統計検定準1級「ベイズ統計」攻略 ― 事前分布・MCMCの典型出題パターン

・統計検定準1級におけるベイズ統計の出題範囲と頻出パターン
・事前分布の3分類と共役事前分布の典型3パターン(Beta-二項/Gamma-ポアソン/正規-正規)
・損失関数と最適点推定量の対応、信用区間(HDI/等裾)の使い分け
・MCMC(メトロポリス・ヘイスティングス法/ギブスサンプリング)の原理と収束診断
・過去問風の典型出題3問とその解法のコツ
はじめに
統計検定準1級の出題範囲のなかで、ベイズ統計は「概念理解」と「計算スキル」の両方が同時に問われる総合的なテーマです。事前分布・事後分布・共役事前分布・MAP推定・信用区間・MCMC ── キーワードを並べただけでも幅広く、頻度論一辺倒で勉強してきた受験者にとっては最初の壁になりがちな分野です。
ところが出題パターン自体はかなり限定的で、典型問題のテンプレートを押さえれば、ベイズ統計は 準1級の安定した得点源 に変えられます。本記事は統計検定準1級「時系列解析」攻略に続く準1級攻略シリーズの第2弾として、ベイズ統計の典型出題パターンを「事前分布・事後分布の更新」「点推定と信用区間」「MCMCの基礎」の3軸で体系的に解説します。
ベイズ統計が準1級で問われる理由
準1級の公式範囲表を開くと、「ベイズ法」は確率モデルや多変量解析と並んで独立した一節を占めており、近年は毎回1〜2問が安定して出題される定番テーマになっています。
準1級のベイズ問題は「公式の暗記」より「事前×尤度=事後」の流れを手で追えるかが勝負です。理屈さえ通れば、選択肢問題は消去法でほぼ確実に絞り込めます。
出題形式と配点感覚
準1級はPBT(紙ベース)形式が中心で、ベイズ統計は 多枝選択の小問 と、まれに 部分記述問題 として登場します。小問では「事後分布の形を選べ」「共役事前分布として正しいものはどれか」といったストレートな問い方が多く、計算量は決して多くありません。一方、論述パートに食い込んだ年度では、ベータ−二項モデルの事後平均やMAP推定値を導出させる出題例もあり、配点が高くなる傾向にあります。実際に過去問を解いてみた印象では、ベイズの大問が出た年は ここを落とすと合格ラインが一気に遠のく ため、捨て分野にするのは得策ではありません。
頻出キーワードと学習の優先順位
押さえるべきキーワードは、事前分布/事後分布/共役事前分布/MAP推定/信用区間/MCMC の6つに集約されます。学習の順番としては、まず 事前→事後の更新計算 を手で書けるようにし、次に 共役分布の対応関係(ベータ−二項、ガンマ−ポアソン、正規−正規)を暗記、そのうえで 信用区間の解釈、最後に MCMCの概念問題 という流れが効率的です。
\[ p(\theta \mid x) \propto p(x \mid \theta)\, p(\theta) \]
この一本の式さえ腹落ちすれば、出題の8割は地続きで解けます。MCMCは計算ではなく「なぜサンプリングで事後分布が近似できるのか」という概念理解が問われるので、ギブスサンプラーとメトロポリス・ヘイスティングス法の違いを言語化できれば十分です。
なぜ今ベイズを学ぶのか
試験対策にとどまらず、ベイズ統計はいま実務で最も需要が伸びている分野です。医薬分野では FDAが2026年に改訂したベイズ流臨床試験ガイダンス により、希少疾患・小児領域での事前情報活用が一気に現実的になりました。機械学習側でも、ベイズ最適化や変分推論はMLOpsの定番ツールになっています。準1級の勉強をきっかけにベイズの土台を作っておくと、合格後のキャリアにもそのまま接続できる ── これが、本シリーズで腰を据えてベイズを扱う最大の理由です。
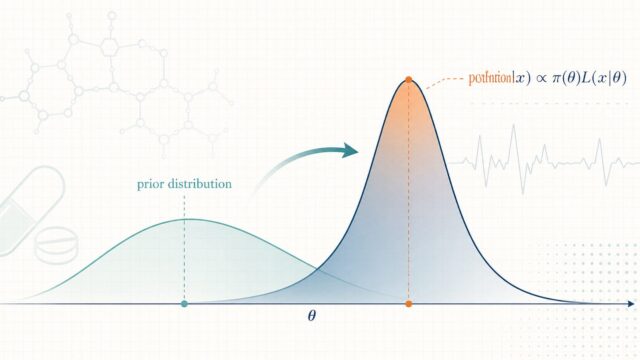
事前分布の選び方と共役事前分布
ベイズ統計の出題で最初の壁となるのが「事前分布をどう選ぶか」と「事後分布をどう計算するか」です。準1級では、ここを理解していれば即答できる典型問題が頻出します。本章では分類と共役関係を整理し、計算が一発で終わる手順を身につけましょう。
ベイズの定理の復習と事前分布の3分類
ベイズ統計の基本式は、観測データ \(x\) とパラメータ \(\theta\) について次のように書けます。
\[ p(\theta \mid x) \propto p(x \mid \theta)\, p(\theta) \]
つまり 事後 ∝ 尤度 × 事前 です。準1級ではこの「比例関係」だけで答えが決まる問題が多く、規格化定数を計算する必要はほとんどありません。事前分布は大きく次の3つに分類されます。
- 無情報事前分布:事前知識がない状況で用いる分布。一様分布や Jeffreys 事前分布が代表例
- 主観的事前分布:専門家の知見や過去データから決める分布。製薬の臨床試験などで使われる
- 共役事前分布:尤度と組み合わせると事後分布が事前と同じ族になる分布。計算が閉形式で済むため出題の中心
共役事前分布の典型3パターン
準1級で覚えておくべき共役の組み合わせは、次の3つに集約されます。
| 尤度 | 共役事前分布 | 事後分布 |
|---|---|---|
| ベルヌーイ/二項 | Beta(α, β) | Beta(α+k, β+n−k) |
| ポアソン | Gamma(α, β) | Gamma(α+Σx, β+n) |
| 正規(分散 \(\sigma^2\) 既知) | Normal(μ₀, τ₀²) | Normal(下記更新式) |
正規 ─ 正規モデルの平均の更新式は次のとおりです。
\[ \mu_{\text{post}} = \frac{\frac{\mu_0}{\tau_0^2} + \frac{n\bar{x}}{\sigma^2}}{\frac{1}{\tau_0^2} + \frac{n}{\sigma^2}}, \quad \frac{1}{\tau_{\text{post}}^2} = \frac{1}{\tau_0^2} + \frac{n}{\sigma^2} \]
分散ではなく 精度(precision = 1/分散)が足し算で増えていく と覚えると忘れません。
解答:表の更新式に当てはめるだけです。
\(\alpha_{\text{post}} = \alpha + k = 2 + 7 = 9\)
\(\beta_{\text{post}} = \beta + (n – k) = 2 + 3 = 5\)
よって事後分布は Beta(9, 5) となります。
無情報事前分布と Jeffreys 事前分布の違い
「情報がない」事前分布にも複数の流儀があります。二項分布の成功確率 \(\theta\) を例にすると、
- 一様事前分布:\(\text{Beta}(1, 1)\)。\(\theta\) の値に依存せず一定
- Jeffreys 事前分布:\(p(\theta) \propto \sqrt{I(\theta)}\) で定義され、二項では \(\text{Beta}(1/2, 1/2)\) になる
Jeffreys 事前分布の最大の特長は パラメータの変換に対して不変 である点です。たとえば \(\theta\) を \(\log \theta/(1-\theta)\) に変換しても、Jeffreys 事前分布なら同じ「無情報」を表現できます。一様分布はこの不変性をもたないため、変換するだけで「情報を持った」事前になってしまいます。準1級では「Jeffreys = 変換不変・フィッシャー情報量の平方根に比例」という対応を押さえておけば十分です。
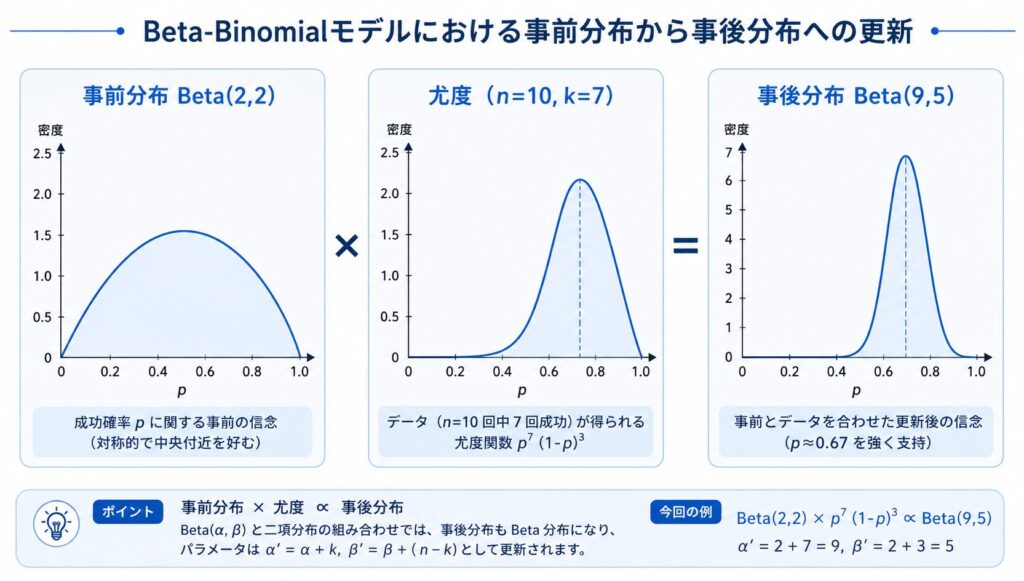
ベイズ推定の点推定・区間推定
事後分布が得られた後、それをどう要約するかが実務上の最後の関門です。準1級では「点推定(点で代表させる)」と「区間推定(信用区間)」の両方が出題され、損失関数との対応や信頼区間との哲学的違いが問われます。
損失関数と最適な点推定量
ベイズ推定では、推定量 \(\hat{\theta}\) を選ぶ基準として「事後期待損失」を最小化する考え方を採ります。損失関数 \(L(\theta, \hat{\theta})\) の取り方によって、最適な点推定量が変わるのがポイントです。
\[ \hat{\theta}^{*} = \arg\min_{\hat{\theta}} \; E_{\theta \mid x}\bigl[L(\theta, \hat{\theta})\bigr] \]
代表的な3つの損失関数と対応する最適推定量を整理すると、次の表のようになります。
| 損失関数 | 数式 | 最適な点推定量 |
|---|---|---|
| 二乗誤差損失 | \((\theta – \hat{\theta})^2\) | 事後平均 |
| 絶対誤差損失 | \(|\theta – \hat{\theta}|\) | 事後中央値 |
| 0-1損失 | \(\mathbb{1}(\theta \neq \hat{\theta})\) | MAP推定値(事後モード) |
「事後平均は二乗誤差、事後中央値は絶対誤差、MAPは0-1損失」という対応はそのまま出題されるので、丸暗記しておきましょう。
信用区間 ─ Equal-tailed と HDI
ベイズ流の区間推定が信用区間(Credible Interval)です。「真の \(\theta\) がこの区間に入る確率が \(1-\alpha\)」とパラメータに対する確率として直接解釈できる点が、頻度論の信頼区間との決定的な違いです。信頼区間は「同じ手続きを繰り返したとき \(1-\alpha\) の割合で真値を含む」という長期頻度の解釈しか持たない点に注意しましょう。準1級で押さえるべき信用区間は2種類です。
- Equal-tailed interval:事後分布の \(\alpha/2\) 分位点と \(1-\alpha/2\) 分位点で挟む区間。計算が簡単で対称分布に向く
- HDI(Highest Density Interval):事後密度が高い領域から順に確率 \(1-\alpha\) になるまで集めた区間。区間幅が最小になる
左右に歪んだ事後分布(Beta分布や対数正規分布など)では、Equal-tailedだと密度の低い裾を含んでしまうため、HDIが好まれます。一方、対称な事後分布なら両者は一致します。
解答:Beta分布 \(\mathrm{Beta}(\alpha, \beta)\)(\(\alpha, \beta > 1\))のモードと平均の公式から、
\[ \mathrm{MAP} = \frac{\alpha – 1}{\alpha + \beta – 2} = \frac{9-1}{9+5-2} = \frac{8}{12} \approx 0.667 \]
\[ E[\theta \mid x] = \frac{\alpha}{\alpha + \beta} = \frac{9}{9+5} \approx 0.643 \]
左に歪んだ分布のためMAPの方がやや大きくなります。
MCMCの基礎 ─ マルコフ連鎖モンテカルロ法
ベイズ統計の最大の壁は、事後分布 \(\pi(\theta \mid D) \propto \pi(D \mid \theta)\pi(\theta)\) の正規化定数を解析的に計算できないことです。共役事前分布が使えるケースでは事後分布が閉じた形で得られますが、現実のモデル(階層モデル・非線形モデル・多パラメータモデル)では事後分布が高次元積分を含み、解析解は得られません。この困難を回避するため、事後分布から直接サンプルを生成し、その経験分布で推論を行うのがMCMC(マルコフ連鎖モンテカルロ法)です。
マルコフ連鎖の3性質と定常分布
MCMCの理論的基盤は、適切に設計したマルコフ連鎖が定常分布として目的の事後分布 \(\pi\) を持つように仕向けることにあります。そのために必要な3条件が以下です。
- 既約性(irreducibility):任意の状態から任意の状態へ有限ステップで到達可能
- 非周期性(aperiodicity):特定の周期で同じ状態に戻る構造を持たない
- 正再帰性(positive recurrence):有限の期待時間で再訪する
これら3条件を満たす連鎖は、初期値によらず一意の定常分布へ収束します(エルゴード定理)。さらに、サンプラーが目的分布 \(\pi\) を定常分布に持つことを保証する十分条件が詳細釣り合い条件(detailed balance)です。
\[ \pi(x)\, P(x \to y) = \pi(y)\, P(y \to x) \]
この式は「\(x\) から \(y\) への確率流」と「逆向きの流れ」が釣り合っていることを意味し、これが成り立てば \(\pi\) は不変分布になります。
メトロポリス・ヘイスティングス法
最も汎用的なMCMCアルゴリズムがメトロポリス・ヘイスティングス法(MH法)です。提案分布 \(q(y \mid x)\) から候補点 \(y\) を生成し、以下の受理確率で採否を決めます。
\[ \alpha(x, y) = \min\left\{1,\ \frac{\pi(y)\, q(x \mid y)}{\pi(x)\, q(y \mid x)}\right\} \]
正規化定数が分子分母で打ち消されるため、規格化されていない事後密度さえあれば実装可能です。
- 初期値 \(x_0\) を設定する
- 提案分布 \(q(y \mid x_t)\) から候補 \(y\) をサンプル
- 受理確率 \(\alpha = \min\{1, \pi(y)q(x_t \mid y) / \pi(x_t)q(y \mid x_t)\}\) を計算
- \(u \sim U(0,1)\) を生成し、\(u < \alpha\) なら \(x_{t+1}=y\)、そうでなければ \(x_{t+1}=x_t\)
- 2〜4 を十分回数繰り返す
ギブスサンプリングとMH法の比較
ギブスサンプリングは多変量分布に対し、各変数の条件付き分布から順番にサンプルを引く手法で、受理確率は常に1(必ず採用)です。条件付き分布が既知の形で書ける階層モデルで強力に機能します。
| 項目 | メトロポリス・ヘイスティングス法 | ギブスサンプリング |
|---|---|---|
| 必要な分布 | 事後分布(非正規化でOK) | 各変数の完全条件付き分布 |
| 受理確率 | \(\alpha < 1\) のことが多い | 常に1 |
| 提案分布の調整 | 必要(ステップ幅のチューニング) | 不要 |
| 適用範囲 | 汎用的 | 条件付き分布が既知のモデル |
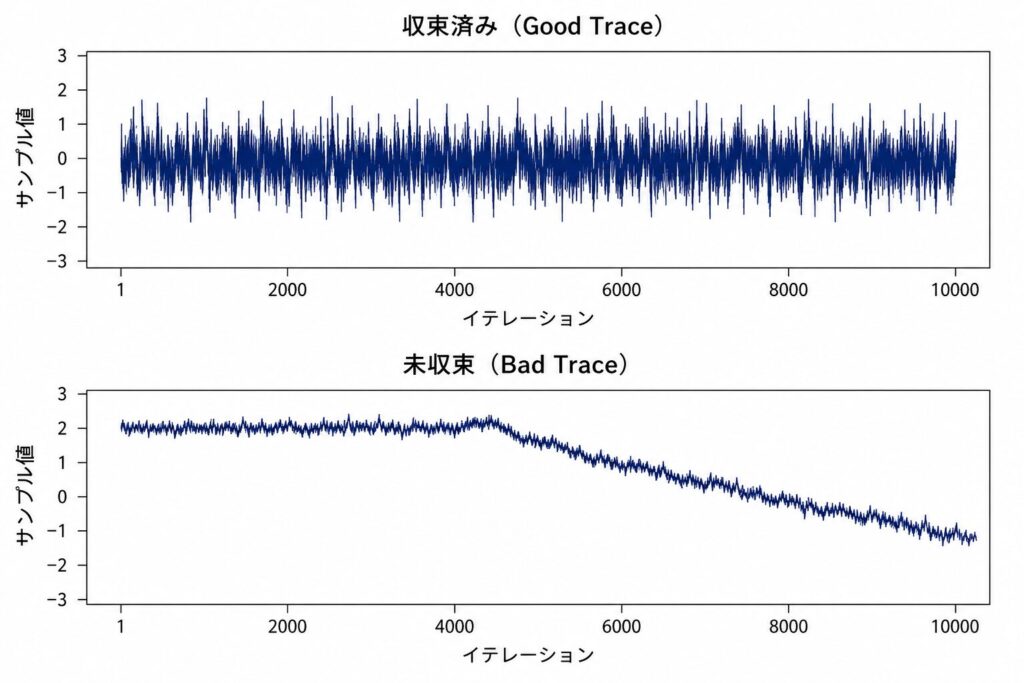
収束診断とサンプル処理
MCMCは初期値の影響を受けるため、得られたサンプルが本当に事後分布を代表しているか診断が必須です。
- トレースプロット:横軸イテレーション・縦軸サンプル値。定常状態では「毛虫が這うような」一様な揺らぎになる
- Gelman-Rubin統計量 \(\hat{R}\):複数の独立鎖の鎖間分散と鎖内分散の比。1.1未満で許容、1.01未満が望ましい
- バーンイン:初期の過渡期サンプル(数百〜数千)を捨てる
- thinning(間引き):自己相関を減らすため数ステップに1サンプルだけ採用
Rでのメトロポリス法最小実装
標準正規分布 \(N(0,1)\) からMH法でサンプリングする最小例を示します。
# メトロポリス法でN(0,1)からサンプリング
set.seed(123)
n <- 10000 # サンプル数
x <- numeric(n) # サンプル格納用
x[1] <- 0 # 初期値
for (t in 2:n) {
y <- x[t-1] + rnorm(1, 0, 1) # 提案:ランダムウォーク
alpha <- min(1, dnorm(y) / dnorm(x[t-1])) # 受理確率
x[t] <- if (runif(1) < alpha) y else x[t-1]
}
plot(x, type = "l", main = "トレースプロット") # 収束確認
わずか10行で、解析的にサンプル可能な分布も含め任意の目的分布から擬似サンプルを得られるのがMCMCの威力です。
典型出題パターンで実戦演習
ここまで学んだ事前分布・事後分布・MCMCの知識を、過去問風の3問で確認しましょう。手を動かして解くことで、出題パターンと解答プロセスが自然に身につきます。
あるコインを10回投げたところ、表が7回出た。表が出る確率 \(p\) の事前分布として \(\mathrm{Beta}(2, 2)\) を仮定したとき、事後分布は何になるか。
二項尤度は \(\mathcal{L}(p) \propto p^{k}(1-p)^{n-k}\)、ベータ事前分布は \(\pi(p) \propto p^{\alpha-1}(1-p)^{\beta-1}\) なので、事後分布は次のように更新されます。
\[ p \mid \text{データ} \sim \mathrm{Beta}(\alpha+k,\ \beta+n-k) = \mathrm{Beta}(2+7,\ 2+3) = \mathrm{Beta}(9,\ 5) \]
共役事前分布の威力は「パラメータの足し算だけで事後分布が得られる」点にあります。
問題①で得られた事後分布 \(\mathrm{Beta}(9, 5)\) について、事後平均と95%等裾信用区間を求めよ。
ベータ分布の平均は \(\alpha/(\alpha+\beta)\) なので、
\[ E[p \mid \text{データ}] = \frac{9}{9+5} = \frac{9}{14} \approx 0.643 \]
95%等裾信用区間はベータ分布の0.025・0.975分位点から求めます。Rで以下のように計算できます。
qbeta(c(0.025, 0.975), 9, 5)
# [1] 0.3902984 0.8631797
したがって95%信用区間は概ね \([0.391,\ 0.864]\) です。「真の \(p\) が95%の確率でこの区間に入る」とそのまま解釈できる点が、頻度論の信頼区間との大きな違いです。
メトロポリス・ヘイスティングス法で対称な提案分布 \(q(y \mid x) = q(x \mid y)\) を用いる。現在の状態 \(x = 1.0\) から候補 \(y = 2.0\) が提案され、目標分布の比が \(\pi(y)/\pi(x) = 0.4\) のとき、受理確率 \(\alpha\) はいくらか。
MH法の受理確率は次式で与えられます。
\[ \alpha = \min\!\left\{1,\ \frac{\pi(y)\,q(x \mid y)}{\pi(x)\,q(y \mid x)}\right\} \]
対称提案分布では \(q(x \mid y)/q(y \mid x) = 1\) となり、メトロポリス法の特殊形に簡約されます。
\[ \alpha = \min\{1,\ 0.4 \times 1\} = 0.4 \]
すなわち候補 \(y=2.0\) は40%の確率で受理されます。
実務でのポイント
ベイズ統計は試験対策にとどまらず、医薬・機械学習・金融の実務で広く活用されています。製薬業界ではベイズ統計の解析手法と製薬業界での活用で詳しく解説しているとおり、FDAの2026年ドラフトガイダンスを受けてベイズ流臨床試験デザインの採用が一気に進んでいます。
実務でベイズ推定を扱う際の鉄則は次の3点です。第一に、事前分布の選択を必ず正当化すること。無情報事前分布を採用する場合でも「なぜJeffreys事前を選んだのか」「過去試験データはどの程度ダウンウェイトしたか」を試験計画書に明記する必要があります。第二に、事後分布の感度分析を行うこと。事前分布のハイパーパラメータを動かして事後推論がどれだけ変化するかを必ず確認します。第三に、MCMCの収束診断を省略しないこと。\(\hat{R} < 1.01\)・有効サンプルサイズ(ESS)が十分大きいことを確認してから推論結果を報告するのが標準的なプロトコルです。 これらの考え方は試験勉強のなかでも自然に身につけられます。準1級で「事前分布の選び方」が問われたら、実務での感度分析を思い出す ── そんな往復ができるようになれば、ベイズ統計はあなたの強力な武器になります。
📚 この記事をより深く理解するための参考書籍
統計検定準1級のベイズ統計を体系的に学ぶには、以下の書籍が定番です。






関連記事・次のステップ
biostat4869.com にはベイズ統計と統計検定に関する記事を多数公開しています。本記事と併せて読むと、理解がさらに立体的になります。
- 統計検定 準1級・1級 攻略ガイド ─ 試験範囲・学習ステップ:本シリーズの上位編。準1級・1級全体の試験範囲と学習法を俯瞰したい方はまずこちらをご覧ください。
- 統計検定準1級「時系列解析」攻略 ─ AR・MA・ARIMAの本質:本シリーズの第1弾。時系列パートも準1級の頻出テーマです。
- ベイズ統計入門:頻度論との違いとベイズの定理:そもそもベイズ統計とは何か、頻度論との哲学的な違いから知りたい方向け。
- ベイズ統計における事前分布・事後分布・尤度の関係と共役事前分布:第2章の共役分布をさらに深掘りした記事です。
- ベイズ統計の信用区間と頻度論の信頼区間の違いについて:第3章の信用区間の理解をさらに固めたい方に。
- ベイズ統計の仮説検定と頻度論的仮説検定の違いを徹底解説:ベイズファクターと頻度論の仮説検定を比較したい方に。
- ベイズ統計の解析手法と製薬業界での活用 ─ RとSAS:ベイズを実務に持ち込みたい製薬関係者向け。
まとめ
本記事では、統計検定準1級のベイズ統計パートを「事前分布の更新」「点推定・信用区間」「MCMC」の3つの柱で体系的に整理しました。
ベイズ統計の出発点は ベイズの定理 \(p(\theta \mid x) \propto p(x \mid \theta)\, p(\theta)\) です。この比例関係さえ手で追えれば、準1級の小問の8割は地続きで解けます。続いて学んだ 共役事前分布 は計算上の最大の武器で、ベルヌーイ/二項にBeta、ポアソンにGamma、正規(分散既知)にNormalという3つの対応を覚えてしまえば、事後分布はパラメータの足し算だけで求まります。
点推定では 損失関数と最適推定量の対応(二乗誤差→事後平均、絶対誤差→事後中央値、0-1損失→MAP)を、区間推定では HDIと等裾信用区間の使い分け を押さえることが重要でした。頻度論の信頼区間との哲学的な違い(直接確率解釈ができるか)も頻出の論点です。
MCMCについては、詳細釣り合い条件とメトロポリス・ヘイスティングス法の受理確率を式で書けるレベル、ギブスサンプリングとの違いを言語化できるレベル、そして Gelman-Rubin \(\hat{R}\) による収束診断まで押さえれば準1級の出題範囲を十分にカバーできます。
ベイズ統計を準1級の得点源に変える最短ルートは、本記事の 典型出題3問 をスラスラ解けるようにし、そのうえで公式問題集の過去問演習に進むことです。試験対策の枠を超えて、ベイズ統計は医薬・機械学習・金融の最前線で必須スキルになっています。準1級の勉強を入り口に、ぜひベイズの世界に踏み込んでみてください。最後までお読みいただきありがとうございました。