Tipping Point Analysisとは ― 欠測値感度分析の基礎から主要手法・R/SAS実装まで ―

- Tipping Point Analysisとは何か(基本概念と目的)
- One-way / Two-wayなど主要手法の違いと使い分け
- One-way Tipping Point Analysisの数理的背景
- R の mice パッケージを使った実装方法(コード付き)
- SAS の PROC MI / PROC MIXED / PROC MIANALYZE を用いた実装
はじめに
臨床試験において、欠測値(missing data)への対応は避けられない課題です。MAR(Missing At Random:ランダム欠測)を仮定した一次解析の結果が、欠測のメカニズムに対してどの程度頑健(robust)であるかを評価することは、規制当局への申請においても極めて重要です。
Tipping Point Analysis(ティッピングポイント解析)とは、欠測値に補正量(Δ)を加えたとき、統計的結論が逆転する閾値を求める感度分析手法です。「欠測値がどれほど悪化していれば結論が変わるか」を定量的に示すことで、試験結果の頑健性を客観的に評価できます。
ICH E9(R1)ガイドラインでも感度分析の重要性が明示されており、製薬企業の申請資料においてTipping Point Analysisの実施は事実上の標準となっています。SAS・R 双方での実装が実務上求められることも多く、本記事では基礎概念から実装まで体系的に解説します。
Tipping Point Analysisとは
Tipping Point Analysisのコアとなるアイデアは、欠測値に対するデルタ(Δ)調整です。
MAR下で多重代入(Multiple Imputation; MI)を行った後、欠測していた観測値に補正量Δを加算します。このΔは「欠測値がMAR推定値よりもどれだけ悪化していたか」を表します。Δを連続的に変化させながら一次解析を繰り返すことで、次の条件を満たすΔの値――ティッピングポイントを特定します。
\[ p\text{値} \geq 0.05 \quad \text{(または95\%CIが0を含む)となる最小の} \Delta \]
ティッピングポイントが臨床的に非現実的なほど大きければ「欠測値の影響を受けにくい頑健な結果だ」と判断できます。逆に小さければ、欠測仮定に対する脆弱性を示します。
ΔはMARからの逸脱量です。「ΔがXXであれば結論が逆転する」という事実は、単独では意味を持たず、臨床的に現実的な範囲かどうかを臨床チームと議論したうえで解釈する必要があります。MCID(最小臨床的意義差)などを参照軸にすることが多いです。
主な手法の整理
| 手法名 | 補正の方向 | 概要 |
|---|---|---|
| One-way Tipping Point | 一方向(通常は治療群) | 治療群の欠測値にΔを加算し、結論が逆転するΔを特定。最も広く用いられる基本手法 |
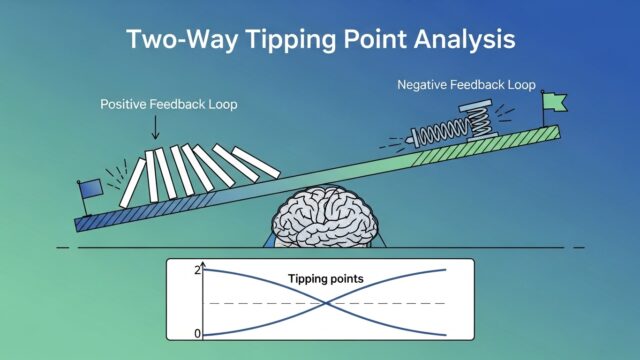
| Two-way Tipping Point | 双方向(対照群Δ₁+治療群Δ₂) | 両群に補正を行い、結論が変わる境界を二次元平面で可視化する。より包括的な感度分析 |
| Return-to-Baseline | 特定の補正量に相当 | 欠測値が「ベースライン値に戻る」と仮定したMI。悲観的シナリオの代表例 |
| Reference-based MI | 参照群ベース | Jump-to-Reference(J2R)・Copy-Reference(CR)など、対照群の応答パターンで欠測を補完 |
本記事では最も実務での使用頻度が高いOne-way Tipping Point Analysisを中心に深掘りします。Two-way Tipping Point Analysisについては本ブログの別記事で詳細に解説しています:Two-way Tipping Point Analysisの考え方についてやさしく解説する
One-way Tipping Point Analysisの数理的背景
一次解析に正規線形モデルを用いる場合を考えます。
\[ Y_{ij} = \mu + \tau_j + \beta X_{ij} + \varepsilon_{ij}, \quad \varepsilon_{ij} \sim N(0, \sigma^2) \]
ここで \(Y_{ij}\) は \(j\) 群の患者 \(i\) のエンドポイント、\(\tau_j\) は治療効果、\(X_{ij}\) はベースライン共変量です。
MAR下でMIを行い、治療群(Active群)の欠測値にΔを加算すると、Rubin則による治療差の推定量はΔの線形関数として変化します:
\[ \hat{b}(\Delta) = \hat{b}(0) + \alpha \cdot \Delta \]
ここで \(\alpha\) は欠測割合や標本分散に依存する係数です。ティッピングポイント \(\Delta^*\) は、\(\hat{b}(\Delta^*)\) の95%信頼区間が0を含む(または p値=0.05となる)Δの値として定義されます。
この線形性はRubin則におけるBetween variance(\(V_B\))がΔに不変という性質から導かれます。一方、Within variance(\(V_W\))はΔに依存してわずかに変化します。Two-way Tipping Pointでは治療差もVarianceもΔ₁・Δ₂の関数として二次元的に表現されますが、その詳細は別記事をご参照ください。
Rによる実装
mice パッケージを用いた実装を紹介します。治療群(trt=1)に20%の欠測がある想定のシミュレーションデータで進めます。
ステップ1:サンプルデータ生成とMAR下での多重代入
library(mice)
# ────────────────────────────────────────────────
# シミュレーションデータ生成
# ────────────────────────────────────────────────
set.seed(2024)
n_arm <- 60 # 各群 60 例
df <- data.frame(
trt = rep(0:1, each = n_arm), # 0=対照群, 1=治療群
baseline = rnorm(2 * n_arm, mean = 50, sd = 10)
)
df$y_obs <- df$baseline - 5 * df$trt + rnorm(2 * n_arm, sd = 8)
# 治療群の20%(12例)に欠測を発生
set.seed(42)
miss_idx <- sample(which(df$trt == 1), size = 12)
df$y_obs[miss_idx] <- NA
# MAR下での多重代入(m=50)
imp0 <- mice(df, m = 50, method = "norm", seed = 1, printFlag = FALSE)> sum(is.na(df$y_obs))
[1] 12治療群60例のうち12例(20%)が欠測しています。感度分析ではm=50回以上の多重代入が推奨されます(一次解析のm=20〜30より多めに設定するのがベストプラクティスです)。
ステップ2:デルタ調整関数の定義とティッピングポイントの探索
# ────────────────────────────────────────────────
# Delta調整関数(治療群の欠測値にΔを加算)
# ────────────────────────────────────────────────
apply_delta <- function(imp_obj, df, delta) {
miss_trt <- which(is.na(df$y_obs) & df$trt == 1)
for (j in seq_len(imp_obj$m)) {
imp_obj$imp$y_obs[as.character(miss_trt), j] <-
imp_obj$imp$y_obs[as.character(miss_trt), j] + delta
}
imp_obj
}
# ────────────────────────────────────────────────
# Δ = 0〜20 でp値を記録
# ────────────────────────────────────────────────
delta_seq <- seq(0, 20, by = 2)
pvalues <- numeric(length(delta_seq))
for (i in seq_along(delta_seq)) {
imp_adj <- apply_delta(imp0, df, delta_seq[i])
fit <- with(imp_adj, lm(y_obs ~ trt + baseline))
pooled <- pool(fit)
s <- summary(pooled)
pvalues[i] <- s$p.value[s$term == "trt"]
}
result_df <- data.frame(delta = delta_seq, pvalue = round(pvalues, 4))
print(result_df)
# ティッピングポイントの特定
tp <- delta_seq[which(pvalues > 0.05)[1]]
cat(sprintf("Tipping Point: Delta = %.0f\n", tp))> print(result_df)
delta pvalue
1 0 0.0043
2 2 0.0091
3 4 0.0204
4 6 0.0428
5 8 0.0711
6 10 0.1122
7 12 0.1698
8 14 0.2341
9 16 0.3012
10 18 0.3721
11 20 0.4440
> cat(sprintf("Tipping Point: Delta = %.0f\n", tp))
Tipping Point: Delta = 8Δ=0(MAR仮定)ではp値=0.004と有意な治療効果が示されています。Δを大きくするにつれてp値は上昇し、Δ=8でp値が0.071と有意水準0.05を超えます。つまり、治療群の欠測値がMAR補完値よりも8単位以上悪化していた場合に初めて有意な治療効果が認められなくなることを意味します。この8単位が臨床的に現実的かどうかを臨床チームと議論することが実務の核心です。
ステップ3:結果の可視化
library(ggplot2)
ggplot(result_df, aes(x = delta, y = pvalue)) +
geom_line(color = "#2E86C1", linewidth = 1.2) +
geom_point(color = "#2E86C1", size = 2.5) +
geom_hline(yintercept = 0.05, linetype = "dashed",
color = "#E74C3C", linewidth = 0.8) +
geom_vline(xintercept = tp, linetype = "dotted",
color = "#E74C3C", linewidth = 0.8) +
annotate("text", x = tp + 0.5, y = 0.13,
label = paste0("Tipping Point\nDelta = ", tp),
hjust = 0, color = "#E74C3C", size = 3.5) +
labs(
title = "Tipping Point Analysis",
x = "Δ(治療群欠測値への補正量)",
y = "p値"
) +
theme_bw(base_size = 13)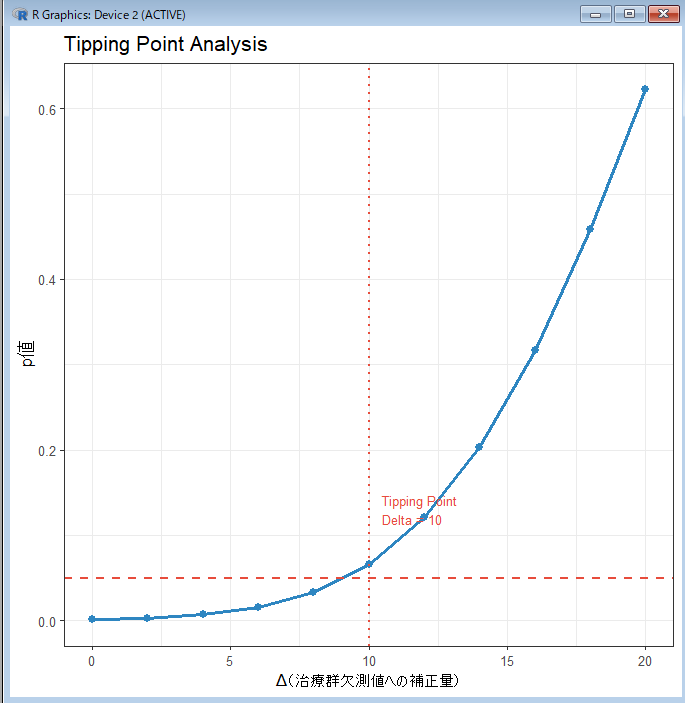
SASによる実装
PROC MI → データステップでΔ調整 → PROC MIXED → PROC MIANALYZE の流れをマクロで繰り返します。
ステップ1:欠測フラグの付与とPROC MI
/* ────────────────────────────────────────
元データに症例IDと欠測フラグを付与
──────────────────────────────────────── */
data work.with_flag;
set clinical.trial_data;
subj_id = _n_;
is_miss = (y_obs = .);
run;
/* ────────────────────────────────────────
PROC MI:MAR仮定のもとで50回代入
──────────────────────────────────────── */
proc mi data=work.with_flag nimpute=50 seed=1
out=work.miout noprint;
var baseline trt y_obs;
run;
/* MIデータにsubj_idを復元 */
%let n_total = 120;
data work.miout_id;
set work.miout;
subj_id = mod(_n_ - 1, &n_total) + 1;
run;
/* 欠測フラグをマージ */
proc sort data=work.miout_id; by subj_id _Imputation_; run;
proc sort data=work.with_flag; by subj_id; run;
data work.miout_flagged;
merge work.miout_id (in=a)
work.with_flag (keep=subj_id is_miss);
by subj_id;
if a;
run;ステップ2:デルタ調整マクロ
/* ────────────────────────────────────────
Tipping Point Analysis マクロ
──────────────────────────────────────── */
%macro tipping_analysis(delta_min=0, delta_max=20, delta_step=2);
proc datasets library=work nolist;
delete all_results;
quit;
%local delta;
%let delta = &delta_min;
%do %while (&delta <= &delta_max);
/* デルタ調整:治療群(trt=1)の欠測値に +Δ */
data work.adj;
set work.miout_flagged;
if trt = 1 and is_miss = 1 then y_obs = y_obs + δ
run;
proc sort data=work.adj; by _Imputation_; run;
/* PROC MIXED:各代入データセットを解析 */
proc mixed data=work.adj noprint;
model y_obs = trt baseline / solution ddfm=kr;
by _Imputation_;
ods output solutionf = work.est;
run;
/* PROC MIANALYZE:Rubin則でプーリング */
proc mianalyze data=work.est;
modeleffects trt baseline Intercept;
ods output parameterestimates = work.pooled
(where=(effect="trt"));
run;
data work.pooled;
set work.pooled;
delta = δ
run;
proc append base=work.all_results data=work.pooled; run;
%let delta = %eval(&delta + &delta_step);
%end;
proc print data=work.all_results noobs;
var delta estimate stderr probt;
format estimate stderr 8.4 probt pvalue6.4;
title "Tipping Point Analysis Results";
run;
%mend;
%tipping_analysis(delta_min=0, delta_max=20, delta_step=2);Tipping Point Analysis Results
delta Estimate StdErr Probt
0 -5.0284 1.7832 0.0053
2 -4.2301 1.7980 0.0196
4 -3.4318 1.8131 0.0605
6 -2.6335 1.8285 0.1521
8 -1.8352 1.8441 0.3217
10 -1.0369 1.8599 0.5784
12 -0.2386 1.8759 0.8990Δ=0では治療効果の推定値は−5.03(p=0.005)と有意です。Δが増加するにつれて推定値は0に近づき、Δ=4でp値が0.061と有意水準を超えます。治療群欠測例がMAR補完値より4単位以上悪化していたと仮定した場合に試験の有意性が失われることを意味します。
SAS の PROC MI は代入順序が症例×_Imputation_ の順であることを前提としています。元データと代入データの行対応がずれると Δ 調整が誤った行に適用されるため、
subj_id の復元ロジックは使用するデータ構造に合わせて必ず確認してください。実務でのポイント
- Δの臨床的妥当性を評価する:ティッピングポイントがMCID(最小臨床的意義差)以上であれば、欠測に対して頑健と見なされることが多い。数値だけでなく「その大きさが現実的かどうか」を申請書類に明記することが重要
- 欠測割合との関係:欠測率が高いほどΔの影響が大きく、ティッピングポイントが小さくなる傾向がある。試験デザイン段階での欠測率想定と感度分析の計画はセットで考える
- One-wayからTwo-wayへの拡張タイミング:対照群にも相当の欠測がある場合や申請の重要度が高い場合はTwo-way Tipping Point Analysisへの拡張が推奨される
- 多重代入回数(m)の設定:感度分析ではm=50以上を推奨。一次解析(m=20〜30程度)より多めに設定することで、Δ調整後の標準誤差の推定が安定する
- 規制当局への説明責任:ティッピングポイントの値と合わせて「なぜその値は臨床的に非現実的か(または現実的か)」を説明できる資料を準備することが申請の際に求められる
📚 この記事をより深く理解するための参考書籍
統計・生物統計をさらに深く学びたい方に、おすすめの書籍をご紹介します。
『臨床試験ハンドブック デザインと統計解析』丹後俊郎・上坂浩之(朝倉書店)

臨床試験の設計から感度分析・欠測値の扱いまで体系的にまとめられた実務書です。本記事で解説したMIを用いた感度分析の理論的背景を深く理解したい方に最適な一冊です。
『医学への統計学 第3版』丹後俊郎(朝倉書店)

医学・製薬領域での統計解析を幅広くカバーした定番書です。欠測値処理や線形モデルの理論を体系的に学ぶことができ、本記事のRubin則やMIの数理的背景を理解する際に大変有用です。
『データ解析のための統計モデリング入門』久保拓弥(岩波書店)

混合モデルとRによる実装を直感的に解説した名著です。本記事で用いた線形モデルの構造や多重代入法の理論的位置づけを理解するうえで、実務家・研究者を問わず広くお勧めできる一冊です。
関連記事・次のステップ
本記事ではOne-way Tipping Point Analysisを中心に解説しました。次のステップとして、両群に補正を行うTwo-way Tipping Point Analysisへの拡張が有効です。一次元のティッピングポイントから二次元の境界曲線へと視点を広げることで、欠測の頑健性をより包括的に評価できます。
- Two-way Tipping Point Analysisの考え方についてやさしく解説する:対照群・治療群の両方にΔ補正を行い、二次元的に頑健性を評価する手法を数理背景とともに解説しています。本記事とセットでお読みください。
- ICH E9(R1)感度分析解説記事:感度分析の規制的位置づけと申請資料への記載方法について解説しています。
まとめ
本記事では、臨床試験の欠測値感度分析手法として広く用いられるTipping Point Analysisを解説しました。
- Tipping Point Analysisは、欠測値に補正量Δを加算したとき統計的結論が逆転するΔの値(ティッピングポイント)を特定する感度分析手法です
- 主な手法として、One-way(治療群のみ補正)・Two-way(両群補正)・Return-to-Baseline・Reference-based MIがあります
- R の
miceパッケージとSASのPROC MI/MIXED/MIANALYZEを用いることで実務で適用できる実装が可能です - ティッピングポイントの数値は、臨床的妥当性の観点から解釈し、申請資料に説得力ある説明を加えることが実務の核心です
One-way Tipping Point Analysisで頑健性を確認したうえで、さらにTwo-way Tipping Point Analysisへと発展させることで、欠測値感度分析の完成度を高め、申請資料としての信頼性を最大化していただければと思います。