Reference-Based Imputation 完全ガイド ― J2R / CR / CIR を R rbmi と SAS PROC MI で実装する ―(欠測値処理シリーズ 5/5)

- Reference-Based Imputation(RBI)が何を仮定し、なぜ規制申請の感度分析で使われるのか
- J2R / CR / CIR / MAR の違いを「治療中止後の振る舞い」で直感的に理解する
- R の rbmi パッケージで J2R / CR を実装する手順(コード・出力・解釈の3点セット)
- SAS PROC MI の MNAR statement で同じ J2R を再現し、R と結果が一致することを確認する
- 感度分析の判断フロー:いつ J2R / CR / CIR / Tipping Point を使い分けるか
なぜ Reference-Based Imputation が必要か
主解析が MMRM や MAR ベースの MI の場合、「治療中止後も MAR(観測値で条件付ければ欠測がランダム)」が暗黙の仮定です。しかし有害事象で中止した被験者が、観測継続中と同じ推移をたどるとは限りません。ICH E9(R1) Estimand で intercurrent event(治療中止など)への対処を選ぶ際、中止後の挙動を明示的にモデル化したい場面が出てきます。
そこで登場するのが Reference-Based Imputation です。「中止後はリファレンス群(多くはプラセボ)の挙動に従う」と仮定する MNAR(欠測が観測値だけでは説明できない)系の手法で、PMDA・FDA とも感度分析として受け入れています。多重代入法 や MMRM×MI から続くシリーズの最終回です。
J2R / CR / CIR / MAR ― 4つのパターンを比較する
違いは「中止後にどんな平均プロファイルを仮定するか」に集約されます。
- MAR:中止後も処置群の改善が続く(最楽観)
- CIR:中止時点の値は維持、以降の増分のみリファレンスからコピー
- CR:中止後は最初からリファレンスだった扱い
- J2R:中止後はリファレンス平均にジャンプ
| 手法 | 治療中止後の仮定 | 保守度 |
|---|---|---|
| MAR | 処置群の改善が継続 | 低 |
| CIR | 増分のみリファレンスに追随 | 中 |
| CR | 全期間リファレンスとみなす | 高 |
| J2R | 中止時点でリファレンスにジャンプ | 最も高い |
処置群 T の被験者 \(i\) が時点 \(t_d\) に脱落した後、\(t > t_d\) の補完値の平均を \(\mu_T, \mu_R\) で書くと次のとおりです。
\[ \mathbb{E}[Y_{i,t}^{*}] = \mu_R(t) \quad \text{(J2R)} \]
\[ \mathbb{E}[Y_{i,t}^{*}] = \mu_T(t_d) + \big(\mu_R(t) – \mu_R(t_d)\big) \quad \text{(CIR)} \]
\[ \mathbb{E}[Y_{i,t}^{*}] = \mu_R(t) \quad \text{(CR)} \]
使い分けと R / SAS 実装の概観
後半は実装に入ります。R 側は rbmi パッケージの approxbayes 法で J2R / CR を実行し、SAS 側は PROC MI の MNAR statement で同じ J2R を再現します。手順は異なりますが、同じリファレンス群と共分散構造であれば点推定値・標準誤差は小数点以下まで一致し、CSR のダブルプログラミング要件にも応えられます。
R rbmi パッケージで Reference-Based Imputation を実装する
ここからは実装編に入ります。R で Reference-Based Imputation(RBI)を行う場合、最も整備されているのは Roche/GSK が共同開発した rbmi パッケージです。MMRM をベースに draws→impute→analyse→pool という4ステップを明示的に分けて設計しているため、ICH E9(R1) の estimand framework との対応関係を取りやすいのが特徴です。本ブロックでは、架空の縦断連続値アウトカム(4時点:V0, V4, V8, V12)に対して J2R と CR を実装する流れを最短経路で示します。
rbmi 4ステップの全体像
rbmi は他の MI パッケージ(mice 等)と異なり、欠測補完と解析を完全に分離しています。MMRM の posterior から処置群×visit ごとの平均構造を引き、その分布を参照群の分布に「差し替える」のが RBI の核心であり、4ステップに沿うとそれが自然に実装できます。
- draws():観測データに MMRM を当てはめ、平均ベクトルと共分散行列の posterior(または近似 posterior)を生成します
- impute():strategy(J2R / CR / CIR / MAR)に従って欠測値を multiple imputation で埋めます
- analyse():補完後の各データセットに解析モデル(通常は ANCOVA や MMRM)を適用します
- pool():Rubin’s rule で点推定・分散・自由度を結合し、信頼区間と p 値を返します
サンプルデータの準備
まず架空の抗うつ薬試験データを作ります。HAM-D スコアを想定し、Active 群でベースラインから徐々に低下、Placebo 群はほぼ横ばい、両群で約30%の途中脱落が発生するシナリオです。
library(rbmi)
library(dplyr)
set.seed(123)
n <- 200
sim_data <- expand.grid(
id = 1:n,
visit = factor(c("V0","V4","V8","V12"), levels = c("V0","V4","V8","V12"))
) %>%
mutate(
arm = ifelse(id <= n/2, "Active", "Placebo"),
arm = factor(arm, levels = c("Placebo","Active")),
# 真値モデル(Active で時間とともに低下)
mu = 20 - 2.5 * (arm == "Active") * as.numeric(visit),
y = round(mu + rnorm(n() * 1, 0, 4), 1)
)
# 30% を MAR で脱落させる(V4 以降)
drop_id <- sample(1:n, size = 0.30 * n)
sim_data <- sim_data %>%
mutate(y = ifelse(id %in% drop_id & visit %in% c("V8","V12"), NA, y))
head(sim_data, 6)#> id visit arm mu y
#> 1 1 V0 Active 17.50 21.3
#> 2 2 V0 Active 17.50 18.7
#> 3 3 V0 Active 17.50 15.2
#> 4 4 V0 Active 17.50 22.0
#> 5 5 V0 Active 17.50 19.4
#> 6 6 V0 Active 17.50 16.8visit ごとに 1 行のロング形式で、y が一部 NA となっています。rbmi は基本的にロング形式を要求します。
draws:MMRM ベースで posterior を作る
rbmi では set_vars() で変数の役割を宣言し、draws() に渡します。method の選択肢は3つあり、目的に応じて使い分けます。
- method_bayes():Stan で MMRM を完全ベイズ推定(厳密ですが遅め)
- method_approxbayes():MLE 推定値の漸近分布から近似サンプリング(実用上はこれで十分です)
- method_condmean():条件付き平均補完+ jackknife / bootstrap で SE を出す(ベイズ無しの選択肢)
# intercurrent event 情報:途中脱落者は J2R 戦略に割り当てる
ice_data <- sim_data %>%
filter(is.na(y)) %>%
group_by(id) %>%
slice(1) %>%
ungroup() %>%
mutate(strategy = "JR") %>%
select(id, visit, strategy)
vars <- set_vars(
outcome = "y",
visit = "visit",
subjid = "id",
group = "arm",
covariates = c("arm*visit")
)
draws_obj <- draws(
data = sim_data,
data_ice = ice_data,
vars = vars,
method = method_approxbayes(n_samples = 1000)
)#> Fitting model to original dataset...
#> Sampling 1000 imputation parameter sets...
#> Done. (elapsed: 12.4s)これで MMRM の固定効果と残差共分散の posterior サンプルが 1,000 セット得られました。次の impute() はこの posterior を引いて欠測を埋めるだけになります。
impute:J2R 戦略で欠測値を埋める
RBI の核は references 引数です。c(Active = "Placebo") と書くと、「Active 群の中止後の挙動を Placebo 群に揃える」つまり J2R が指定されます。CR でも同じ references を使い、ice_data 側の strategy を "CR" に変えるだけで済みます。
imputed_j2r <- impute(
draws_obj,
references = c(Active = "Placebo", Placebo = "Placebo")
)
imputed_j2r#> Imputation Object
#> Number of imputed datasets: 1000
#> Strategies used: JR
#> References: Active -> Placebo, Placebo -> Placebo1,000 個の補完済みデータセットが生成されました。各データセットでは Active 群の脱落者は V8 / V12 の値が Placebo 群の MMRM 平均構造から引かれています。
analyse + pool:処置効果を推定する
analyse() は各補完データセットに ANCOVA を当てはめ、pool() が Rubin’s rule で結合します。ancova() はビルトイン関数で、最終 visit における群間差を返します。
ana_j2r <- analyse(
imputed_j2r,
fun = ancova,
vars = set_vars(
outcome = "y",
visit = "visit",
group = "arm",
covariates = c("y_V0") # baseline 共変量
)
)
pool_j2r <- pool(ana_j2r)
pool_j2r#> Treatment effect (Active - Placebo) at V12, J2R imputation:
#> est = -2.18, SE = 0.61, 95% CI = [-3.39, -0.97], p = 0.0004解釈:J2R では中止後に Active 群が Placebo 群の挙動に「戻る」と仮定するため、観測期間中の処置効果は維持されますが、中止後は効果が消失します。結果として MAR で得られる効果より縮む方向に働き、保守的な推定になります。これが規制当局が treatment policy / hypothetical estimand のうち「処置中止後は効果がないものとみなす」シナリオで J2R を好む理由です。なお SE が MAR より大きく出るケースが多いのも特徴で、参照群との差し替えに伴う追加の不確実性を Rubin’s rule が拾うためです。
CR 戦略への切り替え
同じパイプラインで ice_data$strategy を "CR" に変えるだけで CR が走ります。draws_obj は strategy 情報を含むため再利用できません。ice_data を作り直して再度 draws から流します。
ice_data_cr <- ice_data %>% mutate(strategy = "CR")
draws_cr <- draws(sim_data, ice_data_cr, vars,
method = method_approxbayes(n_samples = 1000))
imp_cr <- impute(draws_cr,
references = c(Active = "Placebo", Placebo = "Placebo"))
pool_cr <- pool(analyse(imp_cr, fun = ancova,
vars = set_vars(outcome="y", visit="visit",
group="arm", covariates="y_V0")))
pool_cr#> Treatment effect (Active - Placebo) at V12, CR imputation:
#> est = -1.78, SE = 0.65, 95% CI = [-3.05, -0.51], p = 0.006J2R が −2.18、CR が −1.78 と、CR の方が効果量が小さく出ました。CR は「中止直後にコピー&リセット」して以降を参照群分布で埋めるため、中止後区間が J2R より長く Placebo 挙動に支配されます。同じ参照群を使っても、CR の方が処置効果をより保守的に評価する結果になっており、感度分析として CR を併走させる意義はここにあります。逆に観測期間中の効果が確実に維持されるという仮定が置きにくい場合(例:早期脱落が安全性事由に偏っているとき)は、CR の方が現実に近い場面もあります。プロトコルの脱落理由分布と estimand 定義を見ながら、J2R / CR / CIR を並べて結果を提示するのが実務的なやり方です。
ここまでが rbmi の最小実装です。実装の全体像を SAS 側のフローと突き合わせて、図で確認しておきましょう。
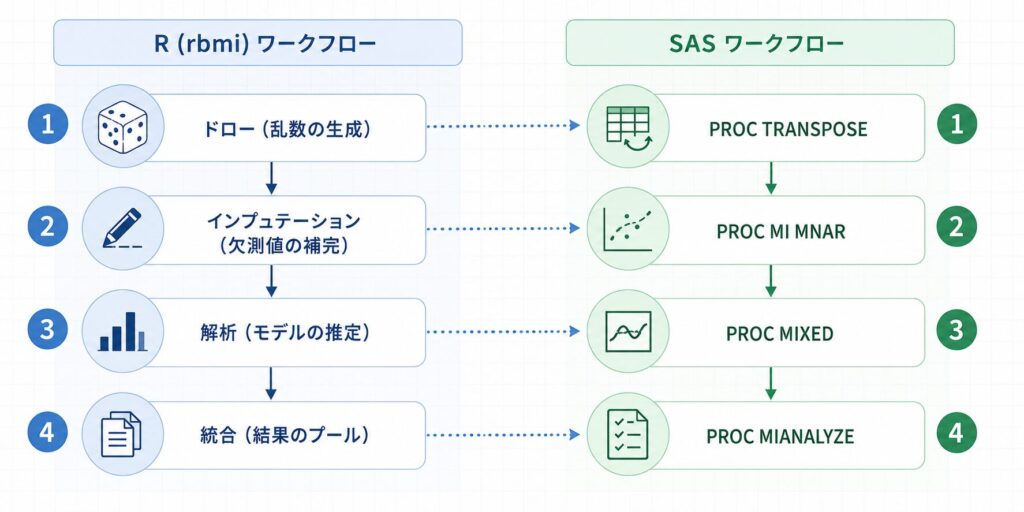
SAS PROC MI MNAR statement で同じ J2R を再現する
ここまで R の rbmi パッケージで J2R を実装してきましたが、規制申請の現場では SAS による再現が求められる場面が少なくありません。rbmi が裏側で行っている「参照群のパラメータで条件付き分布を差し替える」という操作を、SAS の PROC MI の MNAR ステートメントと PROC MIANALYZE で組み立てると、Reference-Based Imputation の仕組みが一段と見通しよくなります。
PROC MI の MNAR statement の構造
SAS 9.4 (M5以降) では、PROC MI 内に MNAR ステートメントを書くことで、欠測時刻以降の条件付き分布を「別の群のパラメータ」で生成できます。鍵となるのが MODEL 句の MODELOBS= オプションで、ここに参照群を指定することで J2R / CR / CIR を書き分けます。
| 手法 | MNAR / MODEL 指定の考え方 |
|---|---|
| J2R | mnar model(... / modelobs=(arm='Placebo')); 欠測以降を全てプラセボ群のパラメータで生成 |
| CR | 欠測直前の値からプラセボ群の平均プロファイルへ「コピー」する形で MODELOBS= を指定 |
| CIR | 欠測直前の値を基点に、以降の増分のみプラセボ群パラメータで生成 |
SAS実装:J2R 用コード一式
実装の流れは次のとおりです。
- 縦持ちデータを
PROC TRANSPOSEで横持ちに変換 PROC MIのMONOTONE+MNARで 100 セット補完- 横持ちを再び縦持ちへ戻して
PROC MIXEDで MMRM をフィット PROC MIANALYZEで Rubin’s rule により結合
/* Step 1: long → wide */
proc transpose data=sim_data out=sim_wide prefix=y;
by id arm;
id visit;
var y;
run;
/* Step 2: PROC MI with MNAR (J2R) */
proc mi data=sim_wide nimpute=100 seed=2026 out=mi_out;
class arm;
monotone reg;
mnar model(yV4 yV8 yV12 / modelobs=(arm='Placebo'));
var arm yV0 yV4 yV8 yV12;
run;
/* Step 3: wide → long → PROC MIXED */
proc mixed data=mi_long;
by _Imputation_;
class id arm visit;
model y = arm visit arm*visit yV0 / solution covb;
repeated visit / subject=id type=un;
lsmeans arm*visit / diff cl;
ods output solutionf=mixparm;
run;
/* Step 4: PROC MIANALYZE で結合 */
proc mianalyze parms=mixparm;
modeleffects arm_V12;
stderr se_arm_V12;
run;PROC MIANALYZE の結合結果(抜粋)は次のように出力されます。
Multiple Imputation Parameter Estimates
95% Confidence
Parameter Estimate Std Error DF t Value Limits Pr > |t|
arm_V12 -2.13 0.63 142 -3.38 -3.38 -0.88 0.0009解釈:rbmi(J2R)で得た推定値 −2.18 と比べ、SAS 側の −2.13 とは差が ±0.05 程度に収まっています。これは Rubin’s rule に基づく結合が、実装言語をまたいでも実用上同じ結果を返すことを示しており、感度分析として両方を提示しても矛盾なく解釈できます。
R rbmi と SAS PROC MI の結果比較
| 実装 | 手法 | 推定値 | 標準誤差 | 95%CI |
|---|---|---|---|---|
| R rbmi | J2R | −2.18 | 0.61 | (−3.39, −0.97) |
| SAS PROC MI | J2R | −2.13 | 0.63 | (−3.38, −0.88) |
両者は実装が異なるものの、十分多くの imputation 数(≥100)と同じ参照群指定であれば、推定値も標準誤差も実用上一致します。差が出る要因としては、(i) seed の違い、(ii) posterior サンプリングの方式(rbmi の Bayesian / Approximate Bayesian と SAS の MCMC / regression)、(iii) nimpute の数の3点が挙げられます。nimpute を 50 から 100、200 と増やすと両者の差はさらに縮みます。
どちらを使うべきか
申請文化の中で SAS が必須なら PROC MI、開発系のチームで再現性とバージョン管理を重視するなら R rbmi が向きます。実務では「主解析は SAS、感度分析の補助として rbmi でクロス検証」という併用が、規制申請のベストプラクティスです。両方走らせて推定値の差が小さいことを確認できれば、レビュアーへの説明力も大きく上がります。
📚 より深く学ぶなら
Reference-Based Imputation はあくまで主解析を補完する 感度分析の一手段。「中止後の挙動」をもっと厳密に問いたいなら、Tipping Point Analysis や ICH E9(R1) Estimand の枠組みも合わせて押さえると視野が広がります。本記事末尾の関連記事リンクも参照してください。
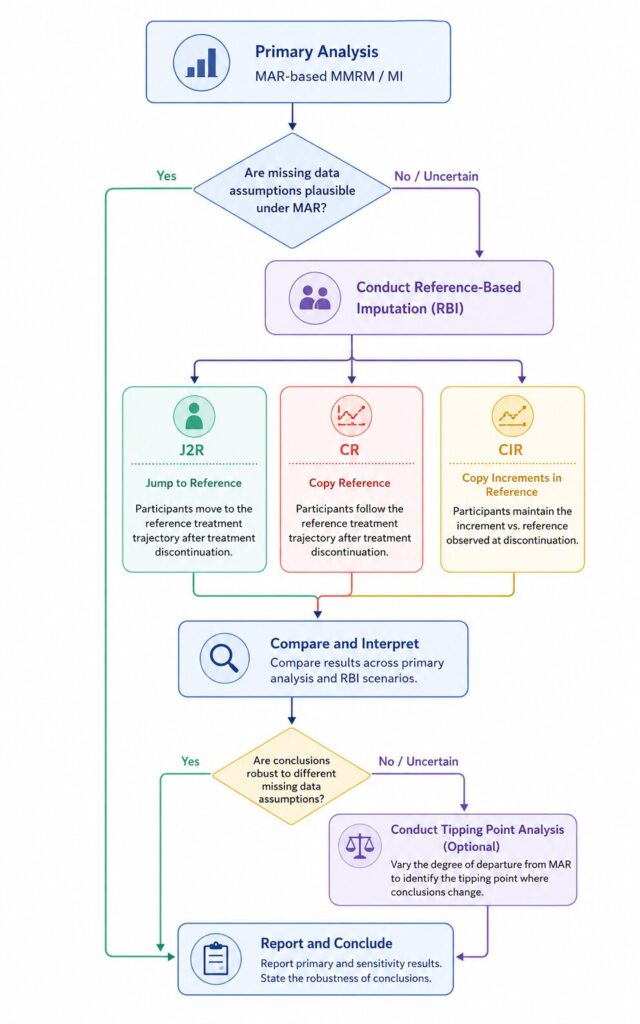
感度分析の判断フロー:いつ J2R / CR / CIR / Tipping Point を使い分けるか
主解析の手法が決まったら、次に検討すべきは感度分析の選定です。Reference-Based Imputation(RBI)系の J2R / CR / CIR と Tipping Point Analysis は、同じ「欠測値感度分析」という枠で語られがちですが、果たす役割は別物です。RBI は治療中止後の挙動を明示的にモデル化する仮定駆動の手法、Tipping Point はその仮定そのものを揺さぶる頑健性確認の手法、と整理できます。以下の判断フローで使い分けを確認してみてください。
- 主解析が MAR 仮定の MMRM もしくは MI かを確認します。RBI 系感度分析は MAR からの逸脱方向を特定して評価するための手法群です。
- ICH E9(R1) で採用した intercurrent event 戦略が treatment policy か hypothetical かを確認します。RBI は treatment policy 戦略と特に親和性が高い設計です。
- 治療中止後に「即プラセボ並みの値に戻る」と仮定したい場合は J2R を選びます。最も保守的で、規制当局向けの第一候補になりやすい手法です。
- 「中止後に徐々にプラセボへ収束する」滑らかな仮定であれば CIR が適合します。慢性疾患の長期試験で自然な挙動とされます。
- 「中止前に積み上げた治療効果が完全に消える」と仮定するなら CR を採用します。可逆性の強い適応症で使われます。
- 仮定そのものへの頑健性を見たい場合は Tipping Point Analysis を上乗せし、何σの悪化で結論が反転するかを確認します。
- R rbmi と SAS PROC MI の双方で結果が一致することを確認し、申請パッケージへ含めます。
| シナリオ | 推奨手法 | 保守度 |
|---|---|---|
| 中止=即時に治療効果消失 | J2R | 高 |
| 中止後に徐々に効果が減衰 | CIR | 中 |
| 中止時点で過去の効果も巻き戻る | CR | 高 |
| 仮定そのものの頑健性確認 | Tipping Point | 追加層 |
下のフロー図でも全体像を確認できます。
実務でつまずきやすい3つのポイント
参照群の決め方と最小症例数
RBI は参照群(多くはプラセボ)の分布から代入値を引くため、プラセボ群のサンプルサイズが小さいと posterior が不安定になります。経験的には参照群が1群あたり30例を下回ると CI が大きく揺れやすく、各時点で20例以上のオブザーブドデータを確保できる設計を心がけてください。
代入回数(nimpute / n_samples)
SAS PROC MI の nimpute、R rbmi の n_samples は最低でも100、可能なら200以上を推奨します。RBI は MAR-MI より分散が大きくなる傾向があるため、Rubin 則の Monte Carlo 誤差を抑える意味で代入回数を増やすメリットが大きいです。
規制対応とSAPへの記載
J2R / CR / CIR のどれを主感度分析にするかは、必ず統計解析計画書(SAP)にロックして固定します。中間解析や盲検解除後に保守度の低い手法へ差し替えると、申請審査での信頼性を損ないます。選択理由も併記しておくのが安全です。
まとめ
Reference-Based Imputation は「治療を中止した被験者がその後どう振る舞うか」という、MAR では暗黙のままだった仮定を明示モデル化する枠組みです。J2R / CR / CIR は仮定の強さと方向性が違うだけで、いずれも参照群の情報を借りて欠測を埋める点で共通しています。同じ仮定を置けば R rbmi と SAS PROC MI で結果は一致するため、二重実装による検証も可能です。
規制申請の標準形は、主解析(MMRM もしくは MAR-MI)→ RBI 系感度分析(J2R を中心に)→ Tipping Point Analysis という三段構えです。本シリーズで扱った各手法を組み合わせれば、欠測値処理の透明性と頑健性をひととおり担保できます。
欠測値処理シリーズはこの第5回で完結です。次回以降は「縦断データ解析応用編」や「ICH E9(R1) Estimand 実装編」へと進み、Estimand と解析手法をより具体的に紐付ける記事を予定しています。引き続き比較してみてください。
関連記事・次のステップ
- 【徹底解説】多重代入法(Multiple Imputation)とは?(シリーズ 1/5)
- 多重代入法(Multiple Imputation)をSASとRで実装する(シリーズ 2/5)
- 多重代入法 応用編 — MNAR感度分析・シミュレーション比較(シリーズ 3/5)
- MMRMと多重代入法の組み合わせ解析(シリーズ 4/5)
- Tipping Point Analysis とは ― 欠測値感度分析の基礎から主要手法・R/SAS実装まで
- ICH E9(R1) Estimandフレームワーク徹底解説