めます。
係数の有意性検定には主に 2 つあります。
- Wald 検定:各係数を標準誤差で割った統計量を用い、\( \beta_j = 0 \)(効果なし)かどうかを個別に検定します。手軽ですが、係数が大きい場合に精度が落ちることがあります。
- 尤度比検定(Likelihood Ratio Test):変数を含むモデルと含まないモデルの尤度を比べ、その比の対数から検定します。一般に Wald 検定より信頼性が高いとされます。
モデルの当てはまりの悪さを測る指標が 逸脱度(deviance) です。これは \( -2\ln L \) を基礎とした量で、値が小さいほど当てはまりが良いことを表します。2 つのモデルの逸脱度の差が、上記の尤度比検定の統計量(近似的に \( \chi^2 \) 分布に従う)になります。
準1級での位置づけ ― GLM の一員として
準1級では、ロジスティック回帰を単独の手法としてだけでなく、一般化線形モデル(Generalized Linear Model, GLM) の一種として理解しておくことが重要です。GLM は次の 3 要素で構成されます。
- 確率分布(指数型分布族):アウトカムが従う分布。ロジスティック回帰では 二項分布(binomial) を用います。二項分布は正規分布・ポアソン分布などと同じ 指数型分布族(exponential family) に属します。
- リンク関数(link function):平均(ここでは確率 \( p \))と線形予測子を結ぶ関数。ロジスティック回帰では ロジットリンク を使います。
- 線形予測子:\( \beta_0 + \beta_1 x_1 + \cdots + \beta_k x_k \)。
この枠組みで見ると、通常の線形回帰は「正規分布+恒等リンク」、ロジスティック回帰は「二項分布+ロジットリンク」、カウントデータのポアソン回帰は「ポアソン分布+対数リンク」と、同じ GLM の族の中で分布とリンクを差し替えたものとして統一的に整理できます。準1級ではこの対応関係が問われやすいので、押さえておきましょう。
準1級で問われる典型出題パターンと例題
回帰分析は準1級で毎回のように出題される最重要トピックです。計算問題として狙われるパターンはほぼ決まっており、典型論点を押さえて手を動かせるようにしておけば得点源になります。まず頻出論点を整理します。
- 単回帰の傾き・切片の計算:要約統計量(\(\sum x,\ \sum y,\ S_{xx},\ S_{xy}\))から \(\hat\beta_1=S_{xy}/S_{xx}\)、\(\hat\beta_0=\bar y-\hat\beta_1\bar x\) を求める。
- 決定係数・自由度調整済み決定係数:\(R^2=S_{xy}^2/(S_{xx}S_{yy})\)、\(\bar R^2=1-\dfrac{(1-R^2)(n-1)}{n-p-1}\) の計算と両者の違い。
- 回帰の分散分析表の穴埋め:回帰平方和 \(SS_R\)・残差平方和 \(SS_E\)・自由度から \(F=\dfrac{SS_R/p}{SS_E/(n-p-1)}\) を計算し、有意性を判定する。
- 回帰係数の t 検定:\(t=\hat\beta_j/\mathrm{SE}(\hat\beta_j)\) と自由度 \(n-p-1\)。
- 標準化偏回帰係数:\(\hat\beta_j^{*}=\hat\beta_j\dfrac{s_{x_j}}{s_y}\) による説明変数間の寄与比較。
- 多重共線性と VIF:\(\mathrm{VIF}_j=\dfrac{1}{1-R_j^2}\)(\(R_j^2\) は \(x_j\) を他の説明変数で回帰したときの決定係数)。目安として 10 超で強い多重共線性。
- ダミー変数の解釈:カテゴリ変数を 0/1 に符号化したときの係数は基準カテゴリとの差を表す。
- ロジスティック回帰のオッズ比:係数 \(\hat\beta_j\) に対しオッズ比 \(e^{\hat\beta_j}\)。1 単位増加でオッズが何倍になるかを解釈する。
以下、頻出タイプを 3 問取り上げ、計算過程を省略せずに解いていきます。
例題1:単回帰の傾き・切片・決定係数
次の 5 組のデータについて、単回帰モデル \(y=\beta_0+\beta_1 x+\varepsilon\) を最小二乗法で当てはめます。傾き \(\hat\beta_1\)、切片 \(\hat\beta_0\)、決定係数 \(R^2\) を求めなさい。
\((x,y)=(1,2),(2,3),(3,5),(4,4),(5,6)\)
まず基本の和を求めます。
\[
\sum x = 15,\quad \sum y = 20,\quad \sum x^2 = 55,\quad \sum y^2 = 90,\quad \sum xy = 69
\]
平均は \(\bar x=15/5=3\)、\(\bar y=20/5=4\) です。次に偏差平方和・偏差積和を計算します。
\[
S_{xx}=\sum x^2-\frac{(\sum x)^2}{n}=55-\frac{15^2}{5}=55-45=10
\]
\[
S_{yy}=\sum y^2-\frac{(\sum y)^2}{n}=90-\frac{20^2}{5}=90-80=10
\]
\[
S_{xy}=\sum xy-\frac{\sum x\sum y}{n}=69-\frac{15\times20}{5}=69-60=9
\]
これらから傾きと切片が求まります。
\[
\hat\beta_1=\frac{S_{xy}}{S_{xx}}=\frac{9}{10}=0.9
\]
\(x\) が 1 増えるごとに \(y\) が平均 0.9 増える、という意味です。
\[
\hat\beta_0=\bar y-\hat\beta_1\bar x=4-0.9\times3=4-2.7=1.3
\]
決定係数は次のとおりです。
\[
R^2=\frac{S_{xy}^2}{S_{xx}S_{yy}}=\frac{9^2}{10\times10}=\frac{81}{100}=0.81
\]
検算:残差平方和から確認します。予測値は \(\hat y=1.3+0.9x\) なので \(\hat y=(2.2,\ 3.1,\ 4.0,\ 4.9,\ 5.8)\)、残差は \((-0.2,\ -0.1,\ 1.0,\ -0.9,\ 0.2)\)。残差平方和は \(0.04+0.01+1.0+0.81+0.04=1.9\)。よって \(R^2=1-S_E/S_{yy}=1-1.9/10=0.81\) となり一致します。
\(\hat\beta_1=S_{xy}/S_{xx}=0.9\)、\(\hat\beta_0=\bar y-\hat\beta_1\bar x=1.3\)、\(R^2=S_{xy}^2/(S_{xx}S_{yy})=0.81\)。回帰式は \(\hat y=1.3+0.9x\)。まず \(S_{xx},S_{yy},S_{xy}\) を「二乗和 −(和の二乗)/n」の形で正確に出すのが最短ルートです。
例題2:自由度調整済み決定係数
サンプルサイズ \(n=20\)、説明変数の個数 \(p=3\) の重回帰モデルで、決定係数が \(R^2=0.80\) でした。自由度調整済み決定係数 \(\bar R^2\) を求めなさい。
自由度調整済み決定係数の定義に数値を代入します。
\[
\bar R^2=1-\frac{(1-R^2)(n-1)}{n-p-1}=1-\frac{(1-0.80)(20-1)}{20-3-1}
\]
分子は \((1-0.80)\times19=0.20\times19=3.8\)、分母は \(20-3-1=16\) です。
\[
\bar R^2=1-\frac{3.8}{16}=1-0.2375=0.7625
\]
\(R^2=0.80\) に対し \(\bar R^2=0.7625\) と小さくなりました。自由度調整済み決定係数は、説明変数を増やして生じる「見かけ上の当てはまりの良さ」を自由度で罰する指標であり、常に \(\bar R^2\le R^2\) が成り立ちます。
\(\bar R^2=1-\dfrac{(1-0.80)(19)}{16}=1-0.2375=0.7625\)。分母 \(n-p-1\) の「\(-1\)」は切片の自由度である点に注意。説明変数を無闇に増やすと \(\bar R^2\) はむしろ下がるため、変数選択の指標として使われます。
例題3:ロジスティック回帰のオッズ比
ある二値アウトカム(発症=1)に対するロジスティック回帰で、説明変数 \(x\)(服薬あり=1)の回帰係数が \(\hat\beta=0.693\) と推定されました。
(1) \(x\) のオッズ比を求め、意味を述べなさい。
(2) \(x=0\) のときの発症確率が \(p_0=0.20\) であるとき、\(x=1\)(1 単位増加)での発症確率 \(p_1\) を求めなさい。
(1) オッズ比:ロジスティック回帰では係数の指数がオッズ比になります。
\[
\mathrm{OR}=e^{\hat\beta}=e^{0.693}\approx 2.0
\]
(\(\ln 2\approx0.693\) なので \(e^{0.693}\approx2\) です。)\(x\) が 1 単位増える(服薬ありになる)と、発症のオッズが約 2 倍になることを意味します。
(2) 確率の計算:まず \(x=0\) のオッズを求めます。
\[
\text{odds}_0=\frac{p_0}{1-p_0}=\frac{0.20}{0.80}=0.25
\]
オッズ比を掛けると \(x=1\) のオッズが得られます。
\[
\text{odds}_1=\text{odds}_0\times\mathrm{OR}=0.25\times2=0.50
\]
オッズを確率に戻します。
\[
p_1=\frac{\text{odds}_1}{1+\text{odds}_1}=\frac{0.50}{1.50}=\frac{1}{3}\approx0.333
\]
検算:\(p_1=0.333\) のオッズは \(0.333/0.667\approx0.50\) で \(\text{odds}_1\) と一致し、\(0.50/0.25=2.0\) とオッズ比も再現できます。発症確率は 0.20 から約 0.33 へ上昇しました。オッズは 2 倍でも、確率そのものが 2 倍(0.40)になるわけではない点が重要です。
\(\mathrm{OR}=e^{0.693}\approx2.0\)(オッズが約 2 倍)。確率は「確率→オッズ→オッズ比を掛ける→確率へ戻す」の順で計算し、\(p_0=0.20\Rightarrow p_1=1/3\approx0.333\)。オッズ比 2 倍と確率 2 倍を混同しないことが解釈のポイントです。
Rによる回帰分析の実装
ここからは R の組み込みデータセット mtcars(32 車種の燃費・エンジン諸元データ)を使い、重回帰から多重共線性の診断、変数選択、ロジスティック回帰までを一通り実装します。応答変数は主に mpg(燃費、miles/gallon)です。
重回帰モデルの当てはめ
車重 wt・馬力 hp・排気量 disp の 3 変数で燃費を説明する重回帰モデルを当てはめ、summary() で結果を確認します。
model <- lm(mpg ~ wt + hp + disp, data = mtcars)
summary(model)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.105505 2.110815 17.579 < 2e-16 ***
wt -3.800891 1.066191 -3.565 0.00133 **
hp -0.031157 0.011436 -2.724 0.01097 *
disp 0.000937 0.010350 0.091 0.92851
Residual standard error: 2.639 on 28 degrees of freedom
Multiple R-squared: 0.8268, Adjusted R-squared: 0.8083
F-statistic: 44.57 on 3 and 28 DF, p-value: 8.65e-11
決定係数 \(R^2=0.827\)、自由度調整済み \(\bar R^2=0.808\) で、燃費の変動の約 83% を 3 変数で説明できています。F 統計量 44.57(p≈8.7×10⁻¹¹)はモデル全体が有意であることを示します。係数を見ると
wt は −3.80(p=0.0013)で、車重が 1000 lb 増えるごとに燃費が約 3.8 mpg 下がると読めます。hp も −0.031(p=0.011)で有意ですが、disp は係数ほぼ 0・p=0.93 で有意ではありません。disp の情報が wt や hp と重複している可能性が示唆されます。多重共線性の確認(VIF)
disp の非有意は多重共線性が原因かもしれません。car パッケージの vif() で分散拡大係数を確認します。
library(car)
vif(model)
wt hp disp
4.844618 2.736633 7.324966
VIF は
disp=7.32、wt=4.84、hp=2.74 でした。一般的な目安(VIF>10 で強い多重共線性)は超えていないものの、disp の VIF が最も大きく、排気量が車重・馬力と強く相関していることがわかります。これが disp の係数を不安定にし、非有意になった一因と考えられます。多重共線性が疑われる変数は、変数選択で落とすことを検討します。変数選択(AIC によるステップワイズ法)
AIC を基準にした変数選択を step() で行います。direction = "both" は変数の追加と削除の両方を試す方法です。
step(model, direction = "both")
Start: AIC=63.2
mpg ~ wt + hp + disp
Df Sum of Sq RSS AIC
- disp 1 0.057 195.05 61.21
<none> 194.99 63.20
- hp 1 51.708 246.70 68.74
- wt 1 88.541 283.53 73.20
Step: AIC=61.21
mpg ~ wt + hp
Call:
lm(formula = mpg ~ wt + hp, data = mtcars)
Coefficients:
(Intercept) wt hp
37.22727 -3.87783 -0.03177
disp を除くと AIC が 63.2 から 61.2 へ下がり、最終モデルは mpg ~ wt + hp に落ち着きました。多重共線性の疑いが強く非有意だった disp が自動的に除外され、簡潔で解釈しやすいモデルになっています。wt(−3.88)と hp(−0.032)はいずれも燃費を下げる方向で、直感とも一致します。ロジスティック回帰とオッズ比
最後に、エンジン形状 vs(0=V 型、1=直列)を燃費 mpg と車重 wt で予測するロジスティック回帰を当てはめます。family = binomial を指定します。
logit_model <- glm(vs ~ mpg + wt, data = mtcars, family = binomial)
summary(logit_model)
exp(coef(logit_model)) # オッズ比
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -8.5001 6.0757 -1.399 0.1618
mpg 0.6809 0.3068 2.219 0.0265 *
wt 0.4756 1.1194 0.425 0.6710
(Intercept) mpg wt
0.0002034 1.975726 1.608889
mpg の係数は 0.681(p=0.027)で有意、オッズ比は \(e^{0.681}\approx1.98\) です。燃費が 1 mpg 上がるごとに、そのエンジンが直列型(vs=1)であるオッズが約 2 倍になると読めます。低燃費の大型エンジンほど V 型(vs=0)になりやすい、という現実の傾向と整合的です。一方 wt の係数は 0.476(p=0.67)で有意ではなく、mpg を調整すると車重は vs の説明にほとんど寄与しません。オッズ比を確率に直すときは、例題3 と同様に「確率→オッズ→オッズ比→確率」の変換を用います。実務でのポイント
回帰分析は、統計検定準1級の得点源であると同時に、製薬・臨床開発の実務でも日常的に使う中核的な手法です。試験対策で学んだ理論は、そのまま現場のデータ解析につながります。
実務での代表的な使いどころを挙げます。まず、ベースライン値や年齢・体重といった共変量を回帰モデルに取り込み、治療効果をより精度良く推定する共変量調整(ANCOVA)は、ランダム化比較試験の主要解析でも標準的に用いられます。投与群や施設をダミー変数で表現したり、交互作用項で部分集団ごとの効果差を検討したりするのも回帰の枠組みです。奏効の有無や有害事象の発現といった二値アウトカムには、ロジスティック回帰を用い、オッズ比で効果の大きさを表現します。
ここで意識したいのは、モデルを「説明(要因の効果を解釈したい)」目的で作るのか、「予測(新しい対象の結果を当てたい)」目的で作るのかによって、変数選択の姿勢が変わるという点です。特に検証的試験では、データを見てから変数を選ぶと第一種の過誤や多重共線性の落とし穴にはまりやすいため、解析に用いる変数やモデルは統計解析計画書(SAP)で事前に規定しておくのが原則です。ステップワイズ法のような自動選択は、探索的な解析や予測モデルの構築に留め、結果の解釈は慎重に行う必要があります。
・共変量調整(ANCOVA)・ダミー変数・交互作用・ロジスティック回帰は、いずれも回帰分析の応用であり、試験知識がそのまま実務に直結します
・モデルは「説明」か「予測」かで作り分け、検証的試験では変数を事前に規定します
・多重共線性やステップワイズ法の落とし穴を理解したうえで、VIF やAIC/BIC を道具として使いこなすことが重要です
共変量調整の実務的な扱いについては、関連記事の共変量調整(ANCOVA)徹底解説もあわせてご覧いただくと理解が深まります。
この記事をより深く理解するための参考書籍
回帰分析をさらに深く学び、統計検定準1級の対策を万全にしたい方に、おすすめの書籍をご紹介します。






関連記事
回帰分析と関連の深いテーマや、統計検定準1級シリーズの他の記事もあわせてご覧ください。
- 統計検定準1級 攻略ガイド ― 出題範囲・勉強法・おすすめ参考書
- 統計検定準1級「多変量解析」攻略 ― PCA・MDS・正準相関
- 統計検定準1級「分散分析・実験計画法」攻略
- GLMM(一般化線形混合モデル)とは?Rで反復測定データを解析する基本
まとめ
本記事では、統計検定準1級で頻出の回帰分析について、基礎理論から典型出題、Rによる実装までを体系的に整理しました。単回帰の最小二乗推定 \(\hat\beta_1=S_{xy}/S_{xx}\) から始まり、重回帰の行列表現、偏回帰係数と決定係数、そして自由度調整済み決定係数へと進み、モデルの当てはまりと複雑さのバランスをどう測るかを確認しました。続いて、多重共線性を診断する VIF、AIC・BIC などの規準を用いた変数選択、そして二値アウトカムを扱うロジスティック回帰とオッズ比の考え方を押さえました。
準1級では、これらの計算問題が繰り返し出題されます。本記事の例題で示したように、要約統計量から傾き・切片・決定係数を求め、自由度調整済み決定係数を計算し、ロジスティック回帰の係数からオッズ比を導く――この一連の流れを手を動かして再現できるようにしておけば、試験本番でも確実に得点できるはずです。さらに R で lm()・glm()・step()・vif() を実際に動かしてみることで、理論と実装が結びつき、製薬・臨床開発の実務でも回帰分析を自信を持って使いこなせるようになります。回帰分析を「計算できる」だけでなく「解釈できる」段階まで高めることが、統計検定合格の先にある実務での大きな強みになります。