統計検定準1級「ノンパラメトリック法」攻略 ― 符号検定・Wilcoxon・Kruskal-Wallis・順位相関の典型出題対策

・ノンパラメトリック法とは何か ― パラメトリック法との違いと「順位への変換」という共通の発想
・符号検定・Wilcoxon の符号順位検定・順位和検定(Mann-Whitney U)の使い分けと計算のポイント
・Kruskal-Wallis 検定と Jonckheere-Terpstra 検定(順序対立仮説・用量反応)の役割
・Spearman と Kendall の順位相関の違いと検定の考え方
・R での実装方法と、統計検定準1級の典型出題・製薬実務での使いどころ
はじめに
臨床試験や前臨床の試験データを扱っていると、「平均値の差を t 検定で」とすぐには進められない場面が数多くあります。検査値が右に裾を引いている、評価項目がそもそも順序尺度(Grade 1〜4 のような順序データ)である、外れ値が無視できない、症例数がごく少ない――こうしたときに頼りになるのがノンパラメトリック法です。
統計検定準1級では、ノンパラメトリック法は頻出分野のひとつで、毎回 1〜2 問程度が出題されます。符号検定や Wilcoxon の各検定、Kruskal-Wallis 検定、順位相関など、似た名前の手法が並び、混同しやすいのが受験者の悩みどころです。
本記事は「準1級分野別シリーズ」の一本として、これらの手法を一気に整理します。受験者の方はもちろん、製薬企業で解析を担当する方、統計を学ぶ社会人・大学生の方にも、典型出題と実務のつながりが見える内容を目指します。
ノンパラメトリック法とは ― パラメトリック法との違いと使いどころ
パラメトリック法は、データが従う確率分布の形(多くは正規分布)をあらかじめ仮定し、その分布を特徴づける母数(パラメータ)――平均 \( \mu \) や分散 \( \sigma^2 \) など――に関して推測を行う手法です。t 検定や分散分析がその代表で、母平均という「数値」に関心が向きます。
これに対してノンパラメトリック法は、分布の形を強くは仮定しません。その多くは、観測値そのものではなく、観測値を小さい順に並べたときの順位(ランク)に変換して扱うという共通のアイデアを持ちます。順位に置き換えてしまえば、もとの分布が正規でも歪んでいても扱いを揃えられるため、分布の仮定から自由になれるのです。
使いどころは次のような場面です。第一に、ヒストグラムや正規性の検定から正規性が疑わしいとき。第二に、データが順序尺度(順序データ)で、間隔に意味がなく平均を計算しても解釈しにくいとき。第三に、外れ値の影響を避けたいとき(順位は極端な値に鈍感です)。第四に、小標本で正規近似や中心極限定理に頼りにくいときです。
利点は、仮定が緩く頑健(ロバスト)で、外れ値や分布の歪みに振り回されにくいことです。一方で限界もあります。データが本当に正規分布に従う場面では、パラメトリック法より検出力がやや劣ります。また母数を直接推定しないため、「平均がどれだけ違うか」といった効果量の解釈がしにくい点にも注意が必要です。
パラメトリック検定とノンパラメトリック検定は、下図のように一対一に近い形で対応づけて整理できます。「対応のある t 検定の代わりに何を使うか」という発想で結びつけると、手法選択がぐっと見通しよくなります。
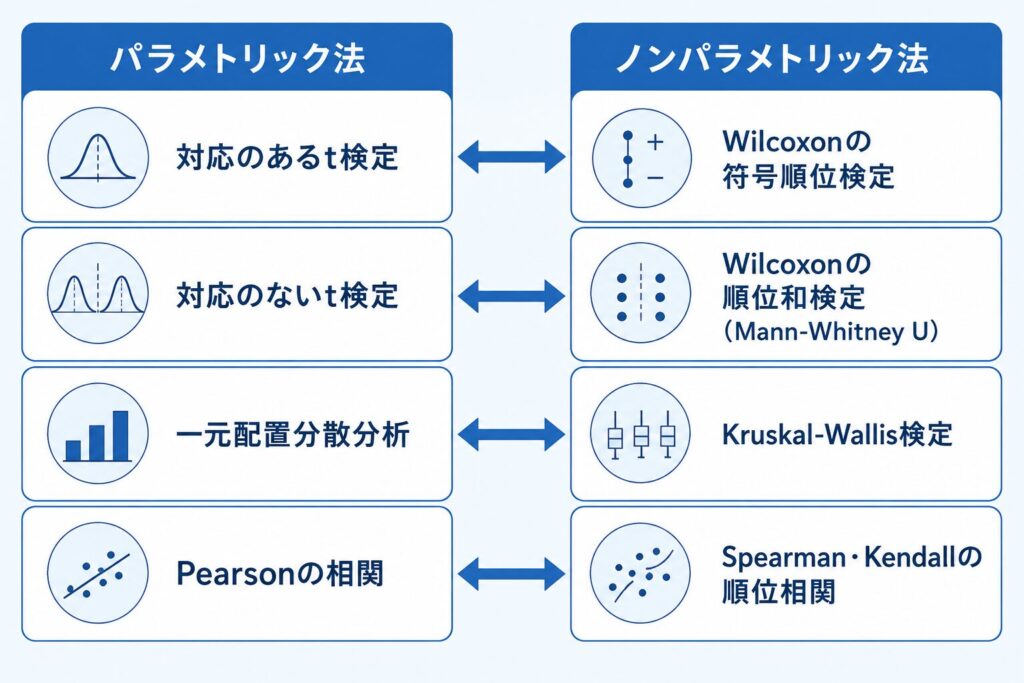
準1級での出題を俯瞰すると、次の見取り図のように整理できます。
| ノンパラメトリック検定 | データの型・場面 | 対応するパラメトリック検定 | 準1級での主な論点 |
|---|---|---|---|
| 符号検定・Wilcoxon の符号順位検定 | 対応のある2標本・1標本 | 対応のある t 検定 | 符号や符号付き順位の和の計算 |
| Wilcoxon の順位和検定(=Mann-Whitney U) | 独立2標本 | 対応のない t 検定 | 順位和と U 統計量・正規近似 |
| Kruskal-Wallis 検定 | 独立 k 標本 | 一元配置分散分析 | H 統計量とカイ二乗近似 |
| Jonckheere-Terpstra 検定 | 順序のある独立 k 標本 | ―(トレンド検定) | 用量反応など順序対立仮説 |
| Spearman・Kendall の順位相関 | 2変数の関連 | Pearson の相関係数 | 単調関係・順位相関係数の検定 |
多くのノンパラメトリック検定は「観測値を順位に置き換える」ことで分布の仮定を外しています。この共通の発想を軸に置くと、符号検定・Wilcoxon・Kruskal-Wallis・順位相関といった個別手法が、ばらばらの暗記項目ではなく一本の線でつながって見えてきます。
2標本の検定 ― 符号検定・Wilcoxonの符号順位検定・順位和検定(Mann-Whitney U)
2標本データの比較は、新薬群とプラセボ群の比較や、投与前後の検査値比較など、臨床試験の解析でもっとも頻繁に登場する場面です。データが正規分布から外れる場合や順序尺度のデータを扱う場合に、ノンパラメトリック法(母集団分布の形を仮定しない手法)が威力を発揮します。ここでは準1級頻出の3手法を順に整理します。
符号検定(Sign Test)
符号検定は、対応のある2標本(同じ被験者の投与前後など)、または1標本の中央値に関する検定です。各ペアの差を取り、その「符号(+/−)」だけを使います。差の大きさは一切使わず、差が 0 のペアは検定から除外します。
帰無仮説「正負が等確率で起こる(中央値が等しい)」のもとでは、+の個数 \( S \) は成功確率 \( 1/2 \) の二項分布に従います。
\[
P(S=k) = \binom{n}{k}\left(\frac{1}{2}\right)^{n}
\]
これは「差が 0 でないペアが \( n \) 個あるとき、そのうち \( k \) 個が+になる確率」を表します。両側 \( p \) 値はこの確率を裾側で足し合わせて求めます。符号だけを使うため計算は非常に簡便ですが、差の大きさという情報を捨てているぶん、検出力(本当に差があるときに差を見抜く力)は低くなります。
Wilcoxonの符号順位検定(Wilcoxon Signed-Rank Test)
Wilcoxonの符号順位検定も対応のある2標本/1標本に用いますが、差の絶対値 \( |d_i| \) に小さいほうから順位を付け、正の差に対応する順位の和 \( W^{+} \)(または負の順位和)を検定統計量にします。差の分布が中央値まわりで左右対称であることを仮定します。
帰無仮説のもとで、統計量の期待値と分散は次のようになります。
\[
E[W^{+}] = \frac{n(n+1)}{4}, \qquad \mathrm{Var}(W^{+}) = \frac{n(n+1)(2n+1)}{24}
\]
ここで \( n \) は差が 0 でないペアの数です。標本サイズが大きい場合は、これらを使った正規近似
\[
z = \frac{W^{+}-E[W^{+}]}{\sqrt{\mathrm{Var}(W^{+})}}
\]
によって \( p \) 値を求めます。符号検定が符号のみを使うのに対し、符号順位検定は「差の大きさの順位」まで利用するため、同じ場面では検出力が高くなるのが利点です。臨床試験で投与前後の検査値を比較する際の標準的なノンパラ手法です。
Wilcoxonの順位和検定(Mann-Whitney のU検定)
順位和検定は、独立した2標本(新薬群とプラセボ群など、別々の被験者からなる2群)の検定です。2群を合併して全 \( N=n_1+n_2 \) 個に小さいほうから順位を付け、群1に属する観測値の順位和 \( W_1 \) を求めます。U統計量は次で定義されます。
\[
U_1 = W_1 – \frac{n_1(n_1+1)}{2}, \qquad U_1 + U_2 = n_1 n_2
\]
前者は群1の順位和から「群1だけで占める最小順位和」を引いて、群1の値が群2の値を上回った回数に変換する式です。後者は2群のU統計量の和が常に \( n_1 n_2 \) になるという関係を表します。帰無仮説「2群の分布が等しい」のもとでは、
\[
E[W_1] = \frac{n_1(N+1)}{2}, \qquad \mathrm{Var}(W_1) = \frac{n_1 n_2 (N+1)}{12}
\]
となります。これは群1の順位和の期待値と分散で、大標本ではこれらを用いた正規近似で \( p \) 値を計算します(同順位=タイがある場合は分散に同順位補正を加えます)。この検定は位置のずれ、すなわち一方の分布が確率的に大きい(確率的優越)かどうかを検出します。なお、Wilcoxonの順位和検定とMann-Whitney のU検定は計算の出発点が違うだけで、本質的に同値な検定です。
| 検定 | 適用するデータ | 主な仮定 | 検定統計量 |
|---|---|---|---|
| 符号検定 | 対応あり2標本/1標本 | +/−が等確率(分布の対称性は不要) | +の個数 \( S \)(二項分布) |
| 符号順位検定 | 対応あり2標本/1標本 | 差の分布が対称 | 正の順位和 \( W^{+} \) |
| 順位和検定(Mann-Whitney U) | 独立した2標本 | 2群の分布形が同じ(位置のみ異なる) | 順位和 \( W_1 \)/U統計量 |
「符号順位検定(対応あり)」と「順位和検定(対応なし)」は名前が似ていますが、対応の有無で使い分けるまったく別の手法です。前者は同一被験者の投与前後など対になったデータに、後者は新薬群とプラセボ群のように独立した2群に用います。準1級では両者の取り違えを誘う設問が頻出するため、「符号順位=対応あり」「順位和=対応なし」とセットで覚えておきましょう。
同じ「対応あり」でも、符号検定は符号だけ、符号順位検定は差の大きさの順位まで使うため、検出力は符号検定 < 符号順位検定 となります。情報を多く使う検定ほど差を見抜きやすい、という関係を押さえておくと理解が定着します。
多群・順序・相関の検定 ― Kruskal-Wallis・Jonckheere-Terpstra・順位相関
3群以上の比較や、2変数の関連を順位ベースで評価する場面は、製薬・臨床研究で頻繁に登場します。ここでは多群比較・順序対立仮説・順位相関という3つのテーマを順に整理します。
Kruskal-Wallis検定
Kruskal-Wallis(クラスカル・ウォリス)検定は、独立した3群以上(k群)の代表値を比較するノンパラメトリック手法で、一元配置分散分析(ANOVA)のノンパラメトリック版にあたります。全データをいったん合併して順位を付け、各群の順位和 \( R_i \) を使うのが基本的な発想です。検定統計量は次式で与えられます。
\[
H = \frac{12}{N(N+1)} \sum_{i=1}^{k} \frac{R_i^{2}}{n_i} – 3(N+1)
\]
ここで \( N \) は全体の標本数、\( n_i \) は群 \( i \) の標本数、\( R_i \) は群 \( i \) の順位和を表します。帰無仮説(すべての群の分布が同じ)のもとで、\( H \) は近似的に自由度 \( k-1 \) のカイ二乗分布に従います。同じ値(同順位、タイ)が存在するときは、検定統計量に同順位補正を施します。
検定が有意になった場合、「どこかに差がある」ことはわかりますが、どの群間に差があるかまでは特定できません。具体的な群間差は、Dunn(ダン)検定などの多重比較で改めて調べます。
Jonckheere-Terpstra検定
Jonckheere-Terpstra(ヨンクヒール・タプストラ)検定は、群に「あらかじめ順序がある」場合に用いる検定です。たとえば用量0 < 低用量 < 中用量 < 高用量のように、群の並びに意味があるケースが典型例です。Kruskal-Wallisが「どこかに差がある」を見るのに対し、Jonckheereは「順序に沿って増加(または減少)する単調なトレンド」を検出する点が異なります。 具体的には、すべての群ペア \( (i,j),\ i<j \) についてMann-Whitney型のカウント \( U_{ij} \)(群 \( i \) の各値が群 \( j \) の各値より小さい組の数)を求め、その総和を統計量とします。 \[ J = \sum_{i<j} U_{ij} \] ここで \( J \) は、群の順序どおりに値が大きくなる傾向が強いほど大きな値をとります。順序情報を積極的に使うため、トレンドが実際に存在する場面では、順序を無視するKruskal-Wallisよりも検出力が高くなります。用量を増やすほど薬効指標が単調に変化するかを評価する製薬の用量反応試験(dose-response study)で特に有用です。
順位相関 ― SpearmanとKendall
2変数の単調な関連の強さを順位で測るのが順位相関です。まずSpearman(スピアマン)の順位相関係数 \( \rho \) は、各変数をそれぞれ順位に変換したうえでPearson相関を計算したものです。同順位がなければ、次の簡便式で求められます。
\[
\rho = 1 – \frac{6\sum_{i=1}^{n} d_i^{2}}{n(n^{2}-1)}
\]
ここで \( d_i \) は2変数の順位の差です。無相関(\( \rho = 0 \))の検定には、\( t = \rho\sqrt{(n-2)/(1-\rho^{2})} \) が近似的に自由度 \( n-2 \) の t 分布に従うことを利用します。
次にKendall(ケンドール)の順位相関係数 \( \tau \) は、すべての観測対を「2変数の順序が一致する組(concordant、一致)」と「一致しない組(discordant、不一致)」に分け、その差で関連を測ります。
\[
\tau = \frac{(\text{一致した組の数}) – (\text{一致しない組の数})}{n(n-1)/2}
\]
分母 \( n(n-1)/2 \) は作れる観測対の総数で、同順位があるときは補正版の \( \tau_b \) を用います。値が「順序が一致するペアの正味の割合」として直感的に解釈できるのが特徴です。
| 観点 | Spearman ρ | Kendall τ |
|---|---|---|
| 考え方 | 順位に変換してPearson相関を計算 | 一致ペアと不一致ペアの差で測る |
| 値の範囲 | −1 〜 +1 | −1 〜 +1 |
| 解釈 | 順位どうしの相関の強さ | 順序が一致するペアの正味の割合 |
| 外れ値・小標本での特徴 | τより値が大きく出やすい | 外れ値に頑健で小標本でも安定しやすい |
群に明確な順序(用量の大小など)があるのに、その順序を無視してKruskal-Wallis検定を使うと、せっかくの順序情報を捨てることになり検出力を損ないます。順序対立仮説(単調なトレンド)を見たい場面では、まずJonckheere-Terpstra検定の利用を検討してください。
Rで実装するノンパラメトリック検定
ここでは、Rに最初から付属している組み込みデータセットを使い、主要なノンパラメトリック検定(順位に基づく検定)を実際に実行してみます。実務でも同じ関数をそのまま使えるので、出力の読み方とあわせて確認していきましょう。
対応のある2標本:符号順位検定(sleep データ)
sleep は、同一の被験者が2種類の睡眠薬を服用したときの睡眠時間の増加量を記録した、対応のあるデータです。同じ人の中での差を見るので、paired = TRUE を指定します。
# sleep:同一被験者が2種類の睡眠薬で得た睡眠時間の増加量(対応あり)
wilcox.test(extra ~ group, data = sleep, paired = TRUE)
Wilcoxon signed rank test with continuity correction
data: extra by group
V = 0, p-value = 0.009091
alternative hypothesis: true location shift is not equal to 0
検定統計量 V=0、p=0.009091 と有意で、2種類の薬剤間で睡眠時間の増加に差があると判断できます。対応のあるデータなので、Wilcoxon の符号順位検定が使われています。今回は同順位(タイ、同じ値の差が複数あること)が含まれるため、正確検定ではなく連続性補正つきの正規近似による p 値になっています。臨床試験のクロスオーバー試験(同一患者に2処置を順番に行うデザイン)の解析でよく登場する形です。
独立2標本:順位和検定(Mann-Whitney U)(mtcars データ)
mtcars の am(トランスミッション。0=AT、1=MT)で群を分け、燃費 mpg を比較します。別々の車を比べる独立2群なので paired は指定しません(既定の FALSE)。
# mtcars:トランスミッション(am: 0=AT, 1=MT)別の燃費 mpg を比較(独立2群)
wilcox.test(mpg ~ am, data = mtcars)
Wilcoxon rank sum test with continuity correction
data: mpg by am
W = 42, p-value = 0.001871
alternative hypothesis: true location shift is not equal to 0
W=42、p=0.001871 と有意で、MT 車のほうが燃費が高い傾向が読み取れます。
paired を指定しない既定の状態では、wilcox.test は Wilcoxon の順位和検定(=Mann-Whitney U 検定)になります。出力の W は、Mann-Whitney の U 統計量に対応する値です。製薬では、実薬群とプラセボ群のように独立した2群を比べる場面に対応します。独立3群:Kruskal-Wallis検定(PlantGrowth データ)
PlantGrowth は、対照群 ctrl と処理群 trt1・trt2 の3群で植物の乾燥重量を比較したデータです。3群以上の比較には、一元配置分散分析のノンパラ版にあたる Kruskal-Wallis 検定を使います。
# PlantGrowth:対照群 ctrl と処理群 trt1, trt2 の3群で乾燥重量を比較
kruskal.test(weight ~ group, data = PlantGrowth)
Kruskal-Wallis rank sum test
data: weight by group
Kruskal-Wallis chi-squared = 7.9882, df = 2, p-value = 0.01842
H 統計量 7.9882、自由度 df=2、p=0.01842 と有意で、「3群のうちどこかに差がある」と言えます。ただし、この検定だけでは ctrl と trt2 など、どの群間に差があるのかまでは分かりません。具体的な群間差を知りたい場合は、Dunn 検定などの多重比較(ペアごとの比較を、検定の繰り返しによる誤りを調整しながら行う方法)を追加で実施します。
2変数の順位相関:SpearmanとKendall(mtcars データ)
最後に、燃費 mpg と馬力 hp の順位相関を、Spearman と Kendall の2つの方法で求めます。
# mpg(燃費)と hp(馬力)の順位相関
cor.test(mtcars$mpg, mtcars$hp, method = "spearman")
cor.test(mtcars$mpg, mtcars$hp, method = "kendall")
Spearman's rank correlation rho
data: mtcars$mpg and mtcars$hp
S = 10337, p-value = 1.488e-11
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
-0.8946646
Kendall's rank correlation tau
data: mtcars$mpg and mtcars$hp
z = -5.9119, p-value = 3.382e-09
alternative hypothesis: true tau is not equal to 0
sample estimates:
tau
-0.7428126
Spearman の \( \rho = -0.89 \)、Kendall の \( \tau = -0.74 \) で、どちらも強い負の単調関係(馬力が大きいほど燃費が悪い)を示しています。p 値はそれぞれ \( 1.5 \times 10^{-11} \)、\( 3.4 \times 10^{-9} \) と極めて小さく、有意です。同じデータでも \( |\tau| < |\rho| \) となりやすいですが、これは両指標の定義が異なるためで、値の大きさを直接比較するものではない点に注意してください。
試験対策と実務でのポイント
ここまで見てきた検定をどう使い分けるかは、準1級でも実務でも最初の関門です。次の図のように、データの構造(対応の有無・群数・2変数の関連か)を順にたどって選んでいくと迷いません。
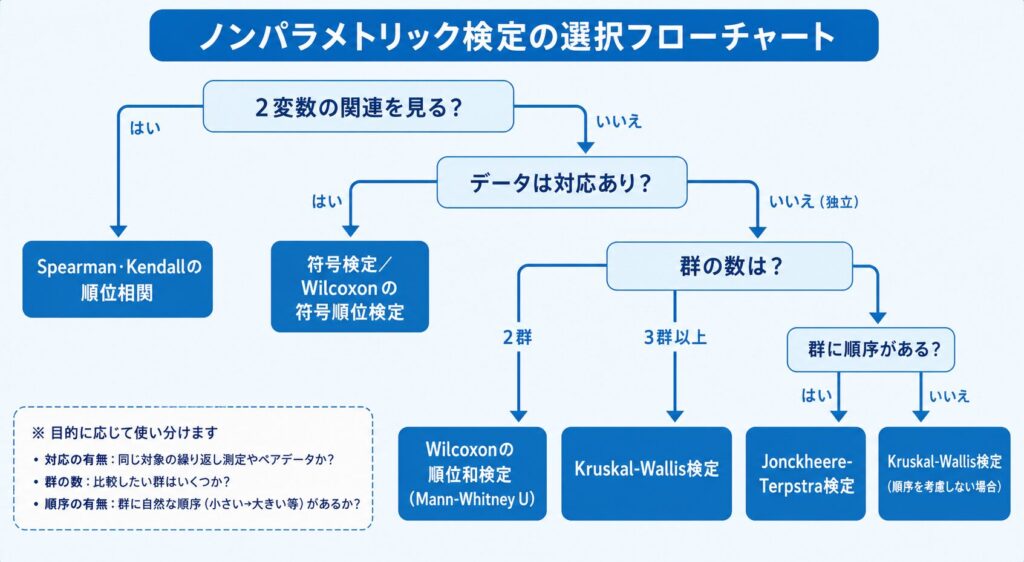
まず「対応があるか独立か」を判断し、対応ありなら符号検定や符号順位検定、独立2群なら順位和検定(Mann-Whitney U)、独立 k 群なら Kruskal-Wallis(群に順序があるなら Jonckheere-Terpstra)、2変数の関連を見たいなら Spearman・Kendall、という流れです。この分岐をたどれるようになることが、まず得点源になります。
準1級の典型出題パターン
準1級では、検定の意味を問う問題に加えて、統計量を手計算させる問題もよく出ます。代表的なものを整理しておきましょう。
| 出題テーマ | 問われ方 | 対策のコツ |
|---|---|---|
| 符号付き順位和 | 差の絶対値に順位を付け、符号別に和を計算させる | 「差を取る→絶対値で順位→符号を戻す」手順を体に染み込ませる |
| U統計量と順位和の関係 | 順位和 W から U を求めさせる、両者の換算 | \( U = W – n_1(n_1+1)/2 \) の関係式を確実に押さえる |
| Kruskal-Wallis の H 統計量 | H の計算と、カイ二乗近似の自由度を答えさせる | 自由度は「群数 − 1」。順位平均を使う計算式を覚える |
| Spearman の \( \rho \) | 順位差 d から \( \rho \) を計算させる | \( \rho = 1 – 6\sum d^2 / (n(n^2-1)) \) を暗記し、d の二乗和に注意 |
| 検定の使い分け | 場面を与え、適切な検定を選ばせる | 対応の有無・群数・順序の有無の3点で機械的に判断する |
① 測定尺度と研究デザイン(対応の有無・群数・順序の有無)を確認し、それに合った検定を選ぶ。
② 正規性が疑わしい小標本では、ノンパラメトリック法を第一候補にする。
③ 同順位(タイ)が多いと正規近似や効果量がぶれやすいので、補正や正確検定の利用を検討する。
④ 群に自然な順序がある場合は、Jonckheere-Terpstra 検定で検出力を確保する。
⑤ ノンパラは検出力がやや落ちるぶん、サンプルサイズ設計の段階で余裕を見ておく。
この記事をより深く理解するための参考書籍
統計検定準1級のノンパラメトリック法対策と、実務での応用までを見据えて、特におすすめの書籍を3冊ご紹介します。






関連記事・次のステップ
統計検定準1級「攻略」シリーズや、本記事と関連の深いノンパラメトリック手法の個別解説もあわせてご覧ください。
- 統計検定 準1級・1級 攻略ガイド ― 試験範囲・学習ステップ・よく出るテーマを完全整理 ―:試験全体の範囲と学習の進め方を俯瞰したい方はまずこちらから。
- 統計検定準1級「分散分析・実験計画法」攻略 ― 一元・二元配置から乱塊法・直交表・交互作用まで ―:Kruskal-Wallis 検定のパラメトリック版にあたる分散分析を整理したい方へ。
- Jonckheere の順位和検定を徹底解説:順序をもつ多群比較に最適なノンパラメトリック手法:本記事で触れた Jonckheere-Terpstra 検定をさらに深く学びたい方へ。
- Kolmogorov–Smirnov検定:平均の差だけでは見えない「分布の違い」をとらえる方法:分布の違いを検出するもう一つのノンパラメトリック検定です。
- スペアマンの順位相関係数を徹底解説― 非線形データや順位データに強い”もう一つの相関” ―:Spearman の順位相関を例題つきでより詳しく確認できます。
まとめ
本記事では、統計検定準1級で頻出のノンパラメトリック法を、符号検定・Wilcoxon の符号順位検定・順位和検定(Mann-Whitney U)・Kruskal-Wallis 検定・Jonckheere-Terpstra 検定・Spearman と Kendall の順位相関まで、出題対策の観点から体系的に整理しました。
これらの手法に共通するのは、「観測値を順位に変換することで分布の仮定を外す」という発想です。この一点を軸に置くと、対応の有無・群数・順序の有無・2変数の関連という観点で、個別の手法が一本の線でつながって見えてきます。符号付き順位和や U 統計量、H 統計量、Spearman の \( \rho \) の計算は、手順さえ身につければ確実に得点できる頻出論点です。Rの wilcox.test・kruskal.test・cor.test を組み込みデータで動かしながら、出力をワークブックの解説と照らし合わせる練習が最も効率的です。
実務では、正規性の崩れた検査値、Grade のような順序尺度、用量反応のトレンド評価など、ノンパラメトリック法が活躍する場面は製薬・臨床研究のいたるところにあります。試験対策で身につけた検定の使い分けを、ぜひ実データの解析にも応用していただければと思います。