統計検定準1級 攻略ガイド ― 出題範囲・勉強法・おすすめ参考書を生物統計家が徹底解説 ―

統計検定準1級は、統計学の基礎知識を実務レベルの解析力へと引き上げる、最初の大きなステップです。2級との差は「計算できるかどうか」だけでなく、「なぜその手法を使うのか・結果をどう解釈するか」まで問われる点にあります。製薬・医療・ビジネスなど、実データを扱うあらゆるフィールドで、準1級レベルの統計力は即戦力として機能します。この記事では、試験概要から出題範囲・勉強法・おすすめ参考書まで、生物統計家の視点で徹底的に解説します。
- 統計検定準1級の試験概要(方式・時間・合格基準・受験料)
- 出題範囲と頻出分野の全体マップ、重要度の目安
- 合格までの勉強法・ロードマップ(2級修了後から合格まで)
- 典型出題パターンと例題の解き方(段階的な解答付き)
- 合格者が実際に使ったおすすめ参考書3冊
統計検定準1級とは ― 試験概要と難易度
統計検定準1級は、日本統計学会が主催する検定の中で「2級の上・1級の下」に位置する資格です。2級が「統計学の基本的な概念と計算」を問うのに対し、準1級は各種統計解析法の使い方と結果の正しい解釈まで踏み込んで問われます。1級はさらに統計理論の証明や数理的な深さが要求されるため、実務応用力を証明したい方にとって、準1級は最もコストパフォーマンスの高い資格といえます。
| 項目 | 内容 |
|---|---|
| 試験方式 | CBT方式(通年・全国のテストセンターで受験) |
| 試験時間 | 90分 |
| 問題数 | 25〜30問 |
| 出題形式 | 5肢選択問題、数値入力問題 |
| 合格基準 | 100点満点で60点以上 |
| 受験料 | 一般 8,000円、学割 6,000円(税込) |
| 結果通知 | 試験直後に結果レポート発行、合格証は4〜6週間後に発送 |
難易度については、合格者数と受験者数の比率から、概ね2〜3割程度が合格するとされています。2級と比べると、問われる手法の幅が大幅に広がるうえ、「なぜこの手法なのか」という判断力も試されます。ただし出題範囲は公式に明示されており、計画的に学習すれば着実に合格を狙える試験です。
| グレード | 求められる力 |
|---|---|
| 2級 | 確率・検定・推定の基本概念と計算 |
| 準1級 | 多様な解析手法の選択・実施・結果解釈まで |
| 1級 | 統計理論の数理的証明・高度な推論 |
出題範囲と頻出分野を整理する
準1級の出題範囲は「統計検定2級の内容をすべて含む+応用的な各種統計解析法」と定義されており、詳細は統計検定準1級 出題範囲表(202107版)に準拠しています。単に公式を当てはめる計算力だけでなく、手法の前提条件・適用場面・アウトプットの解釈という一連の流れを理解しているかが問われます。
分野ごとの構成を整理すると、以下のようになります。
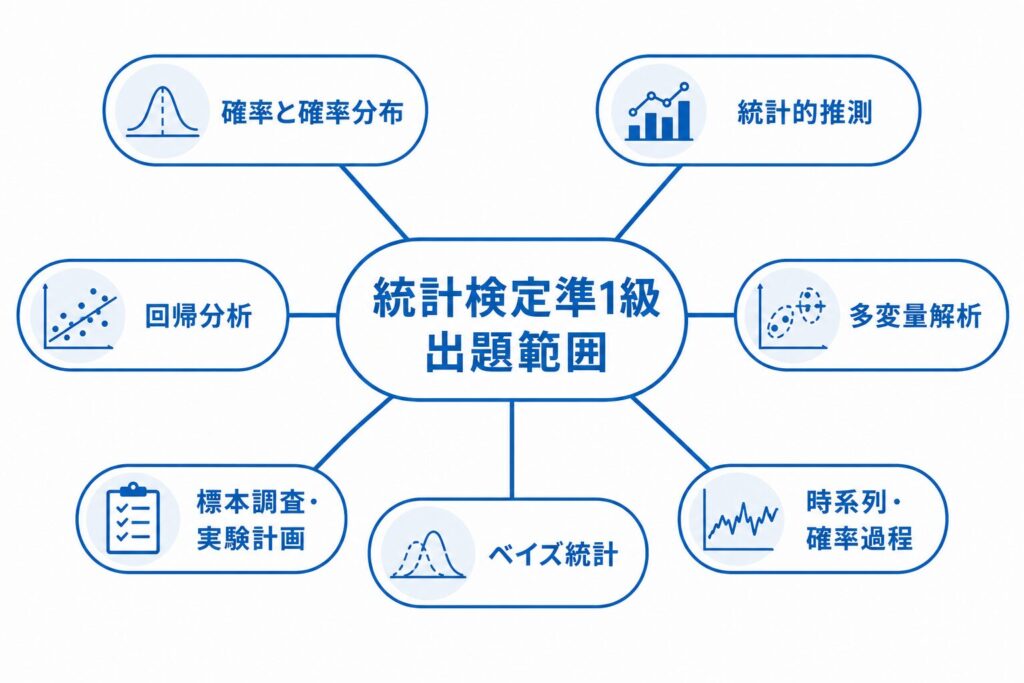
| 分野 | 代表トピック | 重要度の目安 |
|---|---|---|
| 確率と確率分布 | 各種分布(正規・二項・ポアソン等)、期待値・分散、変数変換 | ★★★★☆ |
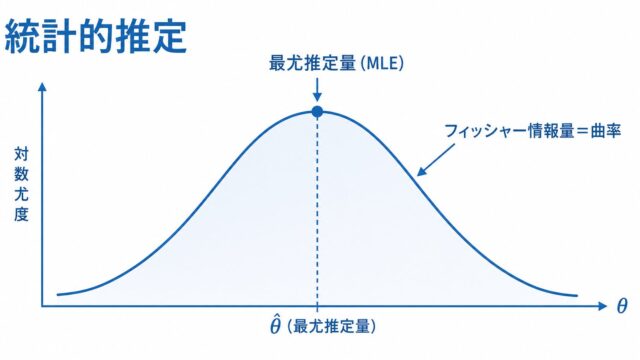
| 統計的推測 | 最尤推定、各種検定(t・χ²・F検定など)、区間推定 | ★★★★★ |
| 回帰分析 | 重回帰、ロジスティック回帰、一般化線形モデル(GLM) | ★★★★★ |
| 多変量解析 | 主成分分析、因子分析、判別分析、クラスター分析 | ★★★★☆ |
| 標本調査・実験計画 | 各種サンプリング、分散分析(ANOVA)、ブロック計画 | ★★★☆☆ |
| ベイズ統計 | 事前・事後分布、ベイズ更新、MAP推定 | ★★★☆☆ |
| 時系列・確率過程 | ARMAモデル、定常性、マルコフ連鎖 | ★★☆☆☆ |
「統計的推測」と「回帰分析」は出題頻度・配点ともに高く、この2分野を確実に押さえるだけで合格ラインに大きく近づきます。特に最尤推定・GLM・ロジスティック回帰は毎回のように出題されるため、手を動かして計算に慣れておくことが重要です。一方、時系列・確率過程は深追いしすぎず、基本概念の把握に留めて他の分野に時間を配分するのが現実的な戦略です。
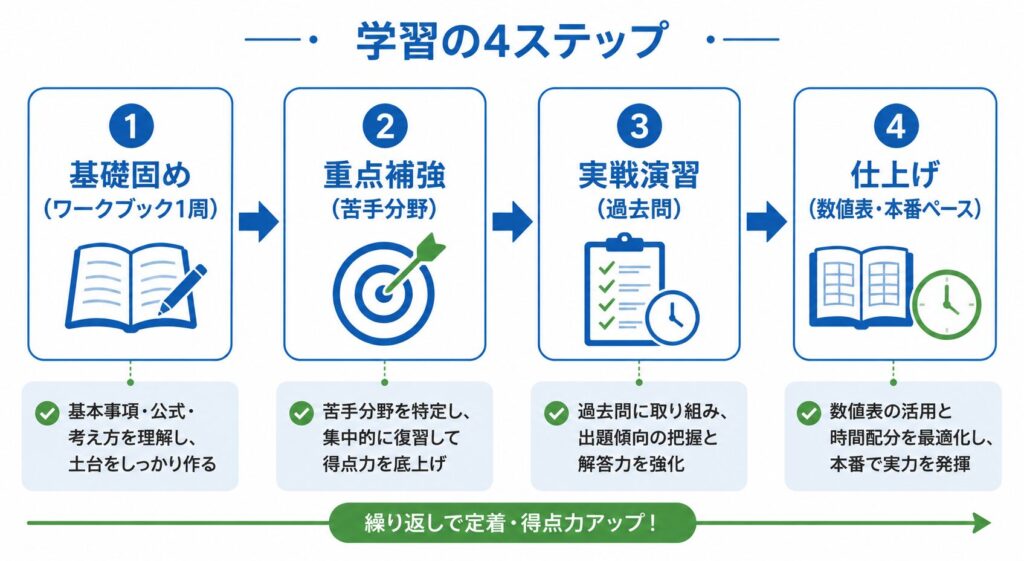
合格までの学習ロードマップと効率的な勉強法
統計検定準1級の合格を目指すには、まず統計検定2級レベルの知識が土台となります。記述統計・確率・推定・検定・単回帰の基礎が不安な方は、準1級の学習に入る前に2級の内容を固め直すことをおすすめします。
学習の進め方
準1級の範囲は広く、独学でカバーするには戦略的な順序が重要です。以下の流れで進めると、着実に実力をつけられます。
ステップ1:公式テキストで全分野を一周する
日本統計学会公式テキスト『統計学実践ワークブック』は、準1級の出題範囲をほぼ網羅した唯一の公式教材です。まずはこの1冊を通読し、各章の例題を必ず手を動かして解くことが大切です。「わかった気になる」だけでは本番に対応できません。計算過程を紙に書き、式変形の流れを体に染み込ませてください。
ステップ2:苦手分野を重点補強する
一周した後は、理解が浅いと感じた分野に集中して取り組みます。多くの受験生が苦戦しやすいのは、多変量解析(主成分分析・因子分析・判別分析)、確率過程(マルコフ連鎖・ポアソン過程)、ベイズ統計の3分野です。これらは公式テキストの記述だけでは不十分なこともあるため、補助的な参考書や講義資料を活用しながら概念の理解を深めましょう。
ステップ3:過去問演習で本番形式に慣れる
公式の過去問題集を使い、90分・25〜30問という本番の時間制約のなかで解く練習を繰り返します。時間配分の感覚は、何度も模擬的に解くことで初めて身につきます。解き終えた後は必ず全問の解説を読み直し、正解した問題も「なぜ正しいか」を言語化するよう心がけてください。
ステップ4:統計数値表と数値入力問題に慣れる
試験会場では統計数値表(正規分布表・t分布表・χ²分布表など)が配布されます。普段の学習からこれらを積極的に使い、「どの表のどの列を見るか」を迷わず引けるよう習熟しておきましょう。数値入力問題は電卓が使えないため、手計算の正確さと素早さも磨いておく必要があります。
学習計画の目安
個人差はありますが、おおよその目安として以下のスケジュールを参考にしてください。2級の習熟度や学習時間によって期間は大きく変わります。
| 期間(目安) | フェーズ | 主な学習内容 | 到達目標 |
|---|---|---|---|
| 1〜2か月目 | 基礎固め | ワークブック全章を通読・例題を手計算で解く | 全分野の概要把握・苦手分野の特定 |
| 2〜3か月目 | 重点補強 | 苦手分野(多変量・確率過程・ベイズ)を集中学習 | 主要分野を自分の言葉で説明できる |
| 3〜4か月目 | 実戦演習 | 過去問を時間制限内で繰り返し解く・弱点補強 | 過去問で安定して60点以上を取れる |
| 試験直前1〜2週間 | 仕上げ | 数値表の引き方確認・公式の最終整理・本番ペース確認 | 試験形式への完全適応 |
分野別の攻略のコツ
準1級では分野によって攻略法が異なります。以下のポイントを意識して学習すると効率的です。
- 確率分布:期待値・分散・モーメント母関数を自分の手で導けるようにしましょう。公式を眺めるだけでなく、二項分布やポアソン分布・正規分布などを積分・級数展開から丁寧に追う習慣が実力につながります。
- 回帰分析:最小二乗法の導出と分散分析表の読み方をセットで理解することが重要です。検定統計量がどこから来るかを説明できるレベルを目指してください。なお、検出力(統計的検定の敏感さ)に関心のある方は、検出力分析(Power Analysis)入門も参考にしてみてください。
- 多変量解析:固有値・固有ベクトルの意味と寄与率の計算をしっかり理解しましょう。主成分分析・因子分析・判別分析は「何を目的とした手法か」を明確に区別して覚えることが大切です。
- 仮説検定:適用条件の判断が問われます。「この状況でどの検定を使うべきか」を正確に選択できるよう、各検定の前提条件(正規性・等分散性・対応の有無など)を体系的に整理しておきましょう。
- 公式の暗記だけで理解が止まっている:公式を記憶していても、適用条件や前提が理解できていないと、見慣れない設問で判断を誤ります。「なぜその公式が使えるか」まで言語化する練習を。
- 手計算のミスを甘く見ている:数値入力問題は部分点がなく、計算ミス1つで失点します。桁のずれや符号ミスに特に注意し、検算の習慣をつけておきましょう。
- 90分の時間配分を練習していない:本番で初めて時間の壁にぶつかる受験生が多くいます。過去問演習では必ずタイマーをセットし、「解けない問題はいったん飛ばす」判断を体に染み込ませてください。
- 2級範囲の取りこぼしが盲点になる:2級の内容(推定・単回帰・基本的な確率計算など)も準1級で出題されます。「2級はもう大丈夫」と思い込まず、基礎的な分野の精度を定期的に確認することが重要です。
準1級の合格に近道はなく、手を動かして計算する学習の積み重ねが最も効きます。テキストを読むだけ・動画を見るだけといったインプット中心の学習に偏らず、1問1問を紙とペンで解き、答え合わせでは「なぜ間違えたか」を必ず言語化する習慣を作りましょう。過去問を2〜3周すると、出題パターンの感覚が養われ、本番での対応力が大きく上がります。
典型出題パターンと例題で解き方を確認する
準1級の試験で問われるのは、公式を丸暗記しているかどうかではありません。与えられた状況に対して「どの手法を選び、どう計算し、得られた数値をどう解釈するか」という一連の流れを、自分の手で最後まで実行できる力です。1級ほど高度な理論証明は求められませんが、3級・2級と比べると扱う手法の幅が一気に広がり、確率分布・回帰・多変量解析を横断的に使いこなす必要があります。
まずは典型的な出題パターンを整理しておきましょう。出題のされ方と、解くために必要な知識をセットで把握しておくと、本番で問題文を読んだ瞬間に「これはあの手法だ」と引き出しを開けられるようになります。
| 出題パターン名 | 問われ方 | 必要な知識 |
|---|---|---|
| 確率分布のパラメータ推定 | 観測データからパラメータを推定させる | 尤度関数・対数尤度・最尤推定 |
| 回帰のあてはまり評価 | モデルの説明力や変数の妥当性を判断させる | 決定係数・自由度調整済み決定係数 |
| 多変量解析の次元縮約 | 主成分の重要度や採用数を判断させる | 固有値・寄与率・累積寄与率 |
| 仮説検定の選択と適用 | 状況に合う検定を選び結論を述べさせる | 検定統計量・有意水準・p値の解釈 |
| 確率・期待値の計算 | 分布の性質から確率や期待値を求めさせる | 確率分布の定義・モーメント・変数変換 |
例題で解き方を確認する
それでは、上の表で挙げたパターンのうち代表的な3つについて、実際の試験で出そうな例題を解いてみましょう。いずれも、手を動かしながら途中式を追い、最後に検算で答えを確かめる流れを意識してください。
まずは「確率分布のパラメータ推定」の典型である最尤推定の問題です。
ある装置5台が故障するまでの時間が、互いに独立に指数分布 \(\mathrm{Exp}(\lambda)\)(確率密度 \(f(x)=\lambda e^{-\lambda x},\ x\ge 0\))に従うとします。観測値が 2, 4, 3, 6, 5(単位:年)のとき、\(\lambda\) の最尤推定量 \(\hat\lambda\) と、平均故障時間の推定値を求めてみましょう。
独立な観測値の同時確率(尤度)は、各データの確率密度の積で表せます。尤度関数は \(L(\lambda)=\prod_{i=1}^{5}\lambda e^{-\lambda x_i}=\lambda^{5}\exp(-\lambda\sum x_i)\) となります。積の最大化は扱いにくいので、対数をとって和の形に直すのが定石です。対数尤度は \(\ell(\lambda)=5\ln\lambda-\lambda\sum x_i\) です。
データの合計は \(\sum x_i=2+4+3+6+5=20\) です。これを \(\lambda\) で微分してゼロとおくと、\(\frac{d\ell}{d\lambda}=\frac{5}{\lambda}-\sum x_i=0\) より \(\hat\lambda=\frac{5}{\sum x_i}=\frac{5}{20}=0.25\)(/年)が得られます。指数分布の平均は \(1/\lambda\) なので、平均故障時間は \(1/\hat\lambda=4\) 年です。
検算をしておきましょう。二階微分は \(\frac{d^2\ell}{d\lambda^2}=-\frac{5}{\lambda^2}<0\) なので、求めた点は確かに最大値です。また標本平均 \(\bar x=20/5=4\) は \(1/\hat\lambda\) と一致しており、指数分布の最尤推定量が「標本平均の逆数」になるという性質とも整合しています。
答え:\(\hat\lambda=0.25\)/年、平均故障時間4年。
次は「回帰のあてはまり評価」です。決定係数は説明変数を増やすほど見かけ上は大きくなってしまうため、変数の数を考慮した自由度調整済み決定係数で評価する場面がよく出題されます。
標本サイズ \(n=20\)、説明変数の数 \(p=3\) の重回帰分析で、決定係数 \(R^2=0.80\) が得られました。自由度調整済み決定係数 \(\bar R^2\) を求めてみましょう。
自由度調整済み決定係数の公式は \(\bar R^2=1-(1-R^2)\dfrac{n-1}{n-p-1}\) です。\((1-R^2)\) は「説明できなかった割合」で、これに自由度の比を掛けて補正するイメージを持つと覚えやすくなります。
それぞれの値を代入していきましょう。\(\bar R^2=1-(1-0.80)\times\dfrac{20-1}{20-3-1}=1-0.20\times\dfrac{19}{16}=1-0.20\times1.1875=1-0.2375=0.7625\) となります。
検算です。自由度調整済み決定係数は、無意味な変数を増やしたときのペナルティを織り込むため、通常の決定係数より小さくなるはずです。実際 \(0.80>0.7625\) となっており、この性質と整合しています。
答え:\(\bar R^2=0.7625\)(約0.763)。
最後は「多変量解析の次元縮約」、主成分分析の寄与率を求める問題です。何個の主成分を採用すれば十分かを判断する場面で、寄与率と累積寄与率は欠かせない指標になります。
4つの変数からなるデータに主成分分析を適用し、相関行列の固有値が \(\lambda_1=2.0,\ \lambda_2=1.2,\ \lambda_3=0.5,\ \lambda_4=0.3\) となりました。第1主成分の寄与率と、第2主成分までの累積寄与率を求めてみましょう。
寄与率とは「その主成分が全体の分散のうちどれだけを説明しているか」を表す割合で、各固有値を固有値の合計で割って求めます。まず固有値の合計を計算すると \(2.0+1.2+0.5+0.3=4.0\) です。
第1主成分の寄与率は \(\dfrac{2.0}{4.0}=0.50\)、つまり50%です。第2主成分の寄与率は \(\dfrac{1.2}{4.0}=0.30\)(30%)なので、第2主成分までの累積寄与率は \(\dfrac{2.0+1.2}{4.0}=\dfrac{3.2}{4.0}=0.80\)、すなわち80%となります。
検算をしておきましょう。相関行列を用いた主成分分析では、固有値の和は変数の数に等しくなります。実際 \(2.0+1.2+0.5+0.3=4.0\) で、変数の数4と一致しているので計算に矛盾はありません。
答え:第1主成分の寄与率50%、第2主成分までの累積寄与率80%。
3問に共通するのは、公式を眺めるだけでなく、実際に数値を代入して最後まで計算しきり、二階微分の符号や指標の大小関係といった性質で検算する姿勢です。準1級では「どの手法を使うべきか」を見抜く判断力が合否を分けるので、問題文の条件(独立か、変数の数はいくつか、相関行列か共分散行列か)を丁寧に読み取り、適用条件まで確認する習慣をつけておきましょう。
📚 統計検定準1級対策におすすめの参考書籍
準1級の合格を目指すうえで、土台となるテキスト・演習書・理論書の3冊を揃えることが最短ルートです。それぞれの役割を理解したうえで、学習フェーズに合わせて使い分けてみてください。






次に読みたい関連記事
準1級の学習と並行して、以下の記事も参考にしてみてください。
- 効果量を理解すると統計が一気に実務的になる — 準1級でも問われる効果量の概念を、実務視点から直感的に解説しています。
- 検出力分析(Power Analysis)入門 — 検定力・第二種の誤り・サンプルサイズ設計を丁寧に解説した入門記事です。
- 一元配置分散分析(One-way ANOVA)の数理的導入とRによる実装 — 準1級頻出の分散分析について、数理的導入からR実装まで一気通貫で学べます。
まとめ
統計検定準1級は、確率論・推測統計・多変量解析・時系列解析・機械学習まで幅広い範囲をカバーする試験であり、単なる計算スキルにとどまらず、統計的思考の深さそのものが問われます。学習の進め方としては、ワークブックで体系的なインプットを行い、公式問題集で本番形式の演習を重ねつつ、理論に迷ったときは久保川先生の教科書で補強するという流れが効果的です。準1級で培われる推定・検定・モデリングの実力は、製薬・医療・データサイエンスなど実務の現場でも直接活かせる土台となります。本記事の内容を参考に、ぜひ合格に向けた学習を着実に進めていただければと思います。