統計検定準1級「時系列解析」攻略 ― AR/MA/ARIMAの本質と典型出題パターン

・時系列データの基礎と弱定常性の3条件
・AR・MA・ARMA・ARIMAモデルの定義と本質的な違い
・ACF・PACFのコレログラムからモデル次数を読み取る方法
・Rの
auto.arima()を使った実装と残差診断の流れ・統計検定準1級で頻出する5つの典型出題パターンと解法のコツ
はじめに
統計検定準1級の出題範囲のなかで、時系列解析は「数式・グラフ・Rコードのいずれの形でも問われる」総合的なテーマです。AR・MA・ARIMAというモデル名は耳にしたことがあっても、定常条件と反転可能性の区別、ACFとPACFの読み分け、差分操作の意味などをきちんと整理できている受験者は多くありません。
時系列解析は選択科目の一つとして比較的出題されやすい単元とされており、頻出パターンを押さえておくと得点源になりやすい領域です。逆に言えば、苦手意識を残したまま本番を迎えると、選択できる問題が限られてしまうリスクもあります。
本記事では、AR・MA・ARIMAモデルの本質を直感的な説明と数式の両面から整理し、ACF・PACFによるモデル同定の典型パターン、Rでの実装手順、そして統計検定準1級で問われやすい出題パターンを体系的に解説します。実務でも頻繁に登場する時系列解析の基礎を、試験対策と並行して身につけていきましょう。
時系列データの基礎と定常性
時系列解析を学ぶ上で最初に立ちはだかる壁が「定常性(stationarity)」という概念です。回帰分析や分散分析では当然のように仮定されていた「観測の独立性」が、時系列データでは成立しません。株価や売上、臨床試験の経時データなど、時間とともに観測される値は過去の影響を強く受けるため、独立同分布(i.i.d.)を前提とした手法をそのまま当てはめると誤った結論を導いてしまいます。この章では、時系列モデルの土台となる定常性とその周辺概念を整理していきます。
時系列データとクロスセクションデータの違い
時系列データ(time series data)とは、同一の対象を時間順に並べて観測したデータのことです。日次の株価、月次の売上高、四半期ごとのGDP、臨床試験での被験者の経時的なバイオマーカー測定などが典型例です。一方、ある時点で複数の対象を観測したものはクロスセクションデータ(横断面データ)と呼ばれます。
両者の最大の違いは、観測の独立性が仮定できるかどうかにあります。クロスセクションデータでは個体間の独立性をある程度仮定できますが、時系列データでは「今日の株価」は「昨日の株価」と強く相関しており、独立とはみなせません。この時間的依存構造(temporal dependence)こそが、時系列解析の出発点であり、同時に難所でもあります。
弱定常性(covariance stationary)の3条件
時系列\( \{y_t\} \)が弱定常(共分散定常、weakly stationary)であるとは、次の3条件を満たすことをいいます。
\[ E[y_t] = \mu \quad (\text{すべての } t) \]
平均が時点\( t \)に依存せず一定であることを意味します。
\[ V[y_t] = \sigma^2 \quad (\text{すべての } t) \]
分散も時点に依存せず一定です。
\[ \mathrm{Cov}(y_t, y_{t-k}) = \gamma_k \quad (k \text{ のみに依存}) \]
自己共分散がラグ\( k \)のみの関数であり、観測時点\( t \)そのものには依存しないという条件です。これら3つを整理すると次のようになります。
| 条件 | 数式 | 直感的な意味 |
|---|---|---|
| 平均一定 | \( E[y_t] = \mu \) | トレンドを持たない |
| 分散一定 | \( V[y_t] = \sigma^2 \) | ばらつきが時間で変わらない |
| 自己共分散がラグ依存 | \( \mathrm{Cov}(y_t, y_{t-k}) = \gamma_k \) | 相関構造が時間でシフトしない |
強定常性(strict stationarity)は、これより強い条件で、任意の有限個の時点\( (y_{t_1}, \ldots, y_{t_n}) \)の同時分布が時間シフト\( h \)に対して不変であることを要求します。実務上は弱定常で十分なケースが多く、統計検定準1級でも基本的に弱定常を指して「定常」と表現します。
自己共分散関数と自己相関関数(ACF)
定常時系列に対して、ラグ\( k \)の自己共分散関数(autocovariance function)は次で定義されます。
\[ \gamma_k = \mathrm{Cov}(y_t, y_{t-k}) = E[(y_t – \mu)(y_{t-k} – \mu)] \]
これを\( \gamma_0 = V[y_t] \)で割って基準化したものが自己相関関数(autocorrelation function, ACF)です。
\[ \rho_k = \frac{\gamma_k}{\gamma_0} \]
\( \rho_k \)は\( -1 \leq \rho_k \leq 1 \)の値をとり、ラグ\( k \)離れた観測値同士の線形相関を表します。ACFの形状はモデル同定の重要な手掛かりとなり、後の章で詳しく扱います。
ホワイトノイズ:時系列解析の出発点
ホワイトノイズ(white noise)\( \{\varepsilon_t\} \)は、以下の3条件を満たす時系列です。
\[ E[\varepsilon_t] = 0, \quad V[\varepsilon_t] = \sigma^2, \quad \mathrm{Cov}(\varepsilon_t, \varepsilon_s) = 0 \ (t \neq s) \]
平均ゼロ・分散一定・自己相関ゼロという最もシンプルな定常過程です。AR・MA・ARIMAモデルでは、ホワイトノイズを「モデルでは説明できない撹乱項」として組み込みます。逆に言えば、モデル化の最終目標は「残差をホワイトノイズに近づけること」だと理解しておくと、後の章の見通しが良くなります。
ホワイトノイズは「ランダム」とは限りません。独立性までは要求せず、無相関と等分散だけを課す概念です。正規性も加えたものをガウシアン・ホワイトノイズと呼びます。
ランダムウォークと単位根:典型的な非定常過程
非定常性の代表例が、ランダムウォーク(random walk)です。
\[ y_t = y_{t-1} + \varepsilon_t \]
一見シンプルですが、これは弱定常の条件を満たしません。\( y_0 = 0 \)から始めると\( y_t = \sum_{i=1}^{t}\varepsilon_i \)となるため、分散は\( V[y_t] = t\sigma^2 \)と時間とともに発散します。株価対数や為替レートはランダムウォーク的な振る舞いをすることが知られており、そのままでは予測や統計的推測の前提が崩れます。
このような系列は「単位根(unit root)を持つ」と表現され、1階の差分\( \Delta y_t = y_t – y_{t-1} = \varepsilon_t \)をとることで定常化できます。これがARIMAモデルの「I(Integrated)」の正体です。
トレンドを持つ系列に対して通常の最小二乗法を適用すると、本来無関係な2つの系列の間に有意な相関が検出される「見せかけの回帰(spurious regression)」が起こります。経済データの解析で頻出する罠で、準1級でも出題対象です。
なぜ定常性が重要か
定常性は単なる数学的な制約ではなく、推定と予測の理論的な土台です。弱定常であれば、平均\( \mu \)や自己共分散\( \gamma_k \)を標本から一貫して推定できる(エルゴード性が成り立つもとで、標本平均が母平均に収束する)ため、過去のデータから将来を予測するという営みに統計的な根拠を与えられます。逆に非定常な系列をそのまま扱うと、推定量が収束せず、予測区間も信頼できません。
そのため時系列解析の標準的なワークフローは、(1) 系列を可視化して非定常性の兆候(トレンド・分散の不均一)を確認し、(2) 差分や対数変換で定常化し、(3) 定常化された系列にAR/MA/ARIMAを当てはめる、という流れになります。次章では、定常時系列の代表的なモデルであるAR・MA・ARIMAの本質を見ていきます。
AR・MA・ARIMAモデルの本質
時系列解析の出題で核となるのが、AR・MA・ARMA・ARIMAという4つのモデル族です。準1級では「式の意味を理解しているか」「定常条件・反転可能性を区別できるか」「差分の役割を説明できるか」が繰り返し問われます。ここでは数式と直感の両方から、それぞれのモデルの本質を整理していきます。
AR(p)モデル:過去の自分自身から未来を予測する
自己回帰モデル(AutoRegressive model)は、現在の値を「過去の自分自身の線形結合」として表現するモデルです。次数\(p\)のARモデルは次のように書けます。
\[ X_t = c + \phi_1 X_{t-1} + \phi_2 X_{t-2} + \cdots + \phi_p X_{t-p} + \varepsilon_t \]
ここで\(c\)は定数項、\(\phi_i\)は自己回帰係数、\(\varepsilon_t\)は平均0・分散\(\sigma^2\)のホワイトノイズを意味します。直感的には「今日の値は、過去\(p\)日分の値にそれぞれ重みをかけて足し合わせ、最後にランダムな揺らぎを加えたもの」というイメージです。AR(1)であれば「今日の気温が昨日の気温の影響を受ける」という素朴な現象をそのまま数式化していると考えると分かりやすいでしょう。
ARモデルで最も重要なのが定常条件です。AR(p)が定常となるのは、特性方程式
\[ 1 – \phi_1 z – \phi_2 z^2 – \cdots – \phi_p z^p = 0 \]
のすべての根が単位円の外側(\(|z| > 1\))にあるときです。AR(1)であれば\(|\phi_1| < 1\)という単純な条件に帰着します。これを満たさないと値が発散したり、過去の影響がいつまでも消えなかったりして、安定した予測ができません。
準1級では「\(\phi_1 = 0.8\)のとき定常か」「\(\phi_1 = 1.2\)のときどうなるか」といった具体値判定が頻出です。\(|\phi_1| < 1\)なら定常、\(|\phi_1| = 1\)なら単位根(非定常、後述のARIMAの世界へ)、\(|\phi_1| > 1\)なら発散と整理しておきましょう。
MA(q)モデル:過去のショックの記憶として現在を表現する
移動平均モデル(Moving Average model)は、現在の値を「過去のショック(ホワイトノイズ)の線形結合」として表現します。次数\(q\)のMAモデルは次のとおりです。
\[ X_t = \mu + \varepsilon_t + \theta_1 \varepsilon_{t-1} + \theta_2 \varepsilon_{t-2} + \cdots + \theta_q \varepsilon_{t-q} \]
ここで\(\mu\)は系列の平均、\(\theta_j\)はMA係数、\(\varepsilon_{t-j}\)は過去のホワイトノイズを意味します。ARが「過去の値そのもの」を使うのに対し、MAは「過去に発生した予測誤差(ショック)」を使う点が決定的に違います。直感的には「先週起きた予期せぬ出来事が、今週の値にも少し尾を引いている」というイメージです。
MAモデルは有限項のホワイトノイズの和なので、係数\(\theta_j\)が有限なら常に定常になります。代わりに重要なのが反転可能性(invertibility)です。MA(q)が反転可能であるのは、MA特性方程式
\[ 1 + \theta_1 z + \theta_2 z^2 + \cdots + \theta_q z^q = 0 \]
のすべての根が単位円の外側にあるときです。反転可能なMAモデルは、無限次のARモデルとして書き直せるため、過去の観測値だけからショックを一意に逆算できるという良い性質を持ちます。
「ARは定常条件・MAは反転可能性」と覚えるのが基本ですが、両者とも特性方程式の根が単位円の外という形は同じです。違うのは「何のモデルに対する条件か」だけ。準1級ではこの対応関係を逆に答えさせる選択肢がよく出るので、AR=値の線形結合の安定性、MA=ARへの書き換え可能性、と意味で押さえておきましょう。
ARMA(p,q)モデル:ARとMAのいいとこ取り
現実の時系列は「過去の値の影響」と「過去のショックの影響」の両方を受けることが多いため、両者を融合したARMAモデルが用いられます。
\[ X_t = c + \phi_1 X_{t-1} + \cdots + \phi_p X_{t-p} + \varepsilon_t + \theta_1 \varepsilon_{t-1} + \cdots + \theta_q \varepsilon_{t-q} \]
ここで前半がAR成分、後半がMA成分を意味します。ARMAの強みは、純粋なAR(p)やMA(q)で表現すると次数が大きくなりすぎる現象を、より少ないパラメータで簡潔に表せる点にあります(パーシモニーの原理)。定常性はAR部分が、反転可能性はMA部分が担います。
ARIMA(p,d,q)モデル:差分で非定常データを定常に変える
ここまでの議論はすべて定常な時系列を前提としていました。しかし株価や売上のように上昇トレンドを持つデータは非定常です。そこで「差分を取って定常化してからARMAを当てはめる」という発想で登場するのがARIMA(p,d,q)モデルです。差分演算子を\(\Delta X_t = X_t – X_{t-1}\)とすると、\(d\)階差分を取った系列\(\Delta^d X_t\)がARMA(p,q)に従うとき、元の\(X_t\)はARIMA(p,d,q)に従うと言います。
ここで\(d\)はIntegrated(和分)の次数を意味し、何階差分を取れば定常になるかを表します。経済データの多くは\(d=1\)(1階差分で定常)、季節性のないトレンドデータでも\(d=1\)か\(d=2\)で十分なケースがほとんどです。
4つのモデルの使い分け:強み・弱みを一覧で整理
| モデル | 構造の本質 | 強み | 弱み・前提 |
|---|---|---|---|
| AR(p) | 過去の値の線形結合 | 解釈が直感的・推定が容易 | 定常条件を満たす必要あり |
| MA(q) | 過去のショックの線形結合 | 常に定常・短期的衝撃の表現に強い | 反転可能性が必要・推定はやや複雑 |
| ARMA(p,q) | 値とショックの両方を利用 | 少ないパラメータで複雑な構造を表現 | 定常データ限定・次数選定が悩ましい |
| ARIMA(p,d,q) | 差分でトレンド除去 + ARMA | 非定常データにそのまま適用可能 | 差分次数\(d\)の選定が必要・季節性は別途SARIMAで |
実務での選び方の指針はシンプルです。まず系列が定常かどうかを単位根検定や時系列プロットで確認し、非定常ならARIMA(差分を取る)、定常ならARMAを検討します。さらにACF・PACFの形状を見て、ACFが\(q\)次で急に切れればMA(q)、PACFが\(p\)次で急に切れればAR(p)、両方ともゆっくり減衰するならARMAが候補となります。この判別は次章で詳しく扱います。
ARは「値の慣性」、MAは「ショックの残響」、ARMAはその融合、ARIMAは差分で非定常データに対応した拡張、と一文で整理できます。準1級では(1)AR(1)の定常条件\(|\phi_1|<1\)、(2)MAは常に定常で反転可能性が論点、(3)ARIMAの\(d\)は差分回数、の3点が頻出ポイントです。「定常条件」と「反転可能性」が指す対象を取り違えないことが、選択肢問題で確実に得点する最大のコツです。
ACF・PACFによるモデル同定 ― 典型出題パターン
AR・MA・ARIMAの理論的な定義を理解したら、次のステップは「実際のデータからどのモデルが妥当か」を判定する作業です。統計検定準1級では、ACF(自己相関関数)とPACF(偏自己相関関数)のコレログラムを示し、適切なモデルを選ばせる問題が定番です。この章では、ACF・PACFの定義と読み方、そして典型出題パターンの見抜き方を整理します。
自己相関関数(ACF)の定義と読み方
自己相関関数(Autocorrelation Function, ACF)は、時系列 \( X_t \) と、そこから \( k \) 期ずれた \( X_{t-k} \) との相関を表す関数です。ラグ \( k \) における自己相関係数は次のように定義されます。
\[ \rho_k = \frac{\text{Cov}(X_t, X_{t-k})}{\sqrt{\text{Var}(X_t)\text{Var}(X_{t-k})}} = \frac{\gamma_k}{\gamma_0} \]
ここで \( \gamma_k \) はラグ \( k \) の自己共分散、\( \gamma_0 \) は分散です。定常過程ではラグ0で必ず1となり、ラグが大きくなるほど通常は0に近づきます。ACFを縦軸、ラグを横軸に取った棒グラフを「コレログラム」と呼び、時系列解析の最重要図のひとつです。
偏自己相関関数(PACF)の直感
偏自己相関関数(Partial Autocorrelation Function, PACF)は、間にあるラグ \( X_{t-1}, X_{t-2}, \ldots, X_{t-k+1} \) の影響を取り除いたうえで、\( X_t \) と \( X_{t-k} \) の純粋な相関を測る指標です。
\[ \phi_{kk} = \text{Corr}(X_t, X_{t-k} \mid X_{t-1}, X_{t-2}, \ldots, X_{t-k+1}) \]
たとえばAR(1)過程では \( X_t \) と \( X_{t-2} \) の間にもACF上は相関が現れますが、それは「\( X_{t-1} \) を経由した間接的な相関」に過ぎません。PACFはこの間接効果を取り除くため、AR(1)ではラグ2以降がゼロに近くなります。ACFが「総合的な相関」、PACFが「直接的な相関」と理解すると整理しやすいでしょう。
ACFとPACFは互いを補完する関係にあります。ACFだけ、PACFだけではモデル次数を特定できず、両方を並べて見ることで初めてAR・MA・ARMAの判別が可能になります。
AR・MA・ARMAそれぞれのACF/PACFパターン
準1級で問われるモデル同定の核心は、次の対応関係を覚えることに尽きます。
AR(p)モデルでは、ACFは指数的に減衰(または振動しながら減衰)し、PACFはラグ \( p \) を超えた時点で急にゼロに近づきます。これを「PACFが \( p \) 次でカットオフする」と表現します。逆にMA(q)モデルでは、ACFがラグ \( q \) でカットオフし、PACFが指数的に減衰します。ちょうどACFとPACFの役割が入れ替わる構造です。ARMA(p,q)の場合は両方とも徐々に減衰し、明確なカットオフは見られません。
| モデル | ACFの挙動 | PACFの挙動 | 準1級での見抜き方 |
|---|---|---|---|
| AR(p) | 指数的に減衰(または振動しながら減衰) | ラグ p でカットオフ | PACFがスパッと切れる位置 = 次数 p |
| MA(q) | ラグ q でカットオフ | 指数的に減衰 | ACFがスパッと切れる位置 = 次数 q |
| ARMA(p,q) | 徐々に減衰(カットオフなし) | 徐々に減衰(カットオフなし) | どちらもダラダラ尾を引く → ARMA |
| ホワイトノイズ | 全ラグで信頼区間内 | 全ラグで信頼区間内 | どちらも棒がほぼ立たない |
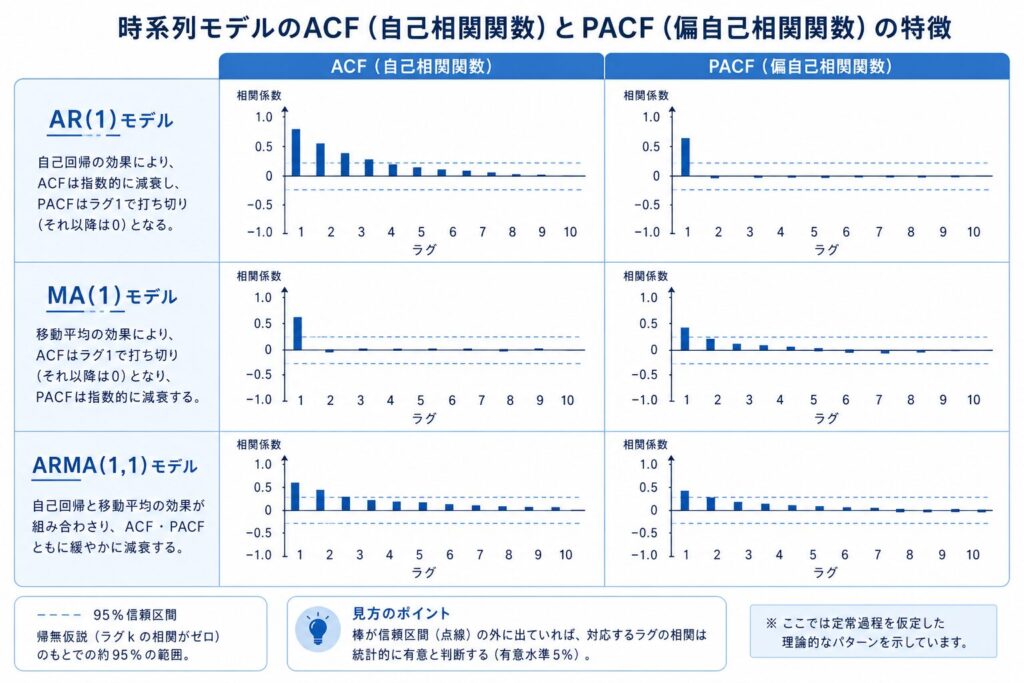
コレログラムの95%信頼区間の読み方
コレログラムには通常、点線で示される95%信頼区間が描かれています。ホワイトノイズ仮説のもとで自己相関係数は近似的に正規分布に従い、その標準誤差は \( 1/\sqrt{n} \) となります。したがって95%信頼区間の幅は次式で与えられます。
\[ \pm \frac{1.96}{\sqrt{n}} \]
ここで \( n \) はサンプルサイズです。この帯から外れた棒は「統計的に有意な自己相関がある」と判断し、帯の内側に収まる棒は「ゼロとみなしてよい」と読みます。準1級のコレログラム問題では、まずこの信頼区間からの「外れ方」を見て、有意なラグの位置と次数を特定することが第一歩です。
カットオフと指数減衰の見極めは、必ず信頼区間からの外れ方で判断してください。「ラグ2の棒が少し小さい」だけでは指数減衰とは断定できません。信頼区間内に入った時点でカットオフ、その後もパラパラと有意な棒が続くなら指数減衰、と機械的に判定するのが安全です。
典型出題パターンの整理
準1級のモデル同定問題は、概ね次の3パターンに集約されます。パターン1:PACFがラグ1または2で明確にカットオフ、ACFは緩やかに減衰 → AR(1)またはAR(2)を選ぶ。パターン2:ACFがラグ1または2でカットオフ、PACFは緩やかに減衰 → MA(1)またはMA(2)を選ぶ。パターン3:ACF・PACFともダラダラと減衰 → ARMAモデルを選ぶ。さらに、原系列のACFが減衰せずほぼ一定値を取り続ける場合は「非定常」を示唆し、差分系列に対する分析(ARIMAモデル)に進む必要があります。
実務のデータは理論通りキレイなパターンを示さないことも多く、ACF・PACFだけでは決め切れない場面もあります。その場合は複数の候補モデルを当てはめてAICで比較するのが実務の定石ですが、準1級では「理想化されたコレログラム」が出題されるため、まずは上記の3パターンを瞬時に判別できるよう訓練しておきましょう。
📚 より深く学ぶなら
時系列解析を体系的に学びたい方には、沖本竜義『経済・ファイナンスデータの計量時系列分析』が定番中の定番です。AR・MA・ARIMA・単位根検定・状態空間モデルまでを数式と直感の両面から解説しており、準1級の出題範囲をほぼカバーします。本記事末尾のランキングセクションで詳しく紹介しています。
Rで学ぶARIMAモデルの実装と診断
ここまでAR・MA・ARIMAの理論を見てきましたが、実際の試験では「Rの出力結果を読み解く」問題も頻出です。ここでは R の組み込みデータセット AirPassengers(1949-1960年の月次航空旅客数)を題材に、データの可視化からモデル選択、残差診断、将来予測までの一連の流れを体験します。本番で問われるポイントは「どの図・どの検定で何を判断するか」です。コードと出力をセットで覚えましょう。
library(forecast)
library(tseries)
data(AirPassengers)
ステップ1:データの可視化と概観把握
まずは生データをプロットして、トレンドと季節性を視覚的に確認します。時系列解析では「まず眺める」が鉄則です。
plot(AirPassengers,
main = "月次航空旅客数 (1949-1960)",
ylab = "旅客数(千人)", xlab = "年")
> 出力結果(プロット)
1949年〜1960年にかけて右肩上がりの上昇トレンドと、毎年夏にピークを持つ周期12ヶ月の季節変動が観察される。
さらに振幅が時間とともに拡大していく(乗法的季節性)。
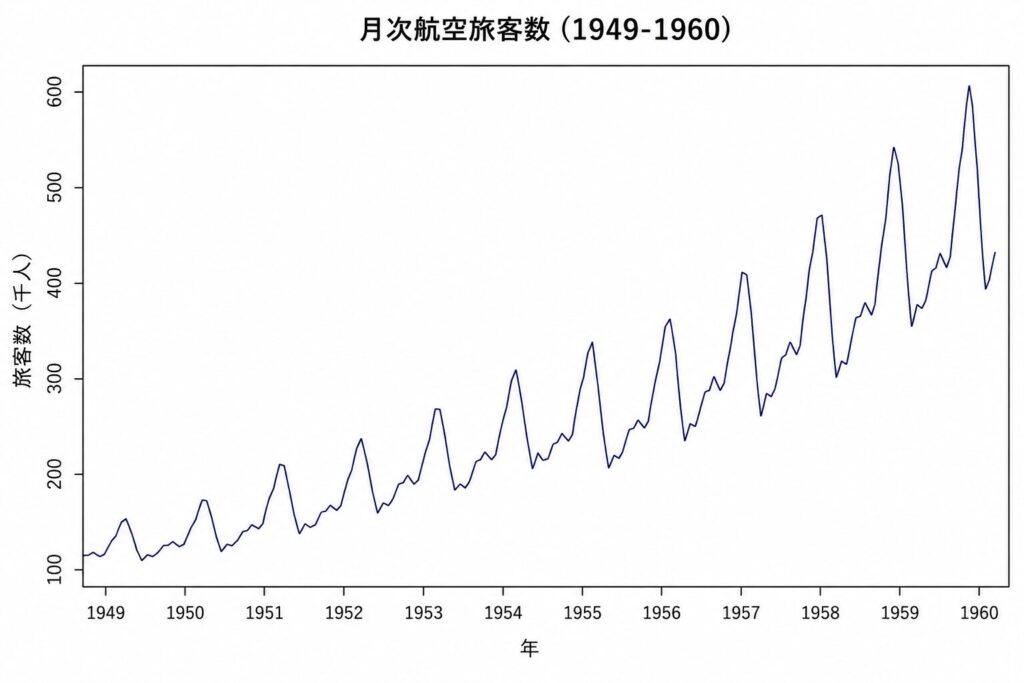
平均が時間とともに増加しているため、このデータは非定常です。さらに振幅も拡大しているので、分散も時間依存している可能性が高く、対数変換(
log(AirPassengers))で分散を安定化させてから扱うのが定石です。準1級では「振幅が広がる→対数変換」というセットも問われます。ステップ2:ADF検定で定常性を確認
視覚で非定常らしいと分かっても、客観的な証拠としてADF(拡張Dickey-Fuller)検定を行います。帰無仮説は「単位根を持つ(非定常)」です。
adf.test(AirPassengers)
> Augmented Dickey-Fuller Test
> data: AirPassengers
> Dickey-Fuller = -1.71, Lag order = 5, p-value = 0.69
> alternative hypothesis: stationary
p値が0.69と大きいため、帰無仮説「単位根あり」を棄却できません。つまりこのデータは非定常と判断します。差分を取って定常化する必要があります。
ステップ3:差分を取って定常化、再度ADF検定
1階差分でトレンドを除去し、季節差分(12ヶ月差)で季節性も除去してから、もう一度ADF検定にかけます。
d1 <- diff(log(AirPassengers)) # 1階差分
d12 <- diff(d1, lag = 12) # 季節差分
adf.test(d12)
> Augmented Dickey-Fuller Test
> data: d12
> Dickey-Fuller = -4.44, Lag order = 5, p-value = 0.01
> alternative hypothesis: stationary
p値が0.01まで下がり、帰無仮説を棄却できます。差分系列は定常と判断でき、これでARIMAモデルの土俵に乗ります。差分の階数(通常差分 d=1、季節差分 D=1)が試験で問われた場合は、この過程を再現できれば即答できます。
ステップ4:ACF/PACFプロットでモデル次数を読み取る
定常化した系列のACF・PACFを描き、AR次数 p と MA次数 q の当たりをつけます。
par(mfrow = c(1, 2))
acf(d12, main = "ACF (差分後)")
pacf(d12, main = "PACF (差分後)")
> 出力結果(コレログラム)
ACF: ラグ1で有意に負、ラグ12付近で再び有意
PACF: ラグ1, 2で有意、その後は信頼区間内に収まる
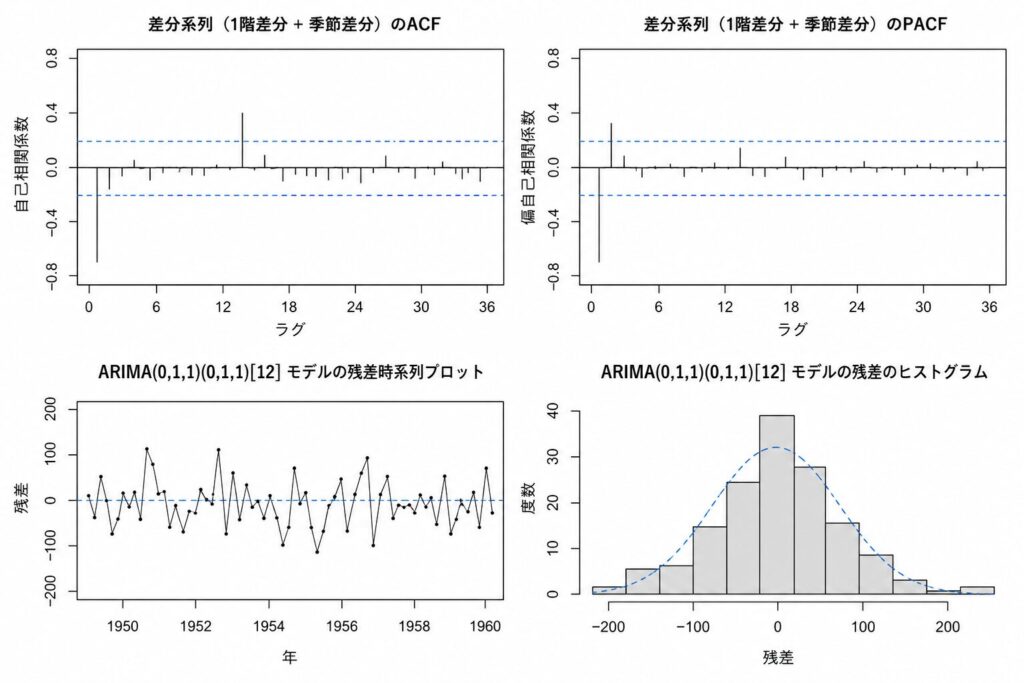
PACFがラグ2まで有意で切れる → AR(2) の候補、ACFがラグ1で大きく出る → MA(1) の候補。さらにラグ12のスパイクが季節成分を示唆します。手動なら SARIMA(2,1,1)(0,1,1)[12] あたりが第一候補です。
ステップ5:auto.arima() で自動モデル選択
手動の当たりをつけたら、auto.arima() でAIC最小化に基づくモデルを自動選択させ、答え合わせをします。
fit <- auto.arima(AirPassengers,
seasonal = TRUE,
lambda = "auto") # 自動でBox-Cox変換
summary(fit)
> Series: AirPassengers
> ARIMA(0,1,1)(0,1,1)[12]
> Box Cox transformation: lambda= 0.0
> Coefficients:
> ma1 sma1
> -0.402 -0.557
> s.e. 0.090 0.073
> sigma^2 = 0.00135: log likelihood = 244.7
> AIC=-483.4 AICc=-483.2 BIC=-474.5
選ばれたのは ARIMA(0,1,1)(0,1,1)[12](通称「航空モデル」)。通常差分1回・季節差分1回・MA(1)・季節MA(1)という、Box & Jenkinsの教科書通りの構造です。
lambda="auto" によって対数変換が自動適用されています。試験で「AirPassengersにARIMAを当てたら何になる?」と問われたら(0,1,1)(0,1,1)[12]と即答できるようにしておきましょう。ステップ6:残差診断(Ljung-Box検定とACF)
モデルが妥当かを確認するには、残差がホワイトノイズ(自己相関なし)かどうかをチェックします。Ljung-Box検定の統計量は以下で定義されます。
\[ Q = n(n+2)\sum_{k=1}^{m}\frac{\hat{\rho}_k^2}{n-k} \]
帰無仮説は「ラグ1〜mまでの自己相関がすべて0」です。p値が大きいほどモデルの当てはまりが良い、と読みます(通常の検定と逆向きなので注意)。
checkresiduals(fit)
Box.test(residuals(fit), lag = 20, type = "Ljung-Box")
> Ljung-Box test
> data: Residuals from ARIMA(0,1,1)(0,1,1)[12]
> Q* = 17.6, df = 18, p-value = 0.48
Ljung-Box検定ではp値が大きい=残差に自己相関なし=モデルOKです。準1級では「p=0.48だからモデルを棄却できない=よく当てはまっている」と判断します。p値が小さいときに「モデルが良い」と勘違いする受験生が多いので、向きを必ず確認しましょう。残差ACFもすべて信頼区間内なら合格です。
ステップ7:将来予測と予測区間の解釈
最後に、フィットしたモデルで24ヶ月先(2年分)を予測します。
fc <- forecast(fit, h = 24)
plot(fc, main = "AirPassengers 24ヶ月先予測")
> Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
> Jan 1961 446.7 431.6 462.4 423.9 470.6
> ...
> Dec 1962 568.9 515.2 628.2 489.3 661.5
予測区間は先に行くほど広がるのがARIMAモデルの特徴です。これは将来の不確実性が累積するためで、「点予測だけ見て安心しない」「80%・95%区間の幅でリスクを語る」のが実務でも試験でも重要です。Box-Cox変換を入れた場合、予測値は自動的に元のスケールに逆変換されて出力される点も押さえておきましょう。
ここまでで、可視化→定常性検定→差分→ACF/PACF→モデル選択→残差診断→予測という時系列解析の標準ワークフローを一通り再現しました。準1級では各ステップの「目的」と「判断基準」がピンポイントで問われるため、コードと出力を結びつけて覚えるのが合格への最短ルートです。
統計検定準1級の典型出題パターンと解法のコツ
ここまでAR・MA・ARIMAモデルの理論的な背景を見てきましたが、いよいよ統計検定準1級での実戦対策に入ります。時系列解析は選択科目の一つとして比較的出題されやすい単元とされており、頻出パターンを押さえておくと得点源になりやすい領域です。逆に言えば、捨ててしまうと選択肢が狭まるため、効率よく要点を押さえておきたいテーマでもあります。
ここでは、過去問・公式問題集・模試などでよく問われる典型パターンを5つに整理し、最後に学習ロードマップとしてまとめます。「どこをどの順番で押さえれば得点に直結するか」が明確になるはずです。
頻出パターンを5つに整理
時系列解析の出題は、無数のバリエーションがあるように見えて、実は5つの典型パターンにほぼ集約されます。まずは全体像を表で俯瞰しましょう。
| パターン | 問われる内容 | 解法のキーワード |
|---|---|---|
| 定常性判定 | 平均・分散・自己共分散から弱定常か判定 | 時点に依存しないか |
| 特性方程式・定常条件 | AR/MAの係数から定常・反転可能性を判定 | 根が単位円外 |
| ACF/PACFと次数 | グラフからAR(p)/MA(q)の次数を推定 | カットオフ・減衰 |
| 差分とARIMA | 差分を取った後の系列が何モデルになるか | ARIMA(p,d,q)→ARMA |
| ホワイトノイズ・単位根 | ランダムウォークと定常過程の違い | 単位根の有無 |
典型パターン①:弱定常性の判定問題
典型パターン①は、ある確率過程が与えられたときに、それが弱定常かどうかを判定する問題です。弱定常性の条件は次の3つでした。
\[ E[X_t] = \mu, \quad V[X_t] = \sigma^2, \quad \mathrm{Cov}(X_t, X_{t+h}) = \gamma(h) \]
つまり平均・分散・自己共分散がいずれも時点tに依存しないことが条件です。出題では「\(X_t = a + b t + \varepsilon_t\)」のように平均がtに依存する形が混ぜられているケースが多く、平均関数を計算して「tが残るか」をチェックするだけで判定できることが多いです。
典型パターン②:特性方程式と定常条件
典型パターン②は、AR/MAモデルの係数から定常条件や反転可能条件を計算する問題です。AR(p)モデルの特性方程式は次式で表されます。
\[ 1 – \phi_1 z – \phi_2 z^2 – \cdots – \phi_p z^p = 0 \]
この方程式のすべての根の絶対値が1より大きい(単位円の外側にある)ときAR過程は定常になります。AR(1)であれば\(|\phi_1| < 1\)というシンプルな条件に帰着します。MA過程は常に定常ですが、反転可能であるためにはMA側の特性方程式の根が単位円外にある必要があります。「AR=定常条件」「MA=反転可能条件」と対応づけて覚えるのがコツです。
典型パターン③:ACF/PACFから次数を推定
典型パターン③は、ACF・PACFのコレログラムを見せられて、AR(p)かMA(q)か、また次数はいくつかを答えさせる問題です。これは前章で扱った対応関係をそのまま使います。
- AR(p):ACFは指数的または振動しながら減衰、PACFはp次でカットオフ
- MA(q):ACFはq次でカットオフ、PACFは減衰
「カットオフ=急にゼロ近辺に落ちる」「減衰=徐々に小さくなる」の見分けが鍵です。
典型パターン④:差分とARIMAの関係
典型パターン④は、非定常な系列に差分を取った結果どうなるかを問う問題です。ARIMA(p,d,q)モデルでd回差分を取ると、定常なARMA(p,q)になります。
\[ (1-L)^d X_t \sim \mathrm{ARMA}(p, q) \]
たとえば「\(X_t\)がARIMA(1,1,0)に従う」と書かれていれば、1階差分\(\nabla X_t = X_t – X_{t-1}\)はAR(1)に従います。トレンドのある経済データや株価などは多くの場合d=1で定常化することを押さえておきましょう。
典型パターン⑤:ホワイトノイズ・ランダムウォーク・単位根
典型パターン⑤は、基本的な確率過程の性質を問う問題です。ホワイトノイズは弱定常、ランダムウォーク\(X_t = X_{t-1} + \varepsilon_t\)は非定常(単位根を持つ)です。AR(1)で\(\phi_1 = 1\)のときが単位根に相当し、分散が時間とともに発散することを計算で示せると安心です。
「PACFがq次でカットオフ」と書いてあったらMAではなくAR(q)の特徴です。ACFとPACFの役割は逆対称になっており、ここで取り違えるとモデル選択を丸ごと間違えます。「PACF=AR、ACF=MA」と語呂で覚えておくのが安全です。
学習ロードマップ:基礎から予測まで
準1級レベルで時系列を得点源にするには、以下の順で学習を進めるのが効率的です。
- 定常性とホワイトノイズの定義を押さえる
- AR・MA・ARMAの定義式と特性方程式を書けるようにする
- ACF/PACFの形と次数の対応を暗記レベルにする
- 差分とARIMAの関係を理解し、単位根との結びつきを把握する
- AIC・BICによるモデル選択の考え方を確認する
- 予測値と予測区間の作り方をRや過去問で実演する
特に③のACF/PACFは図表問題で即得点につながるため、最優先で固めておきたい部分です。
・弱定常の3条件(平均・分散・自己共分散が時点に依存しない)はまず暗記
・特性方程式の根が単位円外=AR定常、MAは常に定常・反転可能条件は別物
・ACFはMAの次数、PACFはARの次数を語る(混同注意)
・ARIMA(p,d,q)はd回差分を取ればARMA(p,q)に戻ると即座に書き換える
実務でのポイント
時系列解析は試験対策として学ぶだけでなく、実務でも幅広く活用されています。製薬業界では臨床試験の経時データの解析や、市販後安全性監視(PMS)における有害事象の月次推移トレンド検知などに用いられます。経済・ファイナンス領域では株価・為替の予測、需要予測、在庫管理がARIMAの王道用途です。
実務で押さえておきたいのは次の3点です。第一に、**まず可視化して非定常性の兆候を確認する**こと。トレンド・季節性・分散の不均一性を肉眼で確かめる作業は、どのような高度なモデルを使う場合でも省略してはいけません。第二に、**ADF検定などの単位根検定で定常性を客観的に判定**してから差分回数を決めること。何階差分すればよいかは目視だけでは判断しきれず、検定で裏付けるのが標準的なプロトコルです。第三に、**残差診断を必ず行う**こと。AIC最小だからといって安心せず、Ljung-Box検定で残差がホワイトノイズに近づいているかを確認することで、モデルの信頼性が大きく変わります。
これらの手順は、Rの`forecast`パッケージや`tseries`パッケージを使えば数行のコードで完結します。逆に言えば、コードの裏側にある「なぜこの検定を使うのか」「どう結果を読むのか」を理解していないと、ツールに使われる側になってしまいます。試験対策をきっかけに、こうした実務的な視点も身につけておくと、現場でも強力な武器になります。
📚 この記事をより深く理解するための参考書籍
統計検定準1級の時系列解析を体系的に学ぶには、以下の書籍が定番です。






関連記事・次のステップ
biostat4869.com には統計検定対策や数理統計に関する記事が公開されています。時系列解析と併せて学習するとさらに理解が深まります。
- 統計検定 準1級・1級 攻略ガイド ― 試験範囲・学習ステップ・よく出るテーマを完全整理 ―:本記事の上位編。準1級・1級全体の試験範囲・学習ステップを俯瞰したい方はまずこちらをご覧ください。
- 統計検定準1級の勉強法:時系列解析を含む準1級全体の学習スケジュール・参考書の選び方を解説しています。
- 統計検定1級の勉強法:準1級の先にある1級を目指す方へ。時系列解析が記述問題で出題される1級対策にも役立ちます。
まとめ
本記事では、統計検定準1級の時系列解析パートを「AR/MA/ARIMAの本質」と「典型出題パターン」という2つの軸で体系的に整理しました。
時系列解析の出発点となるのが**定常性(特に弱定常)**です。平均・分散・自己共分散が時点に依存しないという3条件を満たすことで、過去のデータから将来を予測する統計的根拠が生まれます。続いて学んだ**AR・MA・ARMA・ARIMA**は、いずれも「過去の値またはショックの線形結合」として現在の値を表現するモデルであり、定常条件と反転可能性、差分操作の役割を区別することが理解の鍵でした。
**ACFとPACF**は、データから適切なモデル次数を読み取るための診断ツールです。「ACFはMAの次数、PACFはARの次数」を語るという対応関係を覚えておけば、コレログラム問題は安定して得点できます。Rでの実装では、`AirPassengers`データを題材に、可視化→ADF検定→差分→ACF/PACF→`auto.arima()`→残差診断→予測という標準ワークフローを体験しました。
統計検定準1級では、5つの典型出題パターン(定常性判定・特性方程式・ACF/PACF・差分とARIMA・ホワイトノイズ/単位根)を機械的に判別できるレベルまで仕上げることが、時系列解析を得点源に変える最短ルートです。本記事の内容を**実際の問題演習と往復しながら定着させていただければと思います**。時系列解析の理解は、試験対策にとどまらず、製薬・経済・ファイナンスといった幅広い実務領域での大きな強みになります。最後までお読みいただきありがとうございました。