統計検定準1級「多変量解析」攻略 ― PCA・MDS・正準相関の出題対策

・統計検定準1級「多変量解析」の中で PCA・MDS・正準相関 がどう出題されるかの全体像
・各手法の数理的背景(固有値分解・距離行列・正準相関係数)と直感的な意味
・公式ワークブックで頻出するパターン(寄与率計算・ストレス値・Wilks’ Lambda など)と解き筋
・Rの組み込みデータセットを使った最小限のコードと、出力の読み取り方
・3手法の使い分けと、製薬・臨床研究の実務でのポイント
はじめに
統計検定準1級の「多変量解析」分野は、1〜2問の必出領域でありながら、回帰分析やベイズ統計と比べると学習が後回しになりがちな単元です。とりわけ 主成分分析(PCA)・多次元尺度構成法(MDS)・正準相関分析(CCA) の3手法は、出題頻度のわりに教材が散らばっていて、はじめて学ぶ受験者にとって整理が難しい部分です。
本記事は「準1級分野別シリーズ」として、この3手法を1本にまとめて攻略するためのガイドです。各手法の数理的な核(固有値分解)に着目すると、見え方ががらりと変わります。受験対策に必要な最小限の式、Rによる確認、そして製薬・臨床研究での実務的な使い分けまでを、製薬関係者・社会人・大学生にもわかる形で解説します。
多変量解析の位置づけと出題の見取り図
準1級の出題範囲表では、多変量解析は「データの分析・統計的推測」の中の独立した大項目として位置づけられています。出題形式はおおむね 公式ワークブックの章末問題に近い計算系1問 + 解釈系の選択肢1問 という構成が多く、固有値・固有ベクトル・相関構造の理解が問われます。
| 手法 | 入力 | 目的 | 核となる計算 |
|---|---|---|---|
| PCA(主成分分析) | 変数 × サンプル行列 | 分散最大の方向を取り次元圧縮 | 分散共分散行列の固有値分解 |
| MDS(多次元尺度構成法) | 距離行列・非類似度行列 | 距離を保ったまま低次元配置 | 二重中心化後のスペクトル分解 |
| CCA(正準相関分析) | 2組の変数群 | 群間の線形相関を最大化 | 交差共分散行列由来の固有値分解 |
いずれも 「行列の固有値分解」が共通の数理基盤 になっており、入力と最大化したい量が違うだけ、という見方ができます。この共通項を頭に入れたうえで個別の手法を学ぶと、出題の正体がクリアに見えてきます。
主成分分析(PCA)の出題ポイント
PCAの目的と直感的イメージ
主成分分析(Principal Component Analysis, PCA)は、多変量データが持つ情報をできるだけ失わずに、少数の合成変数(主成分)に圧縮する手法です。直感的には「データの散らばり(分散)が最大となる方向」を新しい軸(第1主成分)として取り、それと直交する次に分散が大きい方向を第2主成分とする、という操作を繰り返します。元の \(p\) 変数が互いに相関していても、主成分同士は無相関になるよう構成されるため、情報の重複を取り除いた要約が得られます。
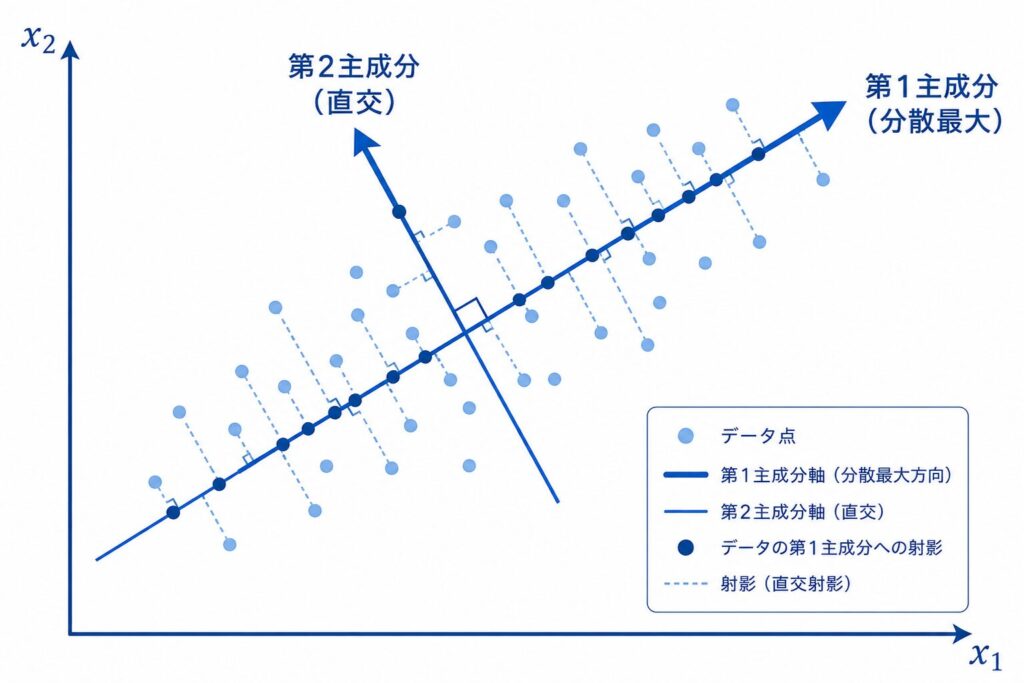
PCAは「分散を最大化する直交変換」です。次元圧縮・可視化・多重共線性の回避など、用途は多岐にわたります。準1級では「分散最大化」というキーワードを軸に出題されることが多いので、必ず押さえましょう。
数理的背景:固有値・固有ベクトル分解
\(n\) 個体・\(p\) 変数のデータ行列を \(X\) とし、その分散共分散行列を \(\Sigma\)(標本では \(S\))とします。第 \(k\) 主成分は、係数ベクトル \(\boldsymbol{a}_k\) を用いて
\[
z_k = \boldsymbol{a}_k^\top \boldsymbol{x}, \quad \|\boldsymbol{a}_k\|=1
\]
と表され、\(\mathrm{Var}(z_k) = \boldsymbol{a}_k^\top \Sigma \boldsymbol{a}_k\) を最大化することで求められます。ラグランジュ未定乗数法から、これは固有値問題
\[
\Sigma \boldsymbol{a}_k = \lambda_k \boldsymbol{a}_k
\]
に帰着します。すなわち 第 \(k\) 主成分の係数ベクトルは \(\Sigma\) の第 \(k\) 固有ベクトル、そしてその 分散は対応する固有値 \(\lambda_k\) に等しい ということです(\(\lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_p \geq 0\))。
寄与率と累積寄与率
固有値の和 \(\sum_{k=1}^{p} \lambda_k\) は元データの全分散(\(\Sigma\) の対角和 \(\mathrm{tr}(\Sigma)\))に等しくなります。よって第 \(k\) 主成分の 寄与率 と、上位 \(m\) 個までの 累積寄与率 は次式で定義されます。
\[
c_k = \frac{\lambda_k}{\sum_{j=1}^{p} \lambda_j}, \qquad C_m = \frac{\sum_{k=1}^{m} \lambda_k}{\sum_{j=1}^{p} \lambda_j}
\]
準1級では「固有値が与えられたとき寄与率と累積寄与率を計算せよ」という問題が頻出です。固有値の総和=変数の総分散(標準化済みなら変数の数 \(p\))であることを忘れないようにしましょう。
標準化の有無:分散共分散行列か相関行列か
変数の単位やスケールが大きく異なる場合(例:身長cmと体重kgと年収万円)、分散が大きい変数だけが第1主成分を支配してしまいます。これを避けるため、各変数を平均0・分散1に 標準化 してから分析する(=相関行列 \(R\) を分解する)のが一般的です。
| 分析対象行列 | 使う場面 | 固有値の総和 |
|---|---|---|
| 分散共分散行列 \(S\) | 変数の単位が揃い、分散の差そのものに意味があるとき | \(\mathrm{tr}(S)\) |
| 相関行列 \(R\) | 変数の単位やスケールが異なるとき(通常はこちら) | \(p\)(変数の数) |
主成分得点・主成分負荷量・バイプロット
- 主成分得点:個体 \(i\) を主成分軸へ射影した値 \(z_{ik} = \boldsymbol{a}_k^\top \boldsymbol{x}_i\)。個体の散布図描画に用います。
- 主成分負荷量:主成分と元変数の相関係数 \(r(z_k, x_j) = a_{jk}\sqrt{\lambda_k}/s_j\)。各主成分が何を意味するかの解釈に使います。
- バイプロット:主成分得点と負荷量を同一平面に重ねた図。個体の布置と変数の寄与方向を同時に読み取れます。
Rコード例:USArrestsで主成分分析
USArrests はアメリカ50州の犯罪統計データで、変数のスケール(殺人率と都市人口割合)が大きく異なるため、PCAの標準化の重要性を体感できる教材として頻用されます。
# 相関行列ベース(scale.=TRUE で標準化)
pca <- prcomp(USArrests, scale. = TRUE)
summary(pca)
pca$rotation # 主成分負荷ベクトル(固有ベクトル)
biplot(pca, scale = 0)
出力結果(要約)は次のようになります。
> summary(pca)
Importance of components:
PC1 PC2 PC3 PC4
Standard deviation 1.5749 0.9949 0.59713 0.41645
Proportion of Variance 0.6201 0.2474 0.08914 0.04336
Cumulative Proportion 0.6201 0.8675 0.95664 1.00000
> pca$rotation
PC1 PC2 PC3 PC4
Murder -0.5358 -0.4182 -0.3412 0.6492
Assault -0.5832 -0.1880 -0.2681 -0.7434
UrbanPop -0.2782 0.8728 -0.3780 0.1339
Rape -0.5434 0.1673 0.8178 0.0890
第1主成分は4変数すべての負荷量が同符号(負)で、絶対値も同程度です。これは「全体的な犯罪水準の高さ」を表す総合指標と解釈できます。第2主成分は UrbanPop だけ符号が逆で大きいので、「都市化の度合いと犯罪との対比」を表す軸と読み取れます。累積寄与率は第2主成分までで約86.8%に達し、2次元への圧縮で十分情報を保持できていることが分かります。カイザー基準(\(\lambda \geq 1\))で見ても、標準偏差1.57の第1主成分のみ採用となります(標準偏差の二乗が固有値)。
準1級では「
summary() の Proportion of Variance と Cumulative Proportion を読み取らせる問題」「rotation 行列の符号から主成分の意味を解釈させる問題」がよく出ます。出力の各行が何を意味するか、紙の上でも即答できるように練習しておきましょう。多次元尺度構成法(MDS)の出題ポイント
MDSとは:距離を保ったまま低次元へ配置する
多次元尺度構成法(Multidimensional Scaling, MDS)は、オブジェクト間の 距離(または非類似度) をできるだけ保ったまま、各オブジェクトを2次元や3次元の空間に配置する手法です。PCAが「変数×サンプルのデータ行列」を入力にするのに対し、MDSは オブジェクト間の距離行列(n×n) を入力にする点が決定的に異なります。アンケートでの「商品間の似ている度合い」や、地図上の「都市間の道のり」など、もとの座標が分からなくても距離さえ与えられれば配置を復元できるのがMDSの強みです。
PCAは「データ行列 → 分散最大の軸」を探す手法、MDSは「距離行列 → 距離を保つ配置」を探す手法です。入力の形が違うことを必ず押さえましょう。
古典的MDS(計量MDS)の手順
古典的MDS(Classical MDS, Torgersonの方法)は、距離行列から座標を直接復元する代数的な手法です。距離行列を \(D=(d_{ij})\) とすると、まず各要素を2乗した行列 \(D^{(2)}\) に対して 二重中心化(double centering) を適用し、内積行列 \(B\) を構成します。
\[
B = -\frac{1}{2} J D^{(2)} J, \quad J = I_n – \frac{1}{n}\mathbf{1}\mathbf{1}^\top
\]
ここで \(J\) は中心化行列です。続いて \(B\) を スペクトル分解 し、固有値 \(\lambda_1 \geq \lambda_2 \geq \cdots\) と固有ベクトル \(v_1, v_2, \ldots\) を得て、上位 \(k\) 個から座標 \(X = V_k \Lambda_k^{1/2}\) を構成します。これが2次元配置(\(k=2\))の正解です。
準1級では「距離行列が与えられて二重中心化後の \(B\) の固有値・固有ベクトルから2次元座標を求めよ」という穴埋め計算が頻出です。\(\sqrt{\lambda_i}\) を掛ける手順を忘れないようにしましょう。
ストレスと非計量MDS(Kruskal法)
距離が厳密な数値でなく 順位情報 しかない場合(例:「AとBの方がAとCより似ている」など順序のみ)、非計量MDS(Kruskal法)を使います。非計量MDSは、配置から計算される距離 \(\hat d_{ij}\) と、もとの非類似度 \(\delta_{ij}\) の単調回帰によるあてはめ値 \(\tilde d_{ij}\) のずれを ストレス(Stress) として定義し、これを最小化します。
\[
\text{Stress} = \sqrt{\frac{\sum_{i<j}(\hat d_{ij} – \tilde d_{ij})^2}{\sum_{i<j}\hat d_{ij}^{\,2}}}
\]
ストレス値の解釈基準(Kruskalの目安)は以下の通りです。
| ストレス値 | あてはまりの評価 |
|---|---|
| 0.025以下 | perfect(完璧) |
| 0.05以下 | excellent(非常に良い) |
| 0.10程度 | good(良い) |
| 0.20程度 | fair(やや不十分) |
| 0.20以上 | poor(不十分) |
PCAとMDSの関係
入力がユークリッド距離である場合、古典的MDSはPCAと数学的に等価 になります。具体的には、平均中心化したデータ行列 \(X_c\) に対するPCAの主成分得点と、ユークリッド距離行列に古典的MDSをかけて得られる座標は(符号・回転の自由度を除いて)一致します。両者は「同じ部分空間を、データ側から見るか距離側から見るか」の違いに過ぎません。
計量MDS=距離行列ベース/非計量MDS=順位情報ベース。さらに「ユークリッド距離なら計量MDS=PCA」という3点セットは準1級の鉄板論点です。
Rで再現:eurodistによる欧州都市配置
Rの組み込みデータセット eurodist は、欧州21都市間の道のり(km)を距離行列として収めたものです。cmdscale() 関数で古典的MDSを適用すると、地理的な位置関係がほぼ復元されます。
# 古典的MDSによる欧州都市の2次元配置
data(eurodist)
mds <- cmdscale(eurodist, k = 2, eig = TRUE)
# 座標と固有値を確認
head(mds$points)
mds$eig[1:5]
# 配置のプロット(南北を地図方向に合わせるためy軸を反転)
plot(mds$points[,1], -mds$points[,2], type = "n",
xlab = "第1次元", ylab = "第2次元",
main = "MDSによる欧州都市の配置")
text(mds$points[,1], -mds$points[,2],
labels = rownames(mds$points), cex = 0.8, col = "#2E86C1")
> head(mds$points)
[,1] [,2]
Athens 2290.275 1798.803
Barcelona -825.383 546.811
Brussels 59.183 -367.081
Calais -82.845 -429.915
Cherbourg -352.499 -290.908
Cologne 293.689 -405.312
> mds$eig[1:5]
[1] 19538377 11856555 1693767 1019175 668518
第1次元の固有値が約1.95×10⁷、第2次元が約1.19×10⁷と上位2つが圧倒的に大きく、2次元で十分に距離構造を表現できることがわかります。プロットではアテネが東端、リスボン・マドリードが西端、ストックホルムが北端に並び、ヨーロッパの地図がそのまま再現されます。なお
cmdscaleの出力は符号反転や回転の自由度があるため、y軸の向きを反転して見慣れた地図に合わせるのが定番のテクニックです。正準相関分析(CCA)の出題ポイント
正準相関分析(Canonical Correlation Analysis, CCA)は、2組の変数群の間にどの程度の線形的な関連があるかを評価するための多変量解析手法です。PCAが1組の変数群内の分散構造を要約するのに対し、CCAは2つの変数群を橋渡しする「相関の最大化」を目的とする点が大きな違いです。準1級では、CCAの数理的構造・PCAや重回帰との関係・有意性検定・Rでの実行と解釈までが幅広く問われます。
CCAの目的と基本構造
X群 \(X = (X_1, \dots, X_p)^\top\)、Y群 \(Y = (Y_1, \dots, Y_q)^\top\) の2組の変数群があるとき、それぞれの線形結合
\[
U = a^\top X, \quad V = b^\top Y
\]
を考え、両者の相関 \(\mathrm{Cor}(U, V)\) を最大化する係数ベクトル \(a, b\) を求める手法がCCAです。このとき得られる \(U, V\) を正準変量、その相関係数 \(\rho_1\) を第1正準相関係数と呼びます。
第2以降の正準変量は、それまでに得られた正準変量と直交する(無相関である)という条件のもとで、相関を順次最大化していく形で求められます。得られる正準相関の本数は \(\min(p, q)\) 個で、
\[
1 \ge \rho_1 \ge \rho_2 \ge \dots \ge \rho_{\min(p,q)} \ge 0
\]
の順に並びます。
正準相関と固有値問題
X群とY群の分散共分散行列を \(\Sigma_{XX}, \Sigma_{YY}\)、X群とY群の交差共分散行列を \(\Sigma_{XY} = \Sigma_{YX}^\top\) とすると、正準相関係数の二乗 \(\rho_k^2\) は次の行列の固有値として与えられます。
\[
\Sigma_{XX}^{-1}\Sigma_{XY}\Sigma_{YY}^{-1}\Sigma_{YX}
\]
このため、CCAは「2つの変数群を結ぶ最も強い線形軸を、固有値分解で順番に取り出す」操作と理解できます。
第1正準相関 \(\rho_1\) は、X群とY群を1次元ずつに射影したときに得られる相関係数の理論的上限を意味します。「X群を使ってY群をどこまで説明できるか」の基準線として頻出です。
PCA・重回帰との関係
CCAは多変量解析の中で非常に汎用性の高い枠組みで、特殊ケースとしてPCAや重回帰を包含します。
| 手法 | X群 | Y群 | 最大化する量 |
|---|---|---|---|
| PCA | 1組の変数群 | ― | 群内分散 |
| 重回帰 | 複数の説明変数 | 単一の目的変数 | 説明変数との相関(\(R\)) |
| CCA | 複数の変数群 | 複数の変数群 | 群間の正準相関 \(\rho\) |
Y群の変数が1つだけの場合、第1正準相関 \(\rho_1\) は重回帰における重相関係数 \(R\) と一致します。この対応関係はそのまま選択肢問題のひっかけとして出題されやすい部分です。
正準相関の有意性検定
「第何正準相関まで採用すべきか」を判断するために、有意性検定が用いられます。代表的なのはWilks’ Lambdaを用いた検定で、第 \(k\) 番目以降のすべての正準相関がゼロであるという帰無仮説を、
\[
\Lambda_k = \prod_{i=k}^{\min(p,q)} (1 – \rho_i^2)
\]
で評価します。Bartlettの近似により、
\[
-\left(n – 1 – \frac{p+q+1}{2}\right) \log \Lambda_k
\]
がカイ二乗分布に近似的に従うことを利用して検定を行います。準1級では、Wilks’ Lambdaの式の形と「第1から順に検定し、有意でなくなったところで打ち切る」という採用ルールの両方が問われます。
正準負荷量と冗長性係数
各正準変量の解釈には、元の変数との相関である正準負荷量(canonical loading)を確認します。係数ベクトル \(a, b\) そのものは変数のスケールに依存するため、解釈には負荷量のほうが扱いやすいという特徴があります。
また、冗長性係数(redundancy coefficient)は「X群の正準変量がY群の分散をどれだけ説明しているか」を表す指標で、相関の強さだけでなく実質的な説明力を評価する際に用いられます。
正準相関係数 \(\rho_k\) が大きくても、冗長性係数が小さければ「相関は強いが、説明できている分散はわずか」という状況があり得ます。準1級ではこの違いを問う設問が頻出です。
Rコードによる実行例
iris データを用い、がく片に関する2変数(X群)と花弁に関する2変数(Y群)の正準相関を求めます。
X <- iris[, c("Sepal.Length", "Sepal.Width")]
Y <- iris[, c("Petal.Length", "Petal.Width")]
res <- cancor(X, Y)
res$cor # 正準相関係数
res$xcoef # X群の正準係数
res$ycoef # Y群の正準係数
# 正準変量と元変数の相関(正準負荷量)
U <- as.matrix(scale(X)) %*% res$xcoef
V <- as.matrix(scale(Y)) %*% res$ycoef
cor(scale(X), U)
cor(scale(Y), V)
出力例は以下のとおりです。
> res$cor
[1] 0.9409690 0.1239369
第1正準相関は約0.94と非常に高く、がく片の情報と花弁の情報のあいだに強い線形関係があることを示します。一方、第2正準相関は約0.12と小さく、Wilks’ Lambdaによる検定でも有意になりにくいため、実務上は第1正準相関のみを採用するのが妥当です。
3手法の使い分けと実務でのポイント
ここまで3つの手法を個別に整理してきましたが、試験対策と実務の両面で重要なのは「どの場面でどれを使うか」の判断です。共通基盤が固有値分解であることを踏まえると、選択のキーは「入力の形」と「最大化したい量」の2点に集約できます。
| 場面 | 推奨手法 | 理由 |
|---|---|---|
| 多数のバイオマーカーを少数の合成スコアに圧縮したい | PCA | 分散最大化で総合指標を作れる |
| 患者間の臨床的類似度のみが手元にある | MDS | 距離行列を入力にできる唯一の手法 |
| PK/PD指標群と安全性指標群の関係を見たい | CCA | 2つの変数群間の相関を直接定量化できる |
| アンケート評定の順位データから2次元布置を作りたい | 非計量MDS | 順位情報のみでもストレス最小化で配置可能 |
① 標準化を先に決める:単位が異なる変数を扱う場合、PCA・CCAでは相関行列ベース(標準化済み)が標準です。判断を後回しにすると結果が大きくぶれます。
② 採用本数の基準を事前に決める:寄与率・カイザー基準・Wilks’ Lambdaなど、どの基準で第何主成分・第何正準相関まで採用するかを、解析計画書に明記してから着手します。
③ 解釈の妥当性は専門家とすり合わせる:「第1主成分=重症度」など軸の意味づけは、統計だけでは決められません。臨床的妥当性をメディカルチームと議論して固めましょう。
④ サンプル数を確保する:CCAは特に \(n\) が小さいと相関がインフレを起こします。経験則として、変数の総数の少なくとも5〜10倍の \(n\) を確保するのが望ましいとされます。
📚 この記事をより深く理解するための参考書籍
統計検定準1級「多変量解析」の対策と、実務での応用までを踏まえて、特におすすめの3冊をランキング形式でご紹介します。






様々な媒体、経路を通じて大規模データが、驚くほど低コストで入手できるようになった現在、多変量解析手法に習熟したデータサイエンティストに対する学術界、ビジネス界からのニーズは非常に高まっており、これに対して大学や企業では、高いデータ解析力を持った人材の育成に注力し始めています。しかし、多くの多変量解析についての学習書は、理論的な説明に終始し、実務場面でどのように利用されているかについて、殆ど配慮がない野が現状です。
そこで本書は、多変量解析手法の理論と実践をバランスよく解説することで、統計が得意ではない大学生や実務者にも利用しやすい構成とし、本書1冊で多変量解析手法を実務に応用できるまで習得できる内容となっています。
関連記事・次のステップ
本記事は統計検定準1級分野別シリーズの「多変量解析」回でした。準1級の他分野や、多変量解析の応用にあたる以下の既存記事もあわせてお読みいただくと、理解が立体的になります。
- 生物統計家を目指すための勉強法 ― 基礎から実務スキルまでのロードマップ:統計検定準1級を含む学習ロードマップ。多変量解析がキャリアの中でどう活きるかが俯瞰できます。
- 区間推定入門:数式と図解で理解する信頼区間の世界:推測統計の基礎を固めたい方向け。準1級の確率分布・推定の分野と直結します。
- モデル選択の基礎:AIC・BICを”情報量”として理解する:主成分数や正準相関の本数を決める「採用基準」と発想が共通する話題です。
- p値を正しく理解する:統計学を勉強していく人のための基礎から応用まで:Wilks’ Lambdaの有意性検定を読み解くうえで前提となる、p値と検定の基礎を確認できます。
- 効果量(Effect Size)を理解すると統計が一気に実務的になる:正準相関係数や寄与率を「効果の大きさ」として読む発想に通じる入門記事です。
まとめ
本記事では、統計検定準1級「多変量解析」分野の中核となる PCA・MDS・正準相関分析(CCA) の3手法を、出題対策の観点から体系的に整理しました。3手法はいずれも 行列の固有値分解 を共通の数理基盤とし、「入力の形」と「最大化したい量」が異なるだけ、という統一的な見方ができます。
PCAでは寄与率・カイザー基準・主成分負荷量の解釈、MDSでは二重中心化と古典的MDS/非計量MDSの違い・ストレス値、CCAでは正準相関係数・Wilks’ Lambda・冗長性係数といった頻出論点を押さえることが、本番での得点に直結します。Rの prcomp・cmdscale・cancor を組み込みデータセットで動かしながら、出力をワークブックの解説と照らし合わせる練習が最も効率的です。
実務では、これらの手法はバイオマーカーの次元圧縮、患者の類似度に基づく層別化、PK/PD指標と安全性指標の関連性評価など、製薬・臨床研究のさまざまな場面で活躍します。準1級の合格は、多変量解析を実務で使いこなすための入り口 に過ぎません。試験対策で得た数理的な見立てを、ぜひ実データの分析にも応用していただければと思います。