メタアナリシス入門 ― 固定効果・変量効果モデルからフォレストプロット・出版バイアスまでRで実装する ―

- メタアナリシスとは何か(システマティックレビューとの関係・PICO)
- 固定効果モデルと変量効果モデルの違いと、逆分散重み付け・\(\tau^2\) の数理
- Rの
metaパッケージでリスク比を統合し、フォレストプロットを描く方法 - 異質性(\(I^2\)・\(\tau^2\)・予測区間)の評価と、メタ回帰で原因を探る方法
- 出版バイアスの検出(ファンネルプロット・Egger検定・trim-and-fill)
- 製薬・規制実務での使いどころと、ネットワークメタアナリシスへの発展
新しい薬や治療法の効果を判断するとき、たった一つの臨床試験の結果だけで結論を出してしまってよいのでしょうか。多くの場合、答えは「ノー」です。単一の臨床試験は、それ自体がどれほど丁寧に計画・実施されていても、組み入れられる患者数(サンプルサイズ)には限りがあり、検出したい効果が小さいときには十分な検出力(本当に効果があるときにそれを「効果あり」と正しく判定できる確率)を確保できないことが少なくありません。結果として、ある試験では「有意差あり」、別の試験では「有意差なし」と、一見すると矛盾した結論が並ぶことも珍しくないのです。
こうした状況で力を発揮するのが、メタアナリシス(meta-analysis)です。メタアナリシスとは、同じ問いを扱った複数の臨床試験や研究の結果を、統計的な手法を用いて定量的に統合する方法です。一つひとつの試験では曖昧だった効果も、複数のエビデンスを束ねることで、より精度の高い「全体としての効果」を推定できるようになります。実際、診療ガイドラインの推奨度の決定、システマティックレビュー、さらには規制当局による承認可否の判断など、医療における重要な意思決定の多くが、メタアナリシスによって統合されたエビデンスに支えられています。
本記事は、製薬企業で臨床試験の解析に携わる生物統計担当者の方、R や SAS を用いてデータ解析を行う実務家の方、そして統計学を学んでいる学生の方を主な対象としています。メタアナリシスは「複数の結果を平均するだけ」と誤解されがちですが、その背後には効果量・重み付け・試験間のばらつきといった、押さえておくべき統計的な考え方があります。
以下では、まずメタアナリシスとは何かという概念を整理し、続く章で数理的な背景を確認したうえで、最終的には R の meta パッケージを使った実装まで、一気通貫で扱っていきます。手を動かしながら理解できるよう構成しますので、ぜひ最後までお付き合いください。
メタアナリシスとは ― なぜ複数の試験を統合するのか
メタアナリシスを正しく理解するために、まずは似て非なる言葉との関係を整理しておきましょう。医学・薬学の論文を読んでいると、「ナラティブレビュー」「システマティックレビュー」「メタアナリシス」という三つの言葉に出会います。これらはしばしば混同されますが、役割は明確に異なります。
ナラティブレビュー(narrative review)は、専門家が特定のテーマについて文献を読み、自身の知見と解釈を交えて記述するレビューです。網羅性や再現性は必ずしも保証されず、著者の主観が入りやすいという特徴があります。一方、システマティックレビュー(systematic review)は、あらかじめ定めたプロトコル(手順書)に従い、PICO(Patient/Intervention/Comparison/Outcome:対象・介入・比較・アウトカム)で研究の問いを明確化し、文献検索・選択・評価の過程を透明かつ再現可能な形で行うレビューです。その報告は PRISMA(システマティックレビュー報告のための国際的なガイドライン)に沿って行われます。そしてメタアナリシスは、このシステマティックレビューで集められた複数の研究の結果を、統計的に統合する解析手法そのものを指します。つまり、メタアナリシスはシステマティックレビューの中に含まれる「定量的な統合のステップ」と位置づけられます。
| 区分 | 手順の透明性・再現性 | 結果の統合 |
|---|---|---|
| ナラティブレビュー | 低い(著者の主観に依存) | 定性的(文章での記述) |
| システマティックレビュー | 高い(プロトコル・PRISMAに準拠) | 定性的(+必要に応じて定量) |
| メタアナリシス | 高い(統計的手続きが明示される) | 定量的(効果量を統計的に統合) |
メタアナリシスの核心は、各試験から得られた効果量(effect size:治療効果の大きさを表す指標。リスク比やオッズ比、平均値の差など)を、その推定精度に応じて重み付けしながら一つの値にまとめる、という考え方にあります。直感的には、サンプルサイズが大きく結果のばらつきが小さい(=信頼できる)試験ほど大きな重みを与え、逆に小規模で不確実な試験の影響は抑える、というイメージです。
ここで重要になるのが、統合の前提として置く二つのモデルの違いです。一つは固定効果モデル(common effect model)で、「すべての試験は、唯一共通する真の効果を推定している」と仮定します。試験ごとの結果の違いは、単なる偶然のばらつき(標本誤差)にすぎないという立場です。もう一つは変量効果モデル(random effects model)で、「真の効果は試験ごとに少しずつ異なり、それらがある分布に従って散らばっている」と考えます。製薬の文脈では、対象集団・用量・実施地域・併用療法などが試験ごとに異なるのが普通であり、「真の効果が完全に同一」と仮定するのは現実的でないことが多いため、変量効果モデルが既定の選択肢になりやすいという点を押さえておきましょう。数理的な定式化は次の章で詳しく扱います。
メタアナリシスは万能の手法ではありません。「ゴミを入れればゴミが出る(garbage in, garbage out)」という言葉が示すとおり、統合する元の試験の質が低かったり、都合のよい結果ばかりが選ばれていたり(出版バイアス・選択バイアス)すると、いくら統計的に丁寧に統合しても、出てくる結論は誤ったものになります。「数を集めれば正しくなる」のではなく、一つひとつの試験の質とバイアスを吟味したうえで統合することが、信頼できるメタアナリシスの大前提です。
効果量の統合と数理 ― 逆分散重み付けと固定効果・変量効果モデル
メタアナリシスの中心的な作業は、複数の試験から得られた「効果量(effect size)」を統計的に1つに統合することです。まずは効果量の種類を整理しましょう。アウトカムの型によって用いる指標が異なり、特に比として定義される指標(RR・OR・HR)は、そのままでは分布が左右非対称になるため、対数変換してから統合し、最後に指数変換で元のスケールに戻すのが定石です。
| 効果量 | 適用場面 | 統合時の変換 |
|---|---|---|
| 平均差 MD | 連続アウトカム(同一単位) | 変換なし |
| 標準化平均差 SMD(Cohen’s d / Hedges’ g) | 連続アウトカム(尺度が異なる) | 変換なし(g は小標本補正) |
| リスク比 RR | 二値アウトカム | 対数 log(RR) で統合 |
| オッズ比 OR | 二値アウトカム(症例対照など) | 対数 log(OR) で統合 |
| リスク差 RD | 二値アウトカム(絶対差を見たい) | 変換なし |
| ハザード比 HR | 生存・時間イベント | 対数 log(HR) で統合 |
逆分散重み付けという発想。各試験 \(i\) の効果量推定値を \(\hat\theta_i\)、その分散を \(v_i\) とすると、統合では分散の逆数を重み \(w_i = 1/v_i\) として加重平均を取ります。固定効果モデルでの統合効果量とその分散は次式で与えられます。
\[ \hat\theta_{\mathrm{FE}} = \frac{\sum_i w_i \hat\theta_i}{\sum_i w_i}, \quad \mathrm{Var}(\hat\theta_{\mathrm{FE}}) = \frac{1}{\sum_i w_i} \]
ここで \(w_i = 1/v_i\) は試験 \(i\) の重みを表します。分散 \(v_i\) が小さい試験ほど重み \(w_i\) が大きくなるため、精度の高い(=サンプルサイズの大きい)試験ほど統合結果への寄与が大きくなります。これは「情報量の多い試験を信頼する」という直感に合致した、統計的に最も効率の良い重み付けです。
固定効果モデル(common/fixed effect) は、すべての試験が唯一共通の真の効果 \(\theta\) を測定していると仮定します。試験間のばらつきはすべて偶然の標本誤差とみなすため、上の式がそのまま統合推定量になります。
変量効果モデル(random effects) は、試験ごとに真の効果が異なり、それらが分布 \(\theta_i \sim N(\mu, \tau^2)\) に従うと仮定します。\(\mu\) は真の効果の平均、\(\tau^2\) は研究間分散(試験間の真の効果のばらつき)を表します。このとき重みは標本誤差と研究間分散の両方を含む形に変わります。
\[ w_i^{*} = \frac{1}{v_i + \widehat{\tau}^2} \]
ここで \(w_i^{*}\) は変量効果モデルでの重みで、\(\tau^2\) が大きい(試験間のばらつきが大きい)ほど各試験の重みの差が縮まり、小規模試験の相対的な寄与が増えます。
\(\tau^2\) の推定法には、計算が簡便でモーメント法に基づく DerSimonian-Laird(DL)法と、尤度に基づく REML(制限付き最尤法)があります。DL 法は長く標準でしたが、研究数が少ない場合に \(\tau^2\) を過小評価しやすく、近年は性質の良い REML が推奨されています。
\(\tau^2 = 0\) のとき変量効果モデルの重み \(w_i^{*}\) は固定効果モデルの \(w_i\) と一致します。つまり固定効果モデルは「研究間に異質性がない」という特殊ケースとみなせます。
統合の点推定とその信頼区間は「平均的な真の効果 \(\mu\) がどこにあるか」を示すものです。これに対し、予測区間(prediction interval) は「将来の新しい1試験での真の効果がどの範囲に入りそうか」を表し、研究間の異質性 \(\tau^2\) を直接反映します。概略は次式です。
\[ \hat\mu \pm t_{k-2}\sqrt{\widehat{\tau}^2 + \mathrm{Var}(\hat\mu)} \]
ここで \(\hat\mu\) は統合点推定、\(k\) は試験数、\(t_{k-2}\) は自由度 \(k-2\) の \(t\) 分布の臨界値です。根号内に \(\widehat{\tau}^2\) が加わるため、予測区間は信頼区間よりも必ず広くなります。異質性が大きい場合、信頼区間は有意でも予測区間が0をまたぐ、ということが起こり得る点が臨床的に重要です。
| 観点 | 固定効果モデル | 変量効果モデル |
|---|---|---|
| 前提 | 真の効果は単一 \(\theta\) | 真の効果は分布 \(N(\mu,\tau^2)\) |
| 重み | \(w_i = 1/v_i\) | \(w_i^{*} = 1/(v_i+\tau^2)\) |
| 信頼区間の幅 | 狭い | 広い(異質性を反映) |
| 使いどころ | 異質性がほぼないと考えられるとき | 試験条件が多様なとき(実務の既定) |
実務では試験デザインや対象集団の差が避けられないため、変量効果モデルを既定とし、予測区間を併記する報告が標準になりつつあります。
Rで実装する ― metaパッケージでフォレストプロットまで
ここまでの理屈を、実際のRコードで動かしてみましょう。Rには複数のメタアナリシス用パッケージがありますが、出力が読みやすくフォレストプロットも美しい meta パッケージが定番です。二値アウトカムなら metabin()、連続アウトカムなら metacont()、すでに効果量と標準誤差を計算済みなら汎用の metagen() を使い分けます。今回は二値アウトカムなので metabin() の出番です。未導入の場合は install.packages("meta") で入れておきましょう。
ステップ1:データの準備とパッケージ読み込み
題材には、メタアナリシスの教科書で繰り返し登場する古典的データ dat.bcg を使います。BCGワクチンの結核予防効果を調べた13試験のデータで、接種群・対照群それぞれの発症あり(tpos/cpos)・なし(tneg/cneg)の人数が入っています。
# install.packages("meta") # 未導入の場合
library(meta)
library(metafor)
data(dat.bcg, package = "metafor")
head(dat.bcg)
trial author year tpos tneg cpos cneg ablat alloc
1 1 Aronson 1948 4 119 11 128 44 random
2 2 Ferguson & Simes 1949 6 300 29 274 55 random
3 3 Rosenthal et al 1960 3 228 11 209 42 random
4 4 Hart & Sutherland 1977 62 13536 248 12619 52 random
5 5 Frimodt-Moller et al 1973 33 5036 47 5761 13 alternate
6 6 Stein & Aronson 1953 180 1361 372 1079 44 alternate
13試験ぶんの2×2の人数が並んでいることが確認できます。注目してほしいのが
ablat 列(試験実施地の緯度)です。赤道から離れた高緯度の試験ほどワクチン効果が高い傾向が知られており、この列はのちのメタ回帰で異質性の犯人を探す重要な手がかりになります。いまは「効果のばらつきを説明しうる変数が手元にある」と覚えておいてください。ステップ2:metabin() でリスク比を統合
それでは metabin() で13試験のリスク比(RR)を統合します。接種群・対照群それぞれの「発症数」と「例数(発症あり+なし)」を渡し、sm = "RR" で効果量をリスク比に指定します。common = FALSE で固定効果モデルを非表示にし、random = TRUE で変量効果モデルを採用、prediction = TRUE で予測区間も出します。
m <- metabin(
event.e = tpos, n.e = tpos + tneg, # 接種群:発症数 / 例数
event.c = cpos, n.c = cpos + cneg, # 対照群:発症数 / 例数
studlab = paste(author, year),
data = dat.bcg,
sm = "RR", # 統合する効果量=リスク比
method.tau = "REML", # 研究間分散τ²の推定法
common = FALSE, # 固定効果モデルは表示しない
random = TRUE, # 変量効果モデルを使う
prediction = TRUE # 予測区間も出力
)
summary(m)
Number of studies: k = 13
Number of observations: o = 51681 (o.e = 25844, o.c = 25837)
RR 95%-CI z p-value
Random effects model 0.4894 [0.3441; 0.6960] -3.95 < 0.0001
Prediction interval [0.1900; 1.2606]
Quantifying heterogeneity (with 95%-CIs):
tau^2 = 0.3115 [0.1374; 1.0314]; tau = 0.5581 [0.3706; 1.0156]
I^2 = 92.1% [88.5%; 94.6%]; H = 3.56 [2.96; 4.29]
Test of heterogeneity:
Q d.f. p-value
152.23 12 < 0.0001
Details of meta-analysis methods:
- Inverse variance method (random effects model)
- Restricted maximum-likelihood estimator for tau^2
- Prediction interval based on t-distribution (df = 11)
変量効果モデルの統合リスク比は 0.49(95%CI 0.34〜0.70)。接種群の結核発症リスクは対照群のおよそ半分で、ワクチンに予防効果がありそうだとわかります。ただし手放しでは喜べません。
I^2 = 92.1% と異質性が極めて大きく、tau^2 = 0.31、異質性検定も Q = 152.23, p < 0.0001 と明確に有意です。さらに予測区間は 0.19〜1.26 と1をまたいでおり、「次に行う試験では効果がないかもしれない」幅広さです。つまり「平均RRは0.49」という一点だけを見て満足してはいけません。なぜこれほど結果がばらつくのか、その原因を探る必要があります。ステップ3:フォレストプロットの作成
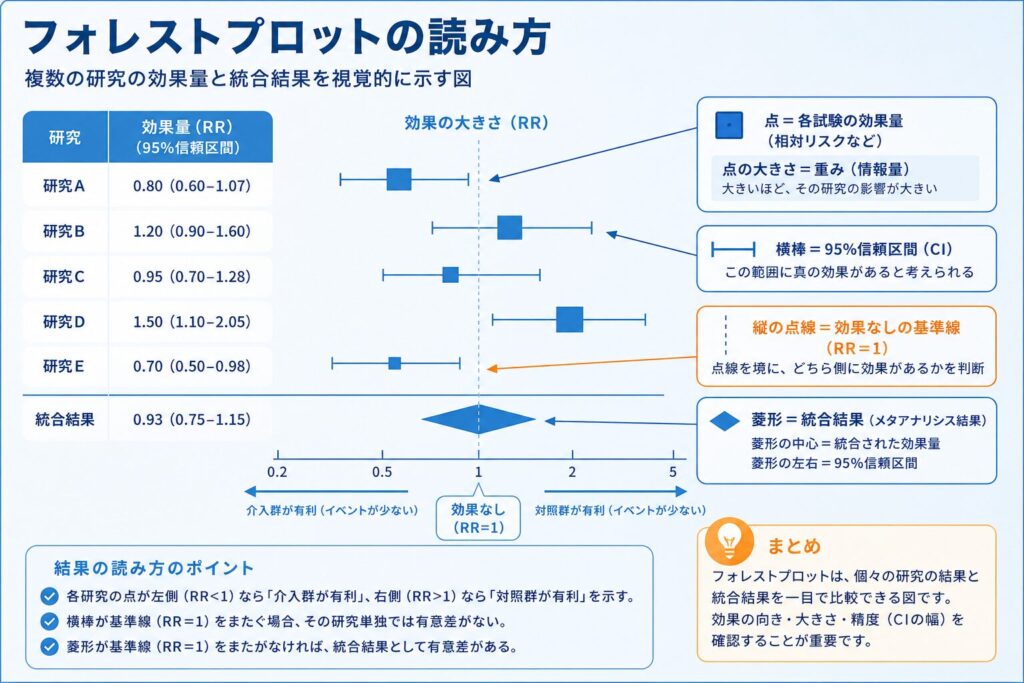
メタアナリシスの結果は、数字の羅列より1枚の図で見るほうが直感的です。forest() 関数にモデルを渡すだけで、各試験の効果量と統合結果をまとめたフォレストプロットが描けます。
forest(m,
sortvar = TE, # 効果量順に並べる
prediction = TRUE, # 予測区間を表示
label.left = "接種群が有利",
label.right = "対照群が有利")
フォレストプロットの読み方を押さえておきましょう。横軸はリスク比で、中央の縦の基準線が RR = 1(効果なし)を表します。各行が1つの試験で、四角い点がその試験の効果量、点の大きさはメタアナリシスでの重み(例数が多く精度の高い試験ほど大きい)を示します。点から左右に伸びる横棒が各試験の95%信頼区間で、棒が長いほど推定が不確かです。そして一番下の菱形(ダイヤモンド)が統合結果で、横幅が統合推定値の95%信頼区間にあたります。菱形が基準線より左に寄っていれば接種群が有利、ということです。多くの試験の点が基準線の左に散らばりつつ、その左右へのばらつき自体が大きいことを、図からも読み取れるはずです。
メタアナリシスの理論をさらに体系的に学びたい方は、本記事末尾の参考書籍セクションで紹介する丹後俊郎『新版 メタ・アナリシス入門』などが手元にあると、固定効果・変量効果から多変量・ネットワークメタアナリシスまで一気に視野が広がります。
異質性の評価とサブグループ・メタ回帰
複数の試験を統合するとき、必ず確認すべきなのが異質性(heterogeneity)です。これは「試験間で真の効果が同じではなく、ばらついている」状態を指します。臨床試験は対象集団・用量・追跡期間・実施地域がそれぞれ違いますから、効果量が完全に一致するほうがむしろ稀です。問題は、そのばらつきが「偶然の範囲」なのか「本当に違う」のかを見分けることです。
異質性を測る代表的な指標は3つあります。Cochran’s Q検定は「すべての試験の真の効果は等しい」という帰無仮説を検定します。\(I^2\)統計量は、観測された全分散のうち偶然ではなく異質性に由来する割合(%)を表し、25 / 50 / 75% がそれぞれ低 / 中 / 高の目安とされます。そして\(\tau^2\)(タウ2乗)は研究間の真の効果の分散そのもので、変量効果モデルの中核をなす量です。
走る例の BCG ワクチン13試験では、前章の summary(m) にこれらが出力されています。改めて取り出してみます。
# 異質性の要約(前章のsummary(m)に含まれる指標)
m$I2; m$tau2; m$Q; m$pval.Q
Quantifying heterogeneity:
tau^2 = 0.3115; I^2 = 92.1%; Q = 152.23, df = 12, p < 0.0001
\(I^2\) が約92%、\(\tau^2\) が約0.31、Q検定は p<0.0001 と、いずれも異質性が非常に大きいことを示しています。これは「13試験を単純に1つの数字へまとめてよいのか」という疑問を突きつけます。実際、変量効果モデルの予測区間(前章で算出した、新しい試験で期待される効果の範囲)は RR=1 をまたぎます。つまり平均としてはBCGは結核を予防するが、ある地域・条件で実施する次の試験では効果が出ない可能性も残るということです。統合値の点推定だけを見て「効く」と断じるのは早計だと分かります。
異質性が大きいときの定石は、「無理にまとめる」のではなく「なぜばらつくのかを説明する」ことです。その手段がサブグループ解析とメタ回帰(meta-regression)です。BCG試験では古くから「実施地域の緯度が高いほどワクチンが有効」という知見が知られています。緯度(ablat:赤道からの絶対緯度)を共変量にしてメタ回帰を行ってみましょう。
# メタ回帰:緯度(ablat)で異質性を説明できるか
mr <- metareg(m, ~ ablat)
mr
Mixed-Effects Model (k = 13; tau^2 estimator: REML)
tau^2 (residual heterogeneity): 0.0764
I^2 (residual heterogeneity): 68.4%
R^2 (amount of heterogeneity accounted for): 75.6%
Test of Moderators (coefficient 2):
QM(df = 1) = 16.36, p-val < 0.0001
Model Results:
estimate se zval pval ci.lb ci.ub
intrcpt 0.2515 0.2491 1.010 0.3126 -0.2368 0.7397
ablat -0.0291 0.0072 -4.045 <.0001 -0.0432 -0.0150
緯度の回帰係数は \(-0.0291\) と負で有意です。log(RR) が緯度1度あたり約0.03ずつ小さくなる、つまり緯度が高い地域ほどBCGがよく効くことを意味します。さらに注目すべきは \(R^2\)=75.6%、残差 \(I^2\) が92%から68%へ下がった点です。つまり当初の大きな異質性の大部分が、緯度という1変数で説明できてしまったのです。
「効果がばらつく」のは欠点ではなく、原因を突き止める手がかりになります。BCG例で緯度が異質性の約4分の3を説明したのは、メタ回帰の威力を示す古典的な成功例です。サブグループ解析が「高緯度群 vs 低緯度群」のようにカテゴリで分けるのに対し、メタ回帰は緯度のような連続的な試験レベル共変量をそのまま扱え、用量や年齢中央値など量的な要因の影響を評価できます。
メタ回帰は試験数が少ないと過適合(オーバーフィット)しやすいのが弱点です。経験則として共変量1つにつき試験10件程度は欲しいところで、k=13で共変量を何個も投入するのは危険です。また、緯度のような試験レベルの関連を個人レベルに当てはめると「生態学的誤謬(ecological fallacy)」に陥ります。「高緯度に住む人ほどBCGが効く」と個人へ短絡してはいけません。
出版バイアスの検出 ― ファンネルプロット・Egger検定・trim-and-fill
メタアナリシスのもう一つの落とし穴が出版バイアス(publication bias)です。有意で好都合な結果ほど論文として世に出やすく、小規模で否定的な結果は研究者の引き出しに眠ったまま(file drawer problem:お蔵入り問題)になりがちです。出版された論文だけを集めて統合すると、効果を過大評価する方向に偏ってしまうのです。
これを視覚的に点検する道具がファンネルプロット(funnel plot:漏斗プロット)です。横軸に各試験の効果量、縦軸に精度(標準誤差の逆、つまり試験規模が大きいほど上)をとります。バイアスがなければ、大規模試験は統合値の近くに、小規模試験は左右に広く散らばり、全体として左右対称の漏斗(ファンネル)型になります。逆に片側だけ小規模試験が欠けて非対称なら、出版バイアスを疑います。
# ファンネルプロット
funnel(m)
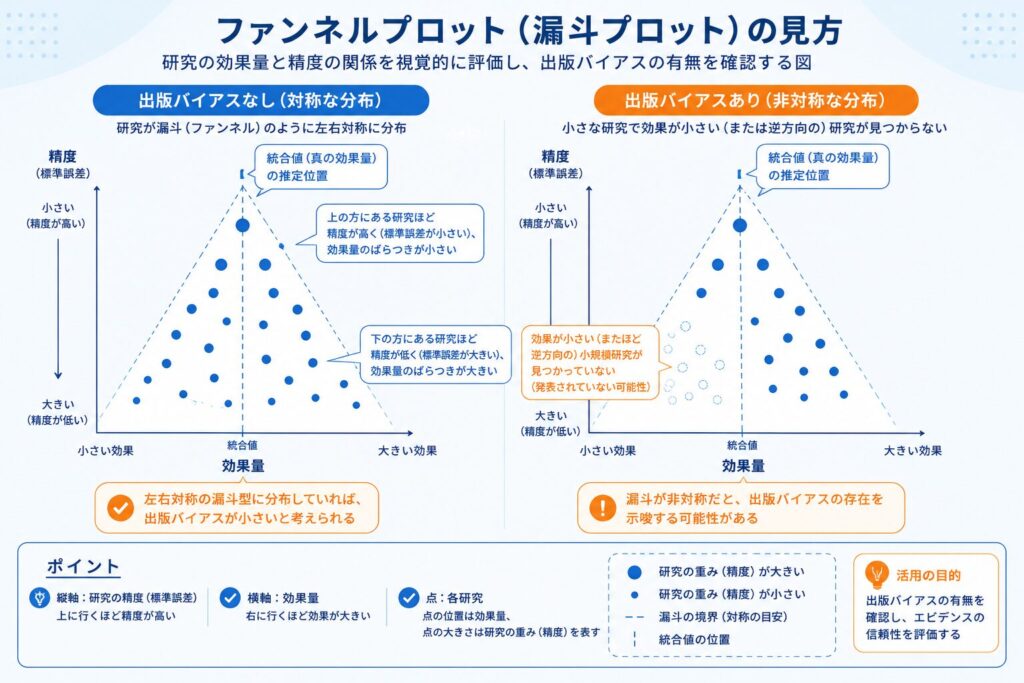
ただし「左右対称かどうか」を目視で判断するのは主観的です。そこで非対称性を統計的に検定するのがEgger検定(Egger’s test)です。
# Egger検定(ファンネル非対称性の検定)
metabias(m, method.bias = "Egger")
Linear regression test of funnel plot asymmetry
Test result: t = -1.42, df = 11, p-value = 0.1832
Sample estimates:
bias se.bias
-1.6823 1.1845
BCG例では p≈0.18 と明確には有意ではありません。つまり統計的には強い非対称性の証拠は得られませんでした。ここで前章とつながります。ファンネルが多少ゆがんで見えても、その非対称性の主因は出版バイアスというより、緯度による真の異質性かもしれないのです。実際、効果が緯度で大きく変わる集団を1枚のファンネルに重ねれば、それだけで歪んで見えます。非対称性=出版バイアスと短絡してはいけません。
最後に、仮に試験が欠けているとしたら結論はどう変わるかを調べる感度分析がtrim-and-fill法(トリム・アンド・フィル)です。非対称性から「出版されなかったであろう試験」の数と位置を推定し、それらを補完したうえで統合値を再計算します。
# trim-and-fill 法による感度分析
tf <- trimfill(m)
tf
Estimate of missing studies on the left side: 0
Number of studies combined: k = 13
Number of added studies: 0
Random effects model RR 95%-CI
0.4894 [0.3441; 0.6960]
補完すべき試験は0件と推定され、統合 RR は元の結果と変わりません。結論は頑健(ロバスト)だと確認できました。
実務でのポイント
メタアナリシスは学術的な統合手法にとどまらず、製薬・規制の現場で広く実装されています。診療ガイドラインの推奨度はメタアナリシスのエビデンスを土台にしますし、HTA(医療技術評価:Health Technology Assessment)では費用対効果の入力値として統合効果量が使われます。市販後の安全性シグナルの統合、あるいは希少疾患のように単一試験では症例数が足りない領域で複数試験のエビデンスを束ねて補強する用途も重要です。
実務で最も大切なのは、固定効果モデルか変量効果モデルかを事前にプロトコルや解析計画書(SAP)で決めておくことです。結果を見てから都合のよいモデルを選ぶ「後出し」は、p値ハッキングと同じで信頼性を損ないます。異質性が大きければ変量効果、というだけでなく、対象とする推論(この試験群への推論か、将来の試験を含む母集団への推論か)に応じて事前に方針を固めます。
データの形にも種類があります。各論文の要約統計量(効果量と標準誤差)を集める集計データ(AD:Aggregate Data)メタアナリシスが一般的ですが、各試験から患者一人ひとりの生データを集める個別患者データ(IPD:Individual Patient Data)メタアナリシスはゴールドスタンダードとされます。IPDなら統一した解析・サブグループ評価・生態学的誤謬の回避が可能ですが、データ収集の労力とコストは桁違いです。
さらに発展として、A対B・A対Cの試験はあるがB対Cの直接比較がない、という状況で複数治療を同時に比較するネットワークメタアナリシス(NMA)や、患者背景を揃えて間接比較するMAICなどの手法があります。本記事の範囲を超えますが、ペアワイズのメタアナリシスがその出発点になります。
・固定効果か変量効果かは必ず事前にプロトコル/SAPで規定し、後出しでモデルを選ばない。
・統合値の点推定だけでなく、\(I^2\)・\(\tau^2\)・予測区間で異質性を必ず評価し、大きければサブグループ解析やメタ回帰で原因を探る。
・出版バイアスはファンネルプロット・Egger検定・trim-and-fillで点検するが、k が小さいと検出力が低いことを踏まえて慎重に解釈する。
・可能なら IPD メタアナリシスを、複数治療の比較が必要なら NMA を検討するなど、目的に応じて手法を選ぶ。
この記事をより深く理解するための参考書籍
メタアナリシスをさらに深く学びたい方に、おすすめの書籍を3冊ご紹介します。理論・入門・モデリングの3つの角度から選びました。






関連記事・次のステップ
メタアナリシスは、臨床試験の効果指標や因果推論・規制の考え方と密接につながっています。あわせて読むと理解が深まる記事をご紹介します。
- 外部対照群の統計手法 (2/2) ― 傾向スコアマッチング・MAIC・ベイズ動的借用 ―:本記事の最後で触れた間接比較(MAIC)やネットワークメタアナリシスの周辺を、外部対照群の観点から扱っています。
- ITT・FAS・PP・mITT の違いを完全整理 ― ICH E9 が定める臨床試験の解析対象集団 ―:統合する元の臨床試験を読むうえで欠かせない、解析対象集団の考え方を整理しています。
- mmrmをRで実装する ― mmrmパッケージ・nlme/glsで反復測定混合モデルを動かす ―:変量効果モデルと同じ「混合モデル」の発想を、反復測定データのR実装から学べます。
まとめ
本記事では、メタアナリシスの基礎から R による実装までを一気通貫で紹介しました。メタアナリシスは単に複数の結果を平均する手法ではなく、各試験の効果量を精度に応じて重み付けし、試験間のばらつき(異質性)まで考慮して統合する、奥行きのある統計手法です。固定効果モデルと変量効果モデルの前提の違い、逆分散重み付けや \(\tau^2\) の数理を押さえたうえで、R の meta パッケージを使えば、リスク比の統合からフォレストプロット、異質性の評価、メタ回帰、出版バイアスの検出まで、一連の解析を再現性高く実行できます。
BCGワクチンの例で見たように、統合された効果量の「平均」だけを見るのは危険です。\(I^2\)・\(\tau^2\)・予測区間で異質性を確認し、大きければメタ回帰で原因(今回は緯度)を探り、ファンネルプロットや Egger 検定で出版バイアスを点検する。この一連の吟味こそが、メタアナリシスを信頼できるエビデンスに変える要になります。製薬・規制の実務では、固定効果か変量効果かを事前にプロトコルで定め、適切なモデルと感度分析を組み合わせることが求められます。ぜひご自身のデータでも meta パッケージを動かし、エビデンスを統合する力を実務に活かしていただければと思います。