外部対照群の統計手法 (2/2) ― 傾向スコアマッチング・MAIC・ベイズ動的借用 ―

- 外部対照群を活かす3つの統計手法(傾向スコア/MAIC/ベイズ動的借用)の使い分け
- MAIC(Matching-Adjusted Indirect Comparison)のR実装と注意点
- ベイズ動的借用(Power Prior / Commensurate Prior / Robust MAP Prior)の実装の勘所
- 手法選択フローチャートと外部対照群活用時の落とし穴
はじめに ― 前編の振り返りと本記事のスコープ
前編外部対照群(External Control Arm)とは ― FDA・PMDAの規制動向と臨床試験での活用 (1/2)では、希少疾患・オンコロジー領域での外部対照群の必要性、FDA・PMDAのガイダンス、RWD(Real-World Data)やヒストリカルコントロールの選定論点を整理しました。
後編となる本記事では、議論を一歩進めて「では実務でどう統計解析するのか」に踏み込みます。外部対照群を用いた解析で押さえておきたい代表的な3手法は次のとおりです。
- 傾向スコアマッチング/IPW:試験群と外部対照の共変量バイアスを除去する標準的アプローチ
- MAIC:個別データがない比較対象に対し、集約統計量に重みを合わせる間接比較手法
- ベイズ動的借用:ヒストリカル情報を「事前分布」として柔軟に組み込む枠組み
それぞれの手法は得意な状況・前提が異なるため、選択フローと落とし穴も含めて解説していきます。
傾向スコアマッチングの外部対照群への適用
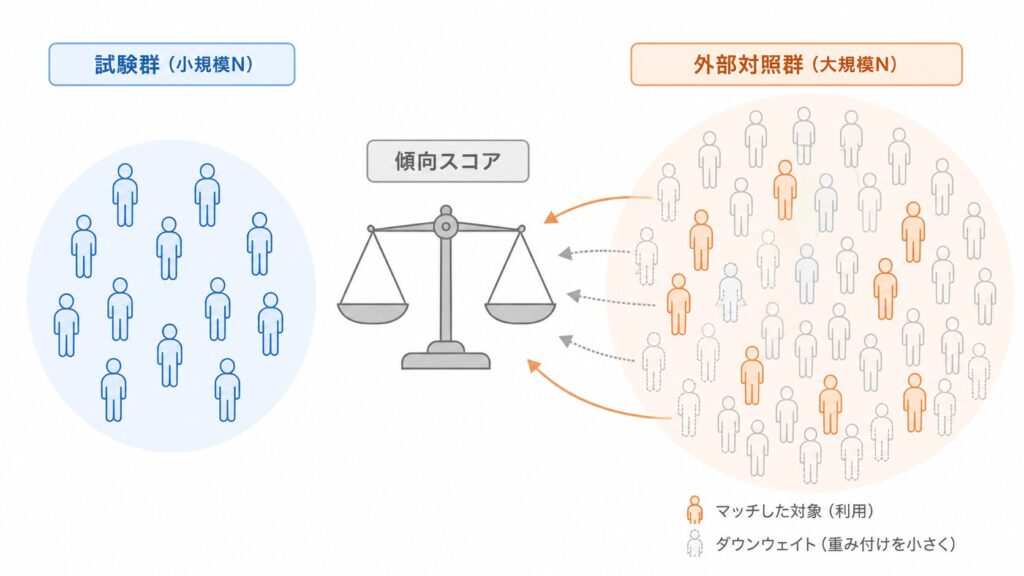
なぜ外部対照群に傾向スコアが必要か
試験群(プロトコル選択基準を満たした被験者)と外部対照群(RWDやヒストリカルコホート)では、年齢分布・PS(Performance Status)・併用薬・診断時期などの患者背景が大きく異なるのが通常です。何もせずに群間比較すれば、治療効果と背景差が交絡し、推定値はバイアスを含みます。
そこで、共変量から治療割り付け確率(傾向スコア)を推定し、それに基づいて両群のバランスを揃える前処理を行います。
マッチングか重み付け(IPW)か
- マッチング:1対1や1対kで対応付けを行うため直感的に理解しやすい一方、対応が取れない症例は除外され、解析サンプルが縮小します。外部対照プールが試験群より十分大規模で、kを大きく取れる状況で有効です。
- IPW(逆確率重み付け):全例を保持できる利点がありますが、極端な重みが分散を膨らませやすく、trimmingやstabilized weightの併用が実務上ほぼ必須となります。
規制当局への申請事例を眺めると、外部対照群文脈ではサンプルを温存できるIPWの採用例が多い傾向にあります。
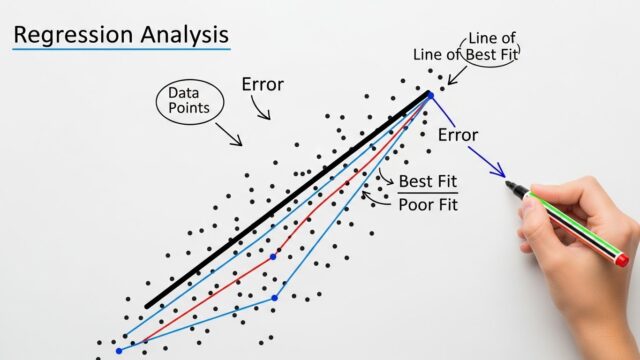
下図のように、試験群と外部対照のバランス調整こそが傾向スコアの主たる役割です。
R実装のミニマム例
MatchIt パッケージで最近傍マッチングを行う最小コードを示します。
library(MatchIt)
# trial_flag: 1=試験群, 0=外部対照群
m.out <- matchit(trial_flag ~ age + sex + ps + prior_tx,
data = df, method = "nearest", ratio = 1)
summary(m.out)$nn出力イメージ(抜粋):
Control Treated
All (ESS) 850 120
All 850 120
Matched 120 120
Unmatched 730 0解釈:外部対照850例から試験群120例にマッチする120例が選ばれ、残り730例は解析から除外されます。summary(m.out) の標準化平均差(SMD)が0.1未満になっているかでバランスを確認するのが定石です。
詳細は既存記事へ
傾向スコア自体の理論や実装の詳細は、本ブログ内に独立した解説記事があります。本記事では外部対照群文脈に特有の論点に絞り、基礎は以下を参照ください。
関連記事
MAIC(Matching-Adjusted Indirect Comparison)
MAICとは何か ― 単群試験と外部比較の橋渡し
MAIC(Matching-Adjusted Indirect Comparison)は、自社治験で個別患者データ(IPD: Individual Patient Data)が手元にあるものの、比較相手となる外部試験は論文やCSRに掲載された集計データ(AgD: Aggregate Data)しか得られない、という状況で用いられる重み付け手法です。希少疾患領域・腫瘍領域の単群試験、および HTA(Health Technology Assessment)申請における間接比較で広く活用されています。
核となる考え方はシンプルで、「集計データ側の共変量分布に合わせて、IPD側の患者を再重み付けする」というものです。傾向スコアマッチングが「両側のIPDから類似ペアを選ぶ」のに対し、MAICは「片側のIPDに重みを付けて、もう片側の集計値に揃える」点が決定的に異なります。
数式の概要
患者 \( i \) の重み \( w_i \) は、IPD側の共変量加重平均が AgD側の報告平均に一致するよう、エントロピー最大化(method of moments)で求めます。形式的には次の制約付き最適化となります。
\[ w_i = \exp(\alpha^\top X_i),\quad \text{s.t.}\quad \sum_i w_i X_i \big/ \sum_i w_i = \bar X^{\text{AgD}} \]
ここで \( X_i \) は中心化済みの共変量ベクトル、\( \alpha \) はラグランジュ乗数です。得られた「重み付きIPD」のアウトカム要約値を AgD と比較することで、共変量分布を揃えた上での間接比較が可能になります。実務上は、検出力低下を測る指標として有効標本サイズ \( \text{ESS} = (\sum w_i)^2 / \sum w_i^2 \) を必ず確認します。
R実装ミニマム例
maicChecks パッケージも便利ですが、ここでは依存が少なく挙動が見えやすい自前 optim 版を示します。IPD(age, sex)を AgD の mean_age=65, prop_male=0.6 に合わせる例です。
set.seed(1)
ipd <- data.frame(age = rnorm(200, 60, 10),
male = rbinom(200, 1, 0.5))
target <- c(age = 65, male = 0.6)
X <- as.matrix(sweep(ipd, 2, target)) # 中心化
obj <- function(a) sum(exp(X %*% a)) # エントロピー目的関数
fit <- optim(rep(0, 2), obj, method = "BFGS")
w <- as.vector(exp(X %*% fit$par))
ess <- sum(w)^2 / sum(w^2)
cat("ESS =", round(ess, 1), "/ N =", nrow(ipd))
出力例は ESS = 142.3 / N = 200 となり、200例の IPD が実質142例相当まで減ったことを意味します。重みヒストグラムは右裾を引き、最大重みは平均の3〜5倍程度に収まっていれば概ね健全です。ESSが元の50%を切るような場合は、共変量分布の重なりが乏しく、結果の不確実性が大きいと解釈すべきです。
MAICの限界と注意点
- ESS低下リスク:IPDとAgDの共変量分布の重なりが小さいと、少数の患者に重みが集中しESSが急減します。
- 観測されない交絡:MAICは調整変数として AgD側で報告された共変量しか扱えず、未測定交絡は除去できません。
- アンカー型 vs 非アンカー型:両試験に共通の対照群(プラセボ等)があるアンカー型が推奨されます。共通対照のない非アンカー型は「絶対アウトカムが共変量で完全に説明される」という強い仮定が必要で、信頼性は大きく下がります。
方法論の標準的なガイダンスとしては、NICE DSU Technical Support Document 18(Phillippo et al., 2016)が事実上のリファレンスとなっており、HTA文脈での MAIC・STC(Simulated Treatment Comparison)の使い分けや感度分析の最低要件を確認しておくことを強く推奨します。
外部対照群の統計手法は、ベイズ統計と傾向スコア分析の応用問題でもあります。基礎から系統的に学びたい方は、記事末尾で紹介している書籍3冊(ベイズ・傾向スコア・臨床試験統計)が体系化に役立ちます。
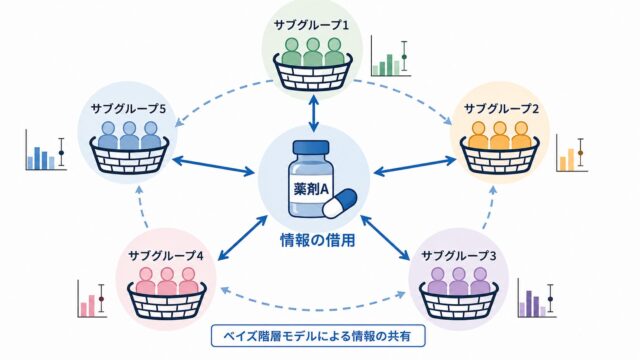
ベイズ動的借用 ― 過去データを「程度を制御して」借りる
傾向スコアマッチングや MAIC が「個体レベル・集計レベルで対照群を作り直す」アプローチであるのに対し、ベイズ動的借用(dynamic borrowing)は「過去試験データを事前分布として使い、借用の程度をデータに応じて制御する」発想です。希少疾患・小児外挿・PoC 試験など、現行試験の症例数を確保しにくい状況で特に有用です。
なぜ動的(dynamic)か
過去試験データ(historical control)を全部借りる(fully borrowing)と、もし過去と現行で患者背景や標準治療が乖離していた場合に大きなバイアスが生じます。一方、全く借りない(no borrowing)と、せっかく蓄積された情報を捨てて統計的効率を犠牲にすることになります。
動的借用は、「現行データと整合的なら多めに、整合的でないなら少なく借りる」という自動調整を行うアプローチです。FDA のドラフトガイダンス「Considerations for the Design and Conduct of Externally Controlled Trials for Drug and Biological Products」(2023年2月公表、2026年5月時点でDraftのまま)でも、外部対照を用いる際の柔軟な情報借用の考え方として言及されています。
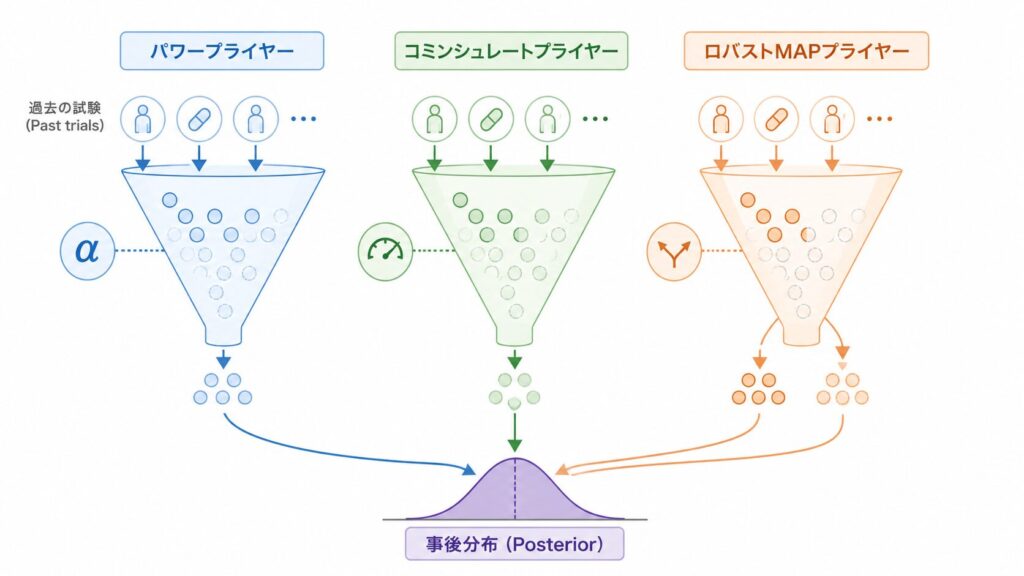
Power Prior
最も直感的な方法が Power Prior です。過去データ \( D_0 \) の尤度を \( a_0 \in [0,1] \) 乗してプライアに使います。
\[ \pi(\theta \mid D_0, a_0) \propto L(\theta \mid D_0)^{a_0} \cdot \pi_0(\theta) \]
\( a_0 = 0 \) なら借りない、\( a_0 = 1 \) なら全部借りる、という解釈ができ、規制当局にも説明しやすいのが利点です。\( a_0 \) を固定する方法と、\( a_0 \) 自体にベータ分布などの事前分布を置く modified Power Prior の2パターンがあります。後者はデータから借用度合いを推定できる反面、計算が重くなります。
Commensurate Prior
Commensurate Prior は、過去パラメータ \( \theta_0 \) と現行パラメータ \( \theta \) の差を、適合度(commensurability)パラメータ \( \tau \) で制御する方法です。
\[ \theta \mid \theta_0, \tau \sim \mathcal{N}(\theta_0,\, 1/\tau) \]
\( \tau \) が大きい(精度が高い)ほど過去データに近く、小さいほど独立に近い、という直感的な構造です。\( \tau \) にも事前分布を置くことで、データから借用度合いを駆動的に決められる点が魅力です。
Robust MAP Prior
Meta-Analytic-Predictive (MAP) prior は、複数の過去試験のメタ解析から予測分布を作り、それを現行試験の事前分布として使う方法です。Robust MAP はこの MAP prior に弱情報事前分布を混合(mixture)し、現行データが過去と大きく乖離した場合のロバスト性を確保します。
製薬業界では小児外挿・希少疾患・PoC 試験などで標準的に使われており、Novartis が開発した R パッケージ RBesT(CRAN 公開)が事実上のデファクトスタンダードです。
R実装:RBesT で Robust MAP Prior
過去5試験の対照群レスポンス率データから MAP prior を作成し、ロバスト化したうえで現行試験データと組み合わせる典型ワークフローを示します。
library(RBesT)
# 過去5試験の対照群(レスポンダー数 / 症例数)
hist <- data.frame(
study = paste0("S", 1:5),
r = c(12, 18, 9, 15, 11),
n = c(40, 50, 30, 45, 35)
)
# MAP prior を gMAP で推定
map_mc <- gMAP(cbind(r, n - r) ~ 1 | study,
data = hist, family = binomial,
tau.dist = "HalfNormal", tau.prior = 1,
beta.prior = 2)
# 混合正規で近似 → 弱情報を20%混合してロバスト化
map_mix <- automixfit(map_mc)
rob_map <- robustify(map_mix, weight = 0.2, mean = 0.5)
# 現行試験:60例中22例レスポンダー → 事後分布
post <- postmix(rob_map, r = 22, n = 60)
summary(post)
出力では事後平均と 95% 信用区間が得られます。例えば事後平均 0.34、95%CrI [0.26, 0.43] のように表示され、過去データから情報を借りつつも現行データに引っ張られた推定値であることが確認できます。weight = 0.2 の混合比は感度分析の対象とすべきパラメータです。
動的借用の注意点
- Effective Sample Size (ESS) の事前確認:MAP prior が過去試験何例分に相当するかを
ess()関数で確認し、過大借用になっていないか必ずチェックします - SAP への事前明記:規制対応では、借用方法・パラメータ・感度分析計画が統計解析計画書(SAP)に事前に記載されていることが必須です
- 感度分析の実施:複数の prior 設定(混合比 0.1〜0.5、tau の事前分布など)を比較し、結論の頑健性を示すのが定石です
以下の図のように、Power Prior・Commensurate Prior・Robust MAP Prior の3手法は「どれだけ・どう借りるか」のメカニズムが異なります。実務では試験デザイン・利用可能な過去データの構造・規制当局との合意状況に応じて使い分けることになります。
手法選び方フローチャート
外部対照群の活用は「手元にあるデータの形」と「借りたい過去データの数」で手法が決まります。以下のフローチャートに沿って確認してみましょう。
- Q1:外部対照側に個別患者データ(IPD)があるか?
→ Yes:傾向スコアマッチング/IPWを選択。共変量バランスを直接調整できます。
→ No:Q2へ進む。 - Q2:過去試験の集計データ(要約統計量)だけがあるか?
→ Yes:MAICを選択。特に単群試験 vs 文献データの間接比較で第一候補となります。
→ No:Q3へ進む。 - Q3:複数の過去試験があり、現行試験と類似集団か?
→ Yes:ベイズ動的借用を選択。Robust MAP Prior が第一候補で、集団間の異質性を確率的に反映できます。
外部対照群の活用は「データの形(IPD/集計)×借りる過去データの数」で手法が決まります。事前にSAP(統計解析計画書)で手法とプライア設定を確定しておくのが規制対応の鉄則です。
まとめと次のステップ
本シリーズで扱った3手法の特徴を整理します。
- 傾向スコアマッチング/IPW:IPDがある場合の標準解。共変量バランスを可視化しやすい。
- MAIC:集計データしかない間接比較で必須。重み発散と有効サンプルサイズ低下に注意。
- ベイズ動的借用:複数過去試験のエビデンスを動的に統合。Robust MAP Priorで頑健性を担保。
実務上のポイントは3つです。第一に、主解析だけでなく感度分析(プライアの混合比、キャリパー幅など)を必ず設計すること。第二に、SAPで手法とパラメータを事前規定し、データ閲覧後の変更を避けること。第三に、PMDA・FDAとの事前協議で手法の妥当性を擦り合わせること。これらを徹底すれば、外部対照群は希少疾患・小児領域で強力な武器となります。
これで前編・後編のシリーズが完結しました。次回は「外部対照群を用いた試験デザインの実例 ― 希少疾患領域での申請事例分析」を予定しています。ベイズ動的借用の具体的な症例適用にも触れる予定ですので、ぜひお楽しみに。
関連記事・次のステップ