統計検定準1級「統計的推定」攻略 ― 最尤法・十分統計量・フィッシャー情報量・クラメール–ラオの不等式の典型出題対策 ―

この記事でわかること
統計検定準1級の「統計的推定」は、推定量の性質から最尤推定、フィッシャー情報量、クラメール–ラオの不等式まで、数理統計の核心が問われる重要分野です。この記事では、頻出テーマを試験対策と実務の両面から整理します。
・不偏性/一致性/有効性/十分性など推定量に求められる性質
・最尤推定とフィッシャー情報量の求め方
・クラメール–ラオの不等式・十分統計量・UMVUEの考え方
・準1級の典型出題パターンと例題3問の解き方
・受験対策と実務での使いどころ
はじめに ― 準1級における「統計的推定」の位置づけ
統計検定準1級は、統計学の実務的な運用能力を測る試験として位置づけられています。試験方式はCBT(コンピュータを使った受験)で、試験時間は90分、出題数はおおむね20〜30問、100点満点で60点以上が合格ラインとされています(最新の正確な情報は公式サイトでご確認ください)。この試験の出題範囲には「統計的推測(推定)」が明記されており、統計的推定は準1級の主要な出題分野の一つになっています。
なぜ推定論がこれほど重要なのでしょうか。それは、推定が「手元のデータから母集団の未知のパラメータ(母数)を推し量る」という、統計解析のもっとも根幹的な営みだからです。実務の現場でも推定論は至るところに顔を出します。ロジスティック回帰、生存時間解析のCox比例ハザードモデル、臨床試験で標準的に用いられるMMRM(反復測定混合モデル)など、製薬の主要な解析手法はいずれも最尤法という推定の枠組みの上に成り立っています。パラメータの点推定値も、その標準誤差(推定のばらつきの目安)も、突き詰めれば最尤推定とフィッシャー情報量から導かれています。
つまり、統計的推定を理解することは、単に試験に合格するためだけでなく、日々の解析結果を正しく読み解くための土台を築くことにほかなりません。標準誤差や信頼区間がどこから来ているのかを知っていれば、解析結果への理解は一段と深くなります。
本記事の対象読者は、統計検定準1級の受験を目指す方、そして製薬・実務の現場で推定論を使う方です。準1級の推定分野は、用語の定義を暗記するだけでは太刀打ちできず、簡単な導出を自分の手で追える力が求められます。
そこで本記事では、まず推定量に求められる基本的な性質(不偏性・一致性・有効性・十分性)を整理し、続いて最尤推定とフィッシャー情報量の考え方を具体例とともに解説します。有効性の下限を与えるクラメール–ラオの不等式については、この理論編に続く後半パートで詳しく扱います。それでは、推定量の「良さ」を測る4つのものさしから見ていきましょう。
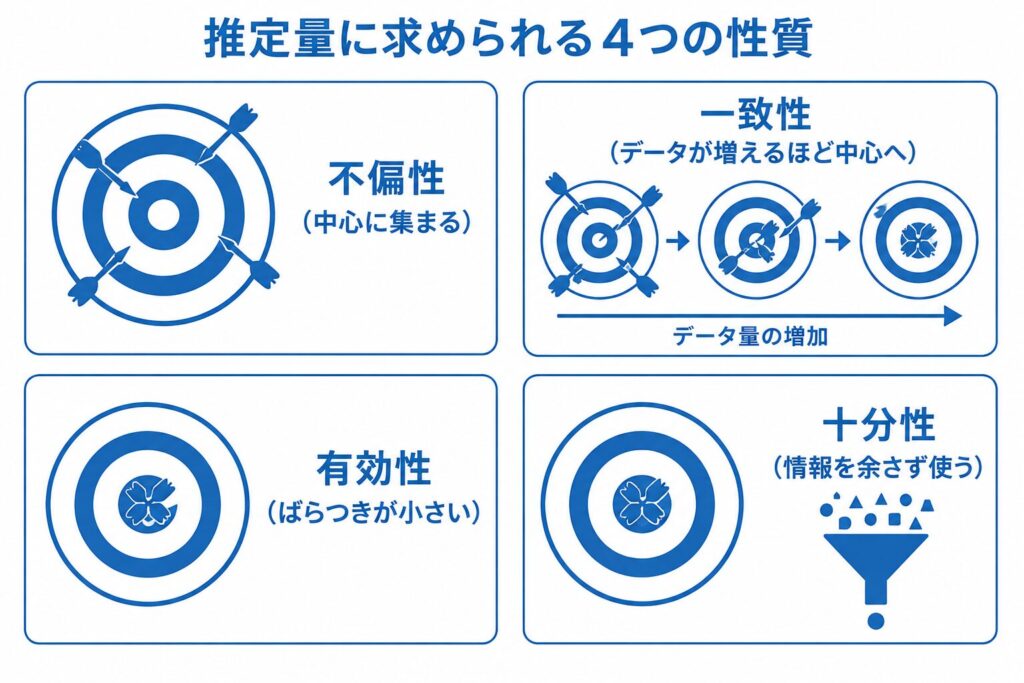
推定量に求められる性質 ― 不偏性・一致性・有効性・十分性
母集団のパラメータ \(\theta\) を推定するとき、標本 \(X_1,\dots,X_n\) から計算される推定量 \(\hat{\theta}\) は無数に考えられます。標本平均、標本中央値、最尤推定量など、候補はいくつもあるわけです。では、その中で「良い推定量」とはどういうものでしょうか。この良し悪しを測るための代表的なものさしが、これから解説する不偏性・一致性・有効性・十分性の4つです。
これらは準1級で頻出の概念であり、定義とその直感をセットで押さえておくことが得点への近道になります。一つずつ見ていきましょう。
不偏性
不偏性(unbiasedness)とは、推定量の期待値が真のパラメータに一致する性質のことです。数式では次のように定義されます。
\[ E[\hat{\theta}] = \theta \]
ここで左辺は推定量 \(\hat{\theta}\) の期待値、右辺は真のパラメータ \(\theta\) を表します。つまり「何度も標本を取り直して推定を繰り返せば、平均的には真の値を的中させる」という性質です。系統的な偏り(バイアス)がない、と言い換えてもよいでしょう。
たとえば標本平均 \(\bar{X}=\frac{1}{n}\sum_{i=1}^{n}X_i\) は母平均 \(\mu\) の不偏推定量です。実際、\(E[\bar{X}]=\frac{1}{n}\sum E[X_i]=\mu\) となり、期待値がぴったり \(\mu\) に一致します。
一方で標本分散には注意が必要です。偏差平方和を \(n\) で割った \(\frac{1}{n}\sum(X_i-\bar{X})^2\) は母分散 \(\sigma^2\) を過小評価してしまい不偏になりません。そこで \(n\) ではなく \(n-1\) で割った
\[ s^2 = \frac{1}{n-1}\sum_{i=1}^{n}(X_i-\bar{X})^2 \]
を用います。この \(s^2\) が母分散 \(\sigma^2\) の不偏推定量になります。分母が \(n-1\) になっているのは、\(\bar{X}\) を推定に使ったぶん自由度が1つ減るためだと理解しておくとよいでしょう。
一致性
一致性(consistency)とは、標本サイズ \(n\) を大きくしていくと推定量が真の値に限りなく近づく性質です。数式では確率収束を使って次のように書きます。
\[ \hat{\theta}_n \xrightarrow{p} \theta \quad (n \to \infty) \]
ここで矢印の上の \(p\) は確率収束を表し、「\(n\) を大きくすれば \(\hat{\theta}_n\) が \(\theta\) からずれる確率がいくらでも小さくなる」ことを意味します。
標本平均 \(\bar{X}\) は母平均 \(\mu\) の一致推定量です。大数の法則により、標本サイズを増やすほど標本平均は母平均へ収束していきます。データをたくさん集めれば集めるほど推定が真の値に近づく、という直感そのものが一致性です。
不偏性と一致性は混同されやすい概念です。不偏性は「有限の標本サイズでも平均的に的中する」性質、一致性は「標本サイズを無限に大きくしたときの収束」の性質であり、両者は別物です。不偏でなくても一致する推定量、不偏でも一致しない推定量が存在します。
有効性(+漸近有効性)
有効性(efficiency)とは、推定のばらつき(分散)が小さいという性質です。2つの不偏推定量があれば、分散の小さいほう、つまりより精度の高いほうが「有効」だと考えます。
不偏推定量の分散には理論的な下限が存在し、その下限を達成する推定量を「有効推定量」と呼びます。この下限を与えるのがクラメール–ラオの不等式であり、後半パートで詳しく扱います。ここでは「不偏推定量の分散にはこれ以上小さくできないという壁があり、その壁ぴったりに到達できる推定量が最も有効だ」という直感を押さえておいてください。
有限の標本サイズで下限を達成できなくても、標本サイズを大きくしたときに漸近的に下限へ到達する性質を漸近有効性(asymptotic efficiency)と呼びます。後述する最尤推定量は、一定の条件のもとでこの漸近有効性をもつことが知られており、これが最尤法が広く使われる大きな理由の一つになっています。
十分性(因子分解定理)
十分性(sufficiency)とは、統計量がパラメータに関する情報を余すところなく含んでいる性質です。十分統計量 \(T(X_1,\dots,X_n)\) が与えられれば、元のデータそのものはもう必要なく、パラメータ \(\theta\) の推定に関して情報の損失が起きません。
十分統計量を見つける実用的な道具が、フィッシャー–ネイマンの因子分解定理です。統計量 \(T\) が \(\theta\) の十分統計量であることは、同時確率(密度)関数 \(f\) が次のように分解できることと同値です。
\[ f(x_1,\dots,x_n \mid \theta) = g\bigl(T(x),\,\theta\bigr)\, h(x_1,\dots,x_n) \]
ここで \(g\) は統計量 \(T(x)\) とパラメータ \(\theta\) を通してのみデータに依存する部分、\(h\) は \(\theta\) を含まずデータのみに依存する部分です。この形に分解できれば \(T\) は十分統計量だと判定できます。たとえば正規分布ではデータの総和 \(\sum X_i\)(および二乗和 \(\sum X_i^2\))が、ポアソン分布では総和 \(\sum X_i\) が十分統計量になります。
以上の4つの性質を、まとめて整理しておきましょう。
| 性質 | 定義の要点 | 直感 |
|---|---|---|
| 不偏性 | \(E[\hat{\theta}]=\theta\) | 平均的に真の値を的中させ、系統的な偏りがない |
| 一致性 | \(\hat{\theta}_n \xrightarrow{p} \theta\) | 標本を増やすほど真の値へ近づく |
| 有効性 | 不偏推定量のなかで分散が最小 | 推定のばらつきが小さく精度が高い |
| 十分性 | 因子分解定理で判定 | パラメータの情報を余さず含み、情報の損失がない |
最尤推定とフィッシャー情報量
推定量の良さを測るものさしがそろったところで、実際に「良い推定量」を作り出す代表的な方法である最尤推定を見ていきましょう。準1級でもっとも問われる推定手法であり、実務の解析の根幹でもあります。
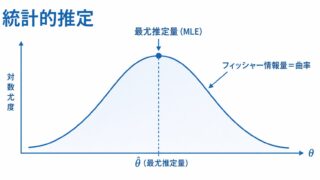
最尤推定(Maximum Likelihood Estimation, MLE)とは、「手元のデータがもっとも観測されやすくなるようなパラメータの値」を推定値とする方法です。観測データを固定してパラメータの関数とみなしたものを尤度 \(L(\theta)\) と呼び、これを最大にする \(\theta\) を最尤推定量 \(\hat{\theta}\) とします。
\[ L(\theta) = \prod_{i=1}^{n} f(X_i \mid \theta) \]
尤度は積の形なので、そのまま扱うより対数をとった対数尤度 \(\ell(\theta)=\log L(\theta)\) を最大化するほうが計算が楽になります(対数は単調増加なので最大化する \(\theta\) は変わりません)。対数尤度を \(\theta\) で微分したものをスコア \(S(\theta)=\partial\ell/\partial\theta\) と呼び、これを0とおいたスコア方程式
\[ S(\theta) = \frac{\partial \ell(\theta)}{\partial \theta} = 0 \]
を解くことで最尤推定量が得られます。ここでスコアは対数尤度の傾きを表しており、傾きが0になる点で対数尤度が最大になる、という素直な発想です。
正規分布の μ・σ² の最尤推定
正規分布 \(N(\mu, \sigma^2)\) から得られた標本の対数尤度は次のようになります。
\[ \ell(\mu, \sigma^2) = -\frac{n}{2}\log(2\pi) – \frac{n}{2}\log \sigma^2 – \frac{1}{2\sigma^2}\sum_{i=1}^{n}(X_i-\mu)^2 \]
これを \(\mu\) と \(\sigma^2\) それぞれで偏微分して0とおくと、最尤推定量は次のように求まります。
\[ \hat{\mu} = \bar{X}, \qquad \hat{\sigma}^2 = \frac{1}{n}\sum_{i=1}^{n}(X_i-\bar{X})^2 \]
ここで \(\hat{\mu}\) は標本平均そのもの、\(\hat{\sigma}^2\) は偏差平方和を \(n\) で割った値です。注意したいのは、分散の最尤推定量は分母が \(n\) であり、先ほどの不偏推定量 \(s^2\)(分母 \(n-1\))とは異なる点です。つまり最尤推定量は必ずしも不偏になるとは限りません。
ポアソン分布の λ の最尤推定
次に、計数データによく使われるポアソン分布 \(\mathrm{Po}(\lambda)\) を考えます。確率関数は \(f(x\mid\lambda)=\frac{\lambda^x e^{-\lambda}}{x!}\) なので、対数尤度は次のようになります。
\[ \ell(\lambda) = \left(\sum_{i=1}^{n} X_i\right)\log \lambda – n\lambda – \sum_{i=1}^{n}\log(X_i!) \]
スコア方程式は次のとおりです。
\[ S(\lambda) = \frac{\sum_{i=1}^{n} X_i}{\lambda} – n = 0 \]
これを解くと、ポアソン分布のパラメータ \(\lambda\) の最尤推定量は標本平均になります。
\[ \hat{\lambda} = \frac{1}{n}\sum_{i=1}^{n} X_i = \bar{X} \]
ここで \(\hat{\lambda}=\bar{X}\) は、単位時間あたりの平均発生回数を素直に標本平均で見積もることを意味します。直感にもよく合う結果です。
フィッシャー情報量
最尤推定と切り離せないのがフィッシャー情報量 \(I(\theta)\) です。これは「データがパラメータについてどれだけの情報を持っているか」を測る量で、次の2つの表現があります。
\[ I(\theta) = E\bigl[S(\theta)^2\bigr] = -E\!\left[\frac{\partial^2 \ell(\theta)}{\partial \theta^2}\right] \]
ここで左の表現はスコアの2乗の期待値、右の表現は対数尤度の2階微分(曲率)の期待値の符号を反転したものです。一定の正則条件のもとで両者は一致します。直感的には、対数尤度が尖っている(曲率が大きい)ほどパラメータの値が特定しやすく、情報量が大きいと理解できます。
例としてポアソン分布で計算してみましょう。1観測あたりの対数尤度の2階微分は \(\partial^2\ell/\partial\lambda^2 = -X/\lambda^2\) であり、\(E[X]=\lambda\) を代入すると、1観測あたりのフィッシャー情報量は次のようになります。
\[ I_1(\lambda) = -E\!\left[-\frac{X}{\lambda^2}\right] = \frac{\lambda}{\lambda^2} = \frac{1}{\lambda} \]
ここで \(I_1(\lambda)=1/\lambda\) は、\(\lambda\) が小さい(まれな事象)ほど1観測あたりの情報量が大きくなることを示しています。
最尤推定量の漸近正規性
最尤推定量が実務で重宝される最大の理由が、漸近正規性です。一定の正則条件のもとで、標本サイズ \(n\) が大きいとき最尤推定量は次の分布に従います。
\[ \sqrt{n}\,(\hat{\theta}-\theta) \xrightarrow{d} N\!\left(0,\ I_1(\theta)^{-1}\right) \]
ここで矢印の上の \(d\) は分布収束を表し、\(I_1(\theta)\) は1観測あたりのフィッシャー情報量です。この式は「最尤推定量は近似的に正規分布に従い、そのばらつき(分散)は1観測あたりの情報量の逆数を \(n\) で割ったもの、すなわち \(I_1(\theta)^{-1}/n\) になる」ことを意味します。情報量が大きいほど推定のばらつきが小さくなる、という自然な関係が見てとれます。
実務で報告される標準誤差は、まさにこの漸近分散の平方根から計算されています。ロジスティック回帰やCox回帰、MMRMのソフトウェア出力に並ぶ標準誤差の背後には、このフィッシャー情報量が働いているのです。
それでは、ポアソン分布の最尤推定量が本当に標本平均になるか、Rで数値的に確認してみましょう。optim 関数で対数尤度を最大化(負の対数尤度を最小化)し、理論値である標本平均と一致するかを見ます。
set.seed(1)
x <- rpois(500, lambda = 3) # 真のλ=3 から500個生成
neg_loglik <- function(lambda) -sum(dpois(x, lambda, log = TRUE))
fit <- optim(par = 1, fn = neg_loglik, method = "Brent",
lower = 0.01, upper = 10)
c(optim_MLE = fit$par, sample_mean = mean(x))
> c(optim_MLE = fit$par, sample_mean = mean(x))
optim_MLE sample_mean
2.976 2.976
数値最適化で求めた最尤推定量(2.976)と標本平均(2.976)が完全に一致しました。これは先ほど数式で導いた \(\hat{\lambda}=\bar{X}\) が正しいことを実データで裏づけています。真の \(\lambda=3\) に対して推定値2.976と近く、標本サイズを増やせば一致性によりさらに真の値へ近づいていきます。このように、複雑なモデルでも最尤推定は「対数尤度を最大化する」という同じ原理で数値的に解けるため、実務の解析ソフトの内部でも同じ仕組みが動いています。
ここまでで、最尤推定の枠組みとフィッシャー情報量、そして最尤推定量の漸近的なばらつきを見てきました。有効推定量の分散の下限、すなわち「不偏推定量の分散はどこまで小さくできるのか」という問いに答えるクラメール–ラオの不等式については、後半のパートで詳しく扱います。
クラメール–ラオの不等式と有効推定量
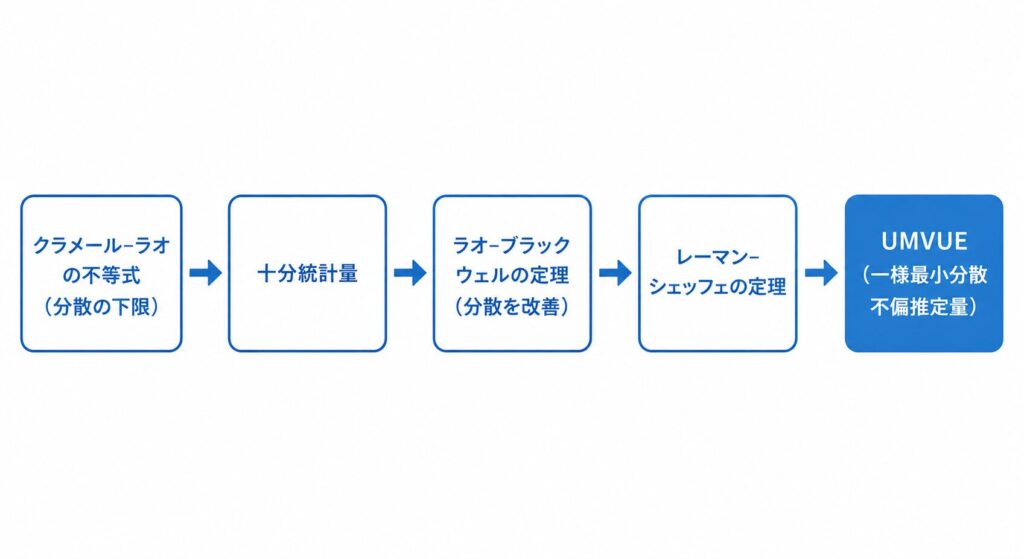
前半で学んだフィッシャー情報量 \(I(\theta)\) は、単なる曲率の指標にとどまりません。実は「不偏推定量の分散はどこまで小さくできるか」という精度の理論限界を直接与えます。ここでは、その限界を与えるクラメール–ラオの不等式と、限界に到達する「もっとも良い推定量」を体系的に見つける道具立てを整理します。
クラメール–ラオの不等式
正則条件(尤度が \(\theta\) について微分可能で、積分と微分の順序交換が許されるなど)のもとで、\(\theta\) の任意の不偏推定量 \(\hat\theta\) の分散には次の下限があります。
\[ \mathrm{Var}(\hat\theta) \ge \frac{1}{I(\theta)} \]
これがクラメール–ラオの下限(Cramér–Rao Lower Bound, CRLB)です。ここで \(I(\theta)\) は標本全体のフィッシャー情報量で、\(X_1,\dots,X_n\) が独立同分布なら1標本あたりの情報量 \(I_1(\theta)\) を用いて \(I(\theta)=nI_1(\theta)\) と書けます。したがって \(n\) 標本での下限は次のようになります。
\[ \mathrm{Var}(\hat\theta) \ge \frac{1}{nI_1(\theta)} \]
意味はシンプルです。どんなに工夫して不偏推定量を作っても、その分散をこの値より小さくすることはできません。「これ以上は精度を上げられない」という理論的な壁を表しており、標本サイズ \(n\) を増やすほど下限は \(1/n\) のペースで小さくなる、という直感とも一致します。
フィッシャー情報量 \(I(\theta)\) が大きい=尤度がパラメータに敏感に反応する=データがパラメータについて多くを語る、という状況では下限 \(1/I(\theta)\) が小さくなり、精度の高い推定が原理的に可能になります。情報量と精度の限界は表裏一体なのです。
有効推定量と有効性:CRLBをちょうど達成する不偏推定量、すなわち \(\mathrm{Var}(\hat\theta)=1/I(\theta)\) を満たす \(\hat\theta\) を有効推定量(efficient estimator)と呼びます。ある不偏推定量の分散が下限にどれだけ近いかを測る指標を有効性(efficiency)といい、\(\mathrm{eff}(\hat\theta)=\dfrac{1/I(\theta)}{\mathrm{Var}(\hat\theta)}\le 1\) で定義します。値が1に近いほど無駄のない推定量です。有限標本では下限に届かなくても、標本サイズ \(n\to\infty\) の極限で有効性が1に収束するとき、その推定量は漸近有効(asymptotically efficient)と呼ばれます。前半で見た最尤推定量(MLE)は、正則条件のもとでまさにこの漸近有効性をもつのが大きな長所でした。
十分統計量とラオ–ブラックウェルの定理
有効推定量が存在するとは限りません。そこで「与えられた不偏推定量を、より分散の小さい不偏推定量へ改善する」仕組みが必要になります。その中心が十分統計量とラオ–ブラックウェルの定理です。
十分統計量 \(T=T(X_1,\dots,X_n)\) とは、パラメータ \(\theta\) に関する情報を余すことなく含んだ統計量のことでした。\(T\) を知れば、元データの残りはもう \(\theta\) について何も語らない、というイメージです。ラオ–ブラックウェルの定理は次を主張します。
\[ \tilde\theta = E[\hat\theta \mid T] \quad\Longrightarrow\quad \mathrm{Var}(\tilde\theta) \le \mathrm{Var}(\hat\theta) \]
つまり、任意の不偏推定量 \(\hat\theta\) を十分統計量 \(T\) で条件付けて期待値を取ると、不偏性を保ったまま分散が決して増えない(多くの場合は減る)新しい推定量 \(\tilde\theta\) が得られます。条件付けによって「\(\theta\) に無関係なノイズ」が平均で均され、推定量が滑らかになるのがポイントです。
条件付ける相手は必ず十分統計量である必要があります。十分でない統計量で条件付けると \(E[\hat\theta\mid T]\) が \(\theta\) を含んでしまい、推定量として使えなくなります(統計量とは呼べなくなる)。十分性が「\(\theta\) に依存しない条件付き分布」を保証している点が本質です。
UMVUEへの道 ― レーマン–シェッフェの定理
ラオ–ブラックウェルは分散を「改善」しますが、それが「最良」だとまでは言いません。最後のひと押しが完備性とレーマン–シェッフェの定理です。完備十分統計量とは、十分性に加えて「\(E[g(T)]=0\) がすべての \(\theta\) で成り立つのは \(g\equiv 0\) のときだけ」という完備性を満たす統計量です。この完備性が、不偏推定量の一意性を保証します。
レーマン–シェッフェの定理は次のように橋渡しします。完備十分統計量 \(T\) に基づく不偏推定量が存在すれば、それは一様最小分散不偏推定量(UMVUE:Uniformly Minimum Variance Unbiased Estimator)、すなわちすべての \(\theta\) について分散が最小の不偏推定量になります。実務上の手順は「完備十分統計量 \(T\) を見つけ、\(T\) の関数で不偏になるものを作る」だけでUMVUEにたどり着けます。以下に各定理の役割を整理します。
達成例:\(X_1,\dots,X_n\sim Po(\lambda)\)(ポアソン分布)を考えます。1標本あたりの情報量は \(I_1(\lambda)=1/\lambda\) なので、CRLBは \(\dfrac{1}{nI_1(\lambda)}=\dfrac{\lambda}{n}\) です。一方、標本平均 \(\bar X\) は \(\lambda\) の不偏推定量で分散は \(\mathrm{Var}(\bar X)=\dfrac{\lambda}{n}\)。両者が完全に一致するため、\(\bar X\) はCRLBを達成する有効推定量であり、同時にUMVUEでもあります。正規分布 \(N(\mu,\sigma^2)\)(\(\sigma^2\) 既知)における \(\bar X\) も、\(\mathrm{Var}(\bar X)=\sigma^2/n\) がCRLBと一致し、同じく有効推定量です。
典型出題パターンと例題演習
準1級の「統計的推定」では、これまで整理した概念を計算で使わせる問題が頻出します。まず典型パターンを押さえましょう。
- 与えられた分布の最尤推定量(MLE)を、対数尤度 \(\ell(\theta)\) の微分=スコア方程式 \(S(\theta)=0\) から求める
- フィッシャー情報量 \(I(\theta)\) を計算し、CRLBを出してMLEの分散と比較する
- 因子分解定理(分解定理)を用いて十分統計量を示す
- 完備十分統計量からUMVUEを構成する
- 漸近分散 \(1/I(\theta)\) から標準誤差(SE)を求める
以下、本試験レベルの例題を3問、段階的な解答つきで解いていきます。
例題1:指数分布のMLEとCRLB
問題:\(X_1,\dots,X_n\) が独立に指数分布 \(f(x;\lambda)=\lambda e^{-\lambda x}\;(x>0)\) に従うとき、\(\lambda\) の最尤推定量を求めよ。さらにフィッシャー情報量とCRLBを計算し、MLEが下限を達成するか論じよ。
解答:対数尤度は
\[ \ell(\lambda)=\sum_{i=1}^{n}\bigl(\ln\lambda-\lambda x_i\bigr)=n\ln\lambda-\lambda\sum_{i=1}^{n}x_i \]
です。スコア \(S(\lambda)=\dfrac{d\ell}{d\lambda}=\dfrac{n}{\lambda}-\sum x_i\) を0とおくと、
\[ \frac{n}{\lambda}-\sum_{i=1}^{n}x_i=0 \;\Longrightarrow\; \hat\lambda=\frac{n}{\sum x_i}=\frac{1}{\bar X} \]
となり、MLEは標本平均の逆数です。次に情報量を求めます。\(\dfrac{d^2\ell}{d\lambda^2}=-\dfrac{n}{\lambda^2}\) なので、
\[ I(\lambda)=-E\!\left[\frac{d^2\ell}{d\lambda^2}\right]=\frac{n}{\lambda^2},\qquad \text{CRLB}=\frac{1}{I(\lambda)}=\frac{\lambda^2}{n} \]
と計算できます。したがってMLEの漸近分散は \(\lambda^2/n\) で、CRLBと一致します。よって \(\hat\lambda\) は漸近的に下限を達成する漸近有効な推定量です。
\(\hat\lambda=1/\bar X\) は \(\lambda\) の非線形関数なので、有限標本では厳密には不偏ではありません(実際 \(E[\hat\lambda]=\dfrac{n}{n-1}\lambda\) とわずかに上に偏る)。CRLBを「厳密に」達成するのではなく、\(n\to\infty\) で達成する「漸近有効」と表現するのが正確です。パラメータの取り方(\(\lambda\) か平均 \(1/\lambda\) か)で不偏性の議論が変わる点にも注意しましょう。
例題2:一様分布の十分統計量とUMVUE
問題:\(X_1,\dots,X_n\) が一様分布 \(U(0,\theta)\) に従うとき、因子分解定理により \(\theta\) の十分統計量が最大値 \(X_{(n)}=\max_i X_i\) であることを示せ。さらに \(X_{(n)}\) に基づく \(\theta\) の不偏推定量(UMVUE)を導け。
解答:まず同時密度を書きます。各 \(x_i\) が区間内にある条件は「すべての \(x_i\le\theta\)」=「\(x_{(n)}\le\theta\)」なので、
\[ f(\boldsymbol{x};\theta)=\prod_{i=1}^{n}\frac{1}{\theta}\mathbf{1}(0\le x_i\le\theta)=\underbrace{\frac{1}{\theta^n}\mathbf{1}(x_{(n)}\le\theta)}_{g(x_{(n)};\theta)}\cdot\underbrace{\mathbf{1}(x_{(1)}\ge 0)}_{h(\boldsymbol{x})} \]
と分解できます。密度が \(\theta\) を含む部分 \(g\) を通じてのみデータに依存し、その \(g\) が \(X_{(n)}\) だけの関数になっているので、因子分解定理より \(X_{(n)}\) は \(\theta\) の十分統計量です。
次に \(X_{(n)}\) の期待値を求めます。\(X_{(n)}\) の分布関数は \(F_{(n)}(t)=(t/\theta)^n\;(0\le t\le\theta)\)、密度は \(f_{(n)}(t)=\dfrac{n t^{n-1}}{\theta^n}\) なので、
\[ E[X_{(n)}]=\int_0^\theta t\cdot\frac{n t^{n-1}}{\theta^n}\,dt=\frac{n}{\theta^n}\cdot\frac{\theta^{n+1}}{n+1}=\frac{n}{n+1}\theta \]
です。これは \(\theta\) より小さく偏るので、係数で補正して
\[ \hat\theta_{\text{UMVUE}}=\frac{n+1}{n}X_{(n)} \]
とすれば \(E[\hat\theta_{\text{UMVUE}}]=\theta\) の不偏推定量になります。\(X_{(n)}\) は完備十分統計量なので、レーマン–シェッフェの定理よりこれがUMVUEです。
検算:\(n=1\) のとき \(\hat\theta=2X_{(1)}=2X_1\)。1点しかないので \(E[2X_1]=2\cdot\dfrac{\theta}{2}=\theta\) となり、確かに不偏です。
一様分布はサポート(定義域)の端がパラメータ \(\theta\) に依存するため、クラメール–ラオの正則条件を満たしません。したがってこの例ではCRLBを直接あてはめられず、MLE \(X_{(n)}\) の分散が \(1/I(\theta)\) を下回るように見える現象も起こり得ます。「端点がパラメータ依存=CRLB適用外」は準1級でも狙われる要注意ポイントです。
例題3:ポアソン分布のMLEと有効性
問題:\(X_1,\dots,X_n\sim Po(\lambda)\) について、\(\lambda\) の最尤推定量・その漸近分散・CRLBを求め、有効性を確認せよ。
解答:対数尤度は(定数項を除き)
\[ \ell(\lambda)=\sum_{i=1}^{n}\bigl(x_i\ln\lambda-\lambda\bigr)=\Bigl(\sum x_i\Bigr)\ln\lambda-n\lambda \]
です。スコア \(S(\lambda)=\dfrac{\sum x_i}{\lambda}-n=0\) より、
\[ \hat\lambda=\frac{\sum x_i}{n}=\bar X \]
すなわちMLEは標本平均です。情報量は \(\dfrac{d^2\ell}{d\lambda^2}=-\dfrac{\sum x_i}{\lambda^2}\) と \(E[\sum x_i]=n\lambda\) から、
\[ I(\lambda)=-E\!\left[\frac{d^2\ell}{d\lambda^2}\right]=\frac{n\lambda}{\lambda^2}=\frac{n}{\lambda},\qquad \text{CRLB}=\frac{\lambda}{n} \]
です。一方 \(\mathrm{Var}(\bar X)=\dfrac{\mathrm{Var}(X)}{n}=\dfrac{\lambda}{n}\)(ポアソンは平均=分散=\(\lambda\))なので、MLEの分散はCRLBとぴったり一致します。
結論・検算:有効性は \(\mathrm{eff}(\bar X)=\dfrac{\lambda/n}{\lambda/n}=1\)。よって \(\bar X\) はCRLBを達成する有効推定量であり、UMVUEでもあります。標準誤差は \(\mathrm{SE}(\hat\lambda)=\sqrt{\lambda/n}\) で、実務では \(\lambda\) を \(\hat\lambda=\bar X\) で置き換えて \(\sqrt{\bar X/n}\) と推定します。たとえば \(n=100\)、\(\bar X=4\) なら \(\mathrm{SE}=\sqrt{4/100}=0.2\) となり、\(\lambda\) の推定値4に対しての精度がこの一手で評価できます。
受験対策・実務でのポイント
準1級の統計的推定で得点するには、まず「解き方の型」を身につけることが近道です。最尤推定(データを最も生じやすくするパラメータを選ぶ推定法)を求める問題では、尤度関数をそのまま微分せず、対数をとった対数尤度を θ で微分してゼロと置くスコア方程式を立てるのが定石です。積が和に変わり計算が一気に楽になります。求めた値が本当に最大かどうかは2階微分の符号で確認します。
フィッシャー情報量(パラメータについてデータが持つ情報の量)は、対数尤度を θ で2階微分し、符号を反転させた期待値として求めます。1階微分(スコア関数)の分散として計算しても同じ値になるため、問題の形に応じて計算しやすい方を選ぶとよいでしょう。ここでつまずくと、後述のクラメール–ラオの不等式(不偏推定量の分散の下限を与える不等式)まで芋づる式に失点するため、確実に押さえたい計算です。
注意したいのが一様分布の扱いです。台の端がパラメータになる一様分布では対数尤度の微分が使えず、最大値(順序統計量)が最尤推定量になります。「微分が効かないパターン」を見分けられるかが、準1級の合否を分ける一つのポイントです。
実務との接続も明確です。製薬の統計解析で日常的に使うロジスティック回帰・Cox回帰・MMRM(反復測定の混合モデル)は、いずれも最尤推定(あるいは制限付き最尤推定)でパラメータを推定します。そして出力される標準誤差や信頼区間は、フィッシャー情報量の逆行列を土台にしています。試験で学ぶ理論が、解析ソフトの出力を正しく読むための足場になるのです。
最尤推定は対数尤度→スコア方程式、情報量は2階微分の期待値、一様分布は順序統計量、という型を先に固めるのが得点への最短ルートです。実務では、この最尤推定とフィッシャー情報量こそがロジスティック回帰・Cox回帰・MMRMの推定値と標準誤差・信頼区間を支える中核であり、試験対策がそのまま解析結果を正しく読み解く力につながります。
この記事をより深く理解するための参考書籍






関連記事・次のステップ
統計的推定の理解を確かなものにするには、周辺分野もあわせて学ぶのが効果的です。まずは全体像を統計検定準1級 攻略ガイド(出題範囲・勉強法)で押さえたうえで、本記事の前提となる点推定値の基礎から学ぶ:推定量の性質とその意義に戻ると、不偏性や一致性の理解がより深まります。
推定のもう一つの柱である区間推定については、区間推定入門:数式と図解で理解する信頼区間の世界で信頼区間の考え方を図解とともに確認できます。さらに準1級の他分野に進むなら、最尤推定が実際に使われる統計検定準1級「回帰分析」攻略や、推定の別の枠組みを扱う統計検定準1級「ベイズ統計」攻略へと学習を広げていくのがおすすめです。
まとめ
統計的推定は、推定量に求められる性質(不偏性・一致性・有効性・十分性)を出発点に、最尤推定でパラメータを求め、フィッシャー情報量とクラメール–ラオの不等式で推定精度の限界を評価し、十分統計量とUMVUEで最良の推定量を突き止める、という一本の流れで理解すると見通しが良くなります。準1級では、対数尤度の微分・情報量の期待値計算・一様分布の順序統計量といった典型パターンを型として身につけておくことが、そのまま得点力に直結します。
そしてこの理論は試験だけのものではありません。最尤推定とフィッシャー情報量は、ロジスティック回帰やCox回帰、MMRMといった製薬実務の主力モデルにおける推定値と標準誤差・信頼区間の土台であり、推定の理屈を理解していることが解析結果を正しく読み解く力になります。まずは本記事の例題3問を自力で解き直し、続けて統計検定準1級 攻略ガイドや点推定値の基礎から学ぶ記事、区間推定入門で学習を積み重ねていただければと思います。