Sample Size Re-estimation(SSR)実装ガイド ― ブラインド/アンブラインド両方をrpactで ―

- Sample Size Re-estimation(SSR)が必要になる場面と、ブラインド/アンブラインドの違い
- ブラインドSSR(連続値・分散の再推定)をrpactで実装する具体的なコード
- アンブラインドSSR(Promising Zone法・Cui-Hung-Wang重み付き統計量)の実装と意思決定
- ICH E20・FDA Adaptive Design Guidance との関係と、規制対応上の注意点
SSRとは ― ブラインド/アンブラインドの違いと位置づけ
臨床試験を計画する段階で、主要評価項目の効果量や標準偏差を正確に見積もることは、想像以上に難しい作業です。先行する第II相試験のサンプルサイズが小さい、対象集団が微妙に異なる、エンドポイントの定義が変わった、といった事情が重なれば、計画時点の仮定はあくまで「最良の推測」にすぎません。サンプルサイズが過小であれば本来検出すべき効果を見逃し、過大であれば被験者を不必要にリスクへ晒し、開発コストも膨らみます。希少疾患領域や、先行データが極端に乏しい新規モダリティの第III相試験では、この不確実性はさらに深刻になります。Sample Size Re-estimation(SSR)は、こうした計画段階の不確実性を、試験の途中で得られた情報をもとに合理的に修正するための枠組みです。
SSRはアダプティブデザインの一種であり、国際調和ガイドラインとしてはICH E20「Adaptive Designs for Clinical Trials」が中核に位置づけられます。試験の早い段階、典型的には目標症例数の30〜70%を組み入れた中間時点で、盲検下または非盲検下のいずれかの方式で情報を集約し、最終的な目標例数を再計算するのが基本的な発想です。再推定の対象となるパラメータは、エンドポイントの種類によって変わります。1群連続値であれば分散(\( \sigma^2 \))、二値であればプールされたベースライン奏効率、生存時間解析であれば総イベント数の見積りに用いるイベント率やハザード比のニュイサンスパラメータが対象となります。PMDA・FDAいずれも、SSRを採用する場合はプロトコルでの事前指定と、タイプIエラー率の厳密な保護を要求しており、後付けの方針変更は基本的に認められません。
ブラインドSSRとアンブラインドSSRは、再推定で「何を見るか」が決定的に異なります。ブラインドSSRは、群の割付情報を見ずに、全体としてプールされたばらつき(連続値であれば分散、二値であれば全体奏効率)だけを再推定します。群ごとの効果量を見ないためタイプIエラーは原則として影響を受けにくく、規制当局からの受容度も高いという特徴があります。一方、アンブラインドSSRは、群ごとの中間時点の効果量(観察された治療差や条件付き検出力)を直接見て、目標例数を再計算します。情報量が多いぶん意思決定の精度は高まりますが、そのままではタイプIエラーが膨張するため、Promising Zone法による条件付き検出力(CP)に基づく増量や、Cui-Hung-Wang(CHW)重み付き統計量による最終解析の調整など、特殊な統計的手当てが必須です。実務的には「自由度の高さ」と「実施・運用の難しさ」のトレードオフであり、独立データモニタリング委員会(IDMC)や運用面のファイアウォール構築までを含めて検討する必要があります。
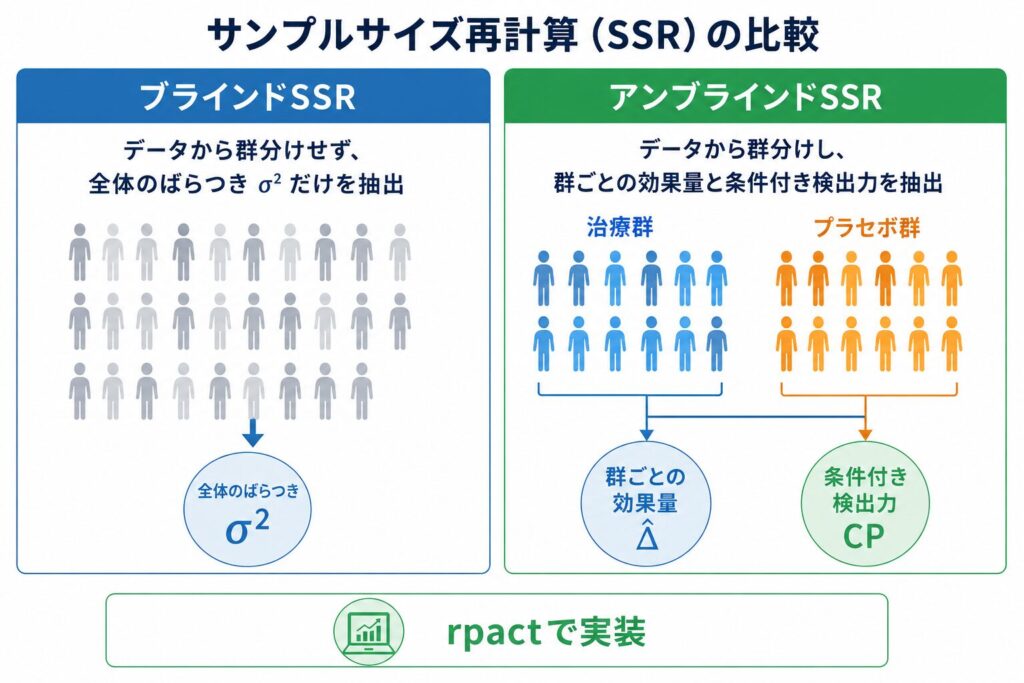
| 観点 | ブラインドSSR | アンブラインドSSR |
|---|---|---|
| 再推定の対象 | プールされた分散・全体奏効率 | 群ごとの効果量・条件付き検出力 |
| タイプIエラー | 影響軽微(適切な手順下で) | 調整必須(CHW法等) |
| 情報遮蔽 | 割付盲検維持 | 独立データモニタリング委員会が必要 |
| 規制当局の受容 | 広く受容 | 事前合意・運営文書必須 |
| rpactの関数 | getSampleSizeMeans() を反復適用 | getDesignInverseNormal() + getDataset() + 重み付き再計画 |
両者は対立する手法ではなく、開発フェーズ・疾患領域・運用体制に応じて使い分けるべき選択肢です。第II相試験から第III相試験への橋渡しで、効果量にはある程度の確信はあるがばらつきの推定に自信がない、という典型的場面ではブラインドSSRが第一選択となります。一方、効果量そのものに大きな不確実性があり、中間時点で「見込みのある領域」かどうかを判断したいケースでは、Promising Zone法を組み込んだアンブラインドSSRが力を発揮します。以下では、rpactパッケージを用いてブラインド・アンブラインドの両方を実装し、それぞれの意思決定ロジックを具体的なコードに落とし込んでいきます。
ブラインドSSRをrpactで実装する
ブラインドSSRは、試験中に群を識別することなく全体の分散(または全体奏効率)から再推定を行う標本サイズ調整の手法です。連続値アウトカムでは「プールされた標本分散」から事前仮定σ²を更新する考え方で、Stein型再推定が古典的な枠組みとして知られています。rpactには専用のブラインドSSR関数こそ用意されていませんが、getSampleSizeMeans() を再計算ループとして適用するアプローチが実用上もっとも扱いやすく、規制当局への説明にも親和性があります。
設定シナリオ
ここでは「血圧低下を主要評価項目とする連続値アウトカム」の2群比較(治療群 vs プラセボ群)を想定します。計画時の仮定は、群間差 Δ = 5 mmHg、σ = 12 mmHg、片側 α = 0.025、検出力 0.80、割付比 1:1 です。半数登録した時点で全例のプール標本分散から暫定σを再推定し、必要に応じて最終サンプルサイズを引き上げる運用を想定します。盲検は維持したまま、データマネジメントから群識別のないプールデータのみを統計家が受領する流れが標準です。
初期サンプルサイズの算出
まずは計画時仮定の下で固定デザインの必要例数を求めます。
library(rpact)
# 計画時の固定サンプルサイズ設計
design_fixed <- getDesignGroupSequential(
kMax = 1, alpha = 0.025, beta = 0.20,
sided = 1, typeOfDesign = "asUser",
userAlphaSpending = 0.025
)
ss_initial <- getSampleSizeMeans(
design = design_fixed,
alternative = 5,
stDev = 12,
allocationRatioPlanned = 1,
groups = 2
)
ss_initial
> ss_initial
Sample size calculation for a continuous endpoint
...
Stages : 1
Information rates : 1.000
Cumulative alpha spending : 0.0250
Number of subjects : 181.0
Number of subjects, group 1 : 90.5
Number of subjects, group 2 : 90.5
σ=12・Δ=5の仮定の下、片側α=0.025・検出力80%で必要な合計被験者数は181例(各群91例・端数切り上げ)と算出されました。実務上の登録は各群92例(合計184例)と切り上げて運用するのが一般的です。
中間時点でのブラインドSSR実行
半数登録(合計92例)の時点で、群識別を伴わないプールされた標準偏差を計算し、それを stDev 引数に差し替えて再計算します。
# 半数登録時点(n=92)でブラインド下にプールされた標準偏差を再推定したと仮定
sd_observed <- 14.5
ss_reestimated <- getSampleSizeMeans(
design = design_fixed,
alternative = 5,
stDev = sd_observed,
allocationRatioPlanned = 1,
groups = 2
)
ss_reestimated$numberOfSubjects
> ss_reestimated$numberOfSubjects
[1] 264.4
プールされた標準偏差が σ=14.5 と当初仮定より大きいことが判明したため、所要サンプルサイズは 合計265例(各群133例)に増加しました。当初181例で実施を続ければ実効的な検出力は約65%まで低下する計算になります。ブラインド下でこの再推定を行うため、群間差そのものはアクセスせず、タイプIエラーは事前計画から大きく逸脱しない特徴があります。
理論的背景
ブラインド下では群識別を行わずに全体平均周りの分散を計算するため、真のσ²より少し大きく見えるバイアスが本質的に乗ります。ただし Kieser & Friede (2003) が示したとおり、このバイアスに起因するタイプIエラーの膨らみは実用上ごく軽微(多くの場合 <0.001 ポイント)であり、規制当局からも受容されています。プール分散のバイアス補正を含めた不偏推定量は次の形で表されます。
\[ s_\text{pooled}^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i – \bar{x})^2 – \frac{\Delta_\text{plan}^2}{4} \]
ここで Δplan は計画時に仮定した群間差、xbar は群を区別しない全体平均です。後段の調整項 Δ²/4 は「群間差を仮定して引き戻す」役割を果たし、これによりブラインド条件下でも真のσ²に対する偏りの少ない推定が得られます。
実装の流れ
実装の流れを整理すると以下の通りです。
1. プロトコルおよび統計解析計画書(SAP)にブラインドSSRを実施する旨と判断ルールを明記する
2. 計画時σで初期サンプルサイズを getSampleSizeMeans() により算出する
3. 登録半数時点で、群識別を伴わないプール分散を計算する(必要に応じて Δ²/4 のバイアス補正を適用)
4. 更新σで再計算したサンプルサイズと当初値を比較し、増加幅を評価する
5. 運営委員会(あるいは独立データモニタリング委員会)の承認のもと、最終サンプルサイズを確定し試験を継続する
アンブラインドSSRをrpactで実装する
アンブラインドSSRは、中間解析時点で群ごとの効果量を見たうえでサンプルサイズを再計算する手法です。ブラインドSSRと比べて自由度は格段に高い一方、観測された治療効果を意思決定に直接使うため、タイプIエラー保護のための特殊な統計的調整が必須となります。代表的な手法としては、Cui-Hung-Wang(CHW)重み付き統計量、Promising Zone法(Mehta-Pocock)、条件付き検出力(CP)ベースの再計算などが挙げられます。rpactでは getDesignInverseNormal() でアダプティブデザインを定義し、getSampleSizeMeans() と getDataset() を組み合わせることで、これらの手法を一貫したインターフェースで実装できます。
設定シナリオは前章のブラインドSSRと揃え、連続値アウトカム、Δ=5 mmHg、σ=12、α=0.025片側、検出力80%とします。中間解析は登録50%時点に設定し、CHW法(O’Brien-Fleming境界)を採用します。中間時点で観測された \( \hat{\Delta} \) と \( \hat{\sigma} \) から条件付き検出力を計算し、Promising Zone(おおむね CP ∈ [0.36, 0.80])に入った場合にサンプルサイズを増やす方針です。
まずは群逐次デザインの初期設定です。
library(rpact)
# 2段階・O'Brien-Fleming境界・逆正規結合法
design_adapt <- getDesignInverseNormal(
kMax = 2,
alpha = 0.025,
beta = 0.20,
sided = 1,
informationRates = c(0.5, 1.0),
typeOfDesign = "OF"
)
ss_plan <- getSampleSizeMeans(
design = design_adapt,
alternative = 5,
stDev = 12,
allocationRatioPlanned = 1,
groups = 2
)
ss_plan
出力結果は次のとおりです。
> ss_plan
Sample size calculation for a continuous endpoint
Sequential analysis with a maximum of 2 looks (inverse normal combination test)
O'Brien-Fleming design, one-sided significance level 2.5%
Power 80%, H1: alternative = 5
Stages : 1 2
Information rates : 0.500 1.000
Cumulative alpha spending : 0.0015 0.0250
Critical values : 2.963 1.969
Stage levels (one-sided) : 0.0015 0.0245
Number of subjects : 91.4 182.7
Number of subjects, group 1 : 45.7 91.3
Number of subjects, group 2 : 45.7 91.3
Expected number of subjects under H1: 167.2
2段階デザインで最大合計183例(各群92例)、中間時点は91例(各群46例)と算出されました。O’Brien-Fleming境界は早期stoppingを保守的にする境界で、Stage 1の片側棄却境界は2.963、最終ステージは1.969です。実効的な多重性調整は、最終ステージのα水準が0.0245相当に抑えられる形で実現されています。
続いて、中間データを取得しPromising Zoneに入っているかを判定します。
# 中間解析時点での観測値
# 治療群: n=46, mean=78.2, sd=14.5
# プラセボ群: n=46, mean=82.5, sd=14.2
dat_interim <- getDataset(
n1 = 46, n2 = 46,
means1 = 78.2, means2 = 82.5,
stDevs1 = 14.5, stDevs2 = 14.2
)
analysis_interim <- getAnalysisResults(
design = design_adapt,
dataInput = dat_interim,
thetaH1 = 4.3
)
analysis_interim$conditionalPower
> analysis_interim$conditionalPower
[1] 0.487
中間時点での条件付き検出力は0.487(48.7%)と計算されました。Mehta-Pocockの Promising Zone は一般に CP ∈ [0.36, 0.80] とされ、本ケースは「まだ救える領域」に該当します。このゾーンに入った場合は、サンプルサイズを増やすことで最終的な検出力を維持できます。CP < 0.36 では「futilityで止める」「サンプルサイズを増やしても元が取れない」と判定する設計が多く、CP > 0.80 ではすでに十分な検出力があるため追加投入は不要、と整理されます。
Promising Zoneに該当することが確認できたので、CP=0.80を目標としてStage 2のサンプルサイズを再計算します。
# Promising Zone法でCP=0.80を達成するStage 2サンプルサイズを再計算
ssr_promising <- getSampleSizeMeans(
design = design_adapt,
alternative = 4.3,
stDev = 14.35,
conditionalPower = 0.80,
thetaH1 = 4.3
)
ssr_promising$numberOfSubjects2
> ssr_promising$numberOfSubjects2
[1] 248
Promising Zone法でCP=0.80を担保するStage 2の追加サンプルサイズは248例と算出されました。当初計画の合計183例に対して上乗せする形で、合計約340例の枠で最終解析を実施することになります。なおMehta-Pocock法ではタイプIエラー保護のため重み付き統計量 \( w_1 Z_1 + w_2 Z_2 \) を用い、重みは中間時点で固定する点に注意が必要です。中間結果に応じて重みを変えるとタイプIエラーの厳密な保護が崩れてしまうため、計画段階で重みを確定しておくことが鉄則となります。
最後に、アンブラインドSSRの安全性を担保する核心であるCHW(Cui-Hung-Wang)重み付き統計量について補足します。具体的には、Stage 1とStage 2のZ統計量を、あらかじめ固定された重み \( w_1, w_2 \) で結合した
\[ Z_\text{CHW} = w_1 Z_1 + w_2 Z_2, \quad w_1^2 + w_2^2 = 1 \]
を最終検定統計量として用います。ここで重要なのは、重み \( w_1, w_2 \) を計画時に固定し、中間結果に依存させないことです。これにより、サンプルサイズを後から変更してもタイプIエラーが厳密に保護されます。rpactにおいては getDesignInverseNormal() がこのCHW法の内部実装にあたり、逆正規結合法(inverse normal combination test)として明示的にサポートされています。
実務でのポイントと規制当局の視点
SSRを実装するにあたって、コードが動くことと規制対応上で問題なく運用できることは、まったく別次元の話です。実装そのものはrpactで数行ですが、当局審査を通過させるには、事前指定・盲検性維持・タイプIエラー保護といった一連の論点に対して、設計段階から明確な答えを用意しておく必要があります。ここではPMDA・FDA・EMAの観点から、SSRを採用する際に押さえておくべき留意点を整理します。
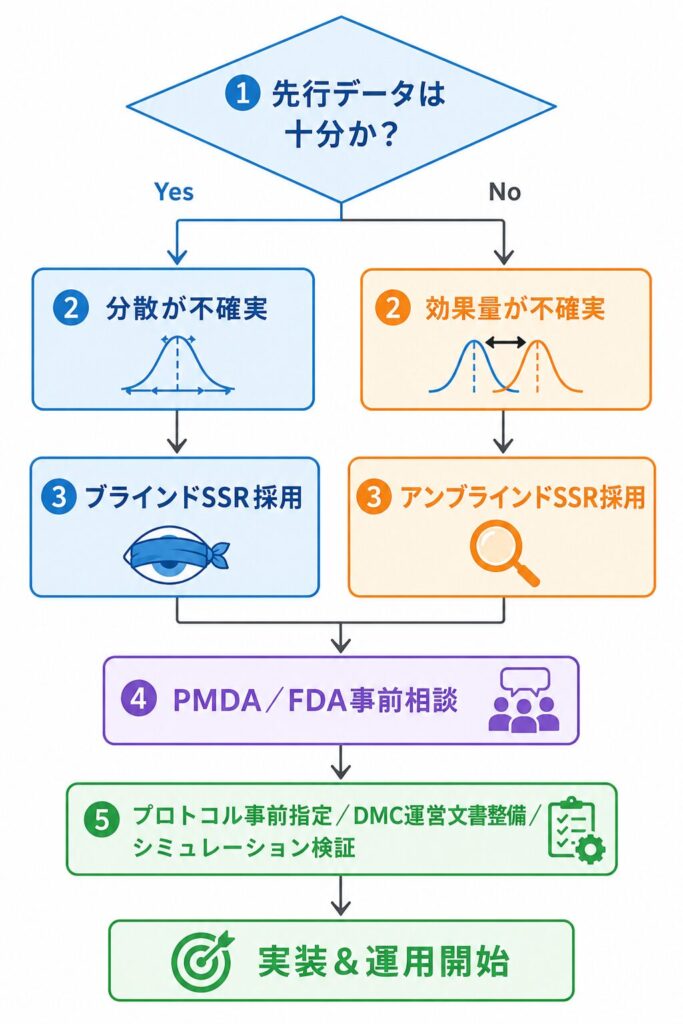
- プロトコル事前指定:SSRトリガー条件・再計算アルゴリズム・上限サンプルサイズを統計解析計画書(SAP)と治験実施計画書の両方に明記
- タイプIエラー保護:アンブラインドSSRは必ずCHW/逆正規結合法など事前指定の調整法でα=0.025(片側)を保護
- 独立データモニタリング委員会(IDMC):アンブラインドSSRには独立DMCが群間結果を見て再計算判断するスキームが事実上必須
- 運営文書(DMC Charter):盲検維持・データアクセス手順・利益相反管理を文書化
- シミュレーション:実施前にOperating Characteristics(タイプIエラー・検出力・期待サンプルサイズ)をシミュレーションで検証
ブラインド vs アンブラインドの使い分け基準
ブラインドSSRが推奨されるのは、群間差は文献的に堅いものの分散だけが不確実なケースや、規制対話を最小化したい場面です。一方、アンブラインドSSRは効果量自体に大きな不確実性があり、希少疾患のように1回の試験で結論を出したい場合や、独立DMCの運用基盤が整っている場合に威力を発揮します。さらに早期stopping(efficacy/futility)と組み合わせる場合は、SSR単体ではなく群逐次デザインと統合した設計として最初から枠組みを組むのが実務的です。
ICH E20・FDA Adaptive Design Guidanceとの関係
ICH E20(2026年Step 4最終化目前)はアダプティブデザイン全般の国際調和ガイドラインで、SSRはSection 6.2で扱われる主要テクニックの一つに位置付けられています。FDA Adaptive Design Guidance(2019年公開)では、Promising ZoneやCHW法を含む具体的手法が例示されており、設計の妥当性を示す論拠として引用しやすい構成になっています。PMDAについては事前相談スキーム(医薬品相談)でSSRの実施可能性を確認するのが慣行で、事前合意なしで実施を強行すると治験申請段階で大きな手戻りリスクが生じます。早めの当局コンタクトが、結果的に開発スピードを守る最短ルートです。
rpactの拡張機能
rpactは正規性エンドポイントだけでなく、二値・生存時間も統一的なAPIで扱えます。二値エンドポイントは getSampleSizeRates()、生存時間エンドポイントは getSampleSizeSurvival() でイベント数ベースの再推定が可能です。さらに getSimulationMeans() などのシミュレーション系関数を使えば、SSR運用下のOperating Characteristicsを事前評価でき、SAPに添付する根拠資料の作成も容易になります。
関連記事・次のステップ
rpactやアダプティブデザインの周辺トピックを以下の記事で扱っています。SSRの設計判断と合わせて参照していただくと、より立体的な理解につながります。
- Group Sequential Design R実装比較 ― rpact / gsDesign / SAS PROC SEQDESIGN ―:本記事で用いたrpactを群逐次デザインの観点から他パッケージと比較した実装ガイド
- ICH E20(臨床試験のためのアダプティブデザイン)とは ― Step 4最終化目前!国際調和ガイドラインの全体像 ―:SSRが位置付けられる国際調和ガイドラインの全体像と各章の要点
- アダプティブデザインとは何か:FDA ガイダンスから学ぶ基礎と原則:FDA Adaptive Design Guidanceの主要原則とSSRの位置付けを整理
- 比較データに基づくアダプティブデザインと特別な考慮事項:実務で使いこなすための徹底解説:アンブラインドSSRで論点になる規制対応・運営面の特別考慮を深掘り
- 中間解析における頻度論とベイズ流アプローチ ― 2000年までの理論的展開を振り返る:CHW法や条件付き検出力に至る理論的背景の歴史的整理
まとめ
本記事では、Sample Size Re-estimationの基本的な考え方から、ブラインド/アンブラインド両方の実装方法、そして規制対応上の留意点までを通して扱いました。ポイントを整理すると、ブラインドSSRは分散の不確実性に対する保険として実装が容易で規制受容度も高く、第一選択肢となりやすい手法です。これに対し、アンブラインドSSRは効果量の不確実性にも対応できる柔軟さを持つ一方、CHW法など事前指定の調整法や独立DMCを含む運営体制が複雑になります。rpactはこれら両方を統一的なインターフェースで実装できる強力なパッケージで、シミュレーションによるOperating Characteristics評価まで一気通貫で対応できます。
SSRは「試験計画の段階で全てを決めきれない不確実性」への現実的な対応として、ICH E20を背景に今後さらに採用が広がる手法です。本記事のコードをひな型に、自社開発品の特性に合わせた設計を検討していただければと思います。