検出力分析(Power Analysis)入門 ― サンプルサイズ設計に欠かせない基礎知識をSAS・Rで実装 ―
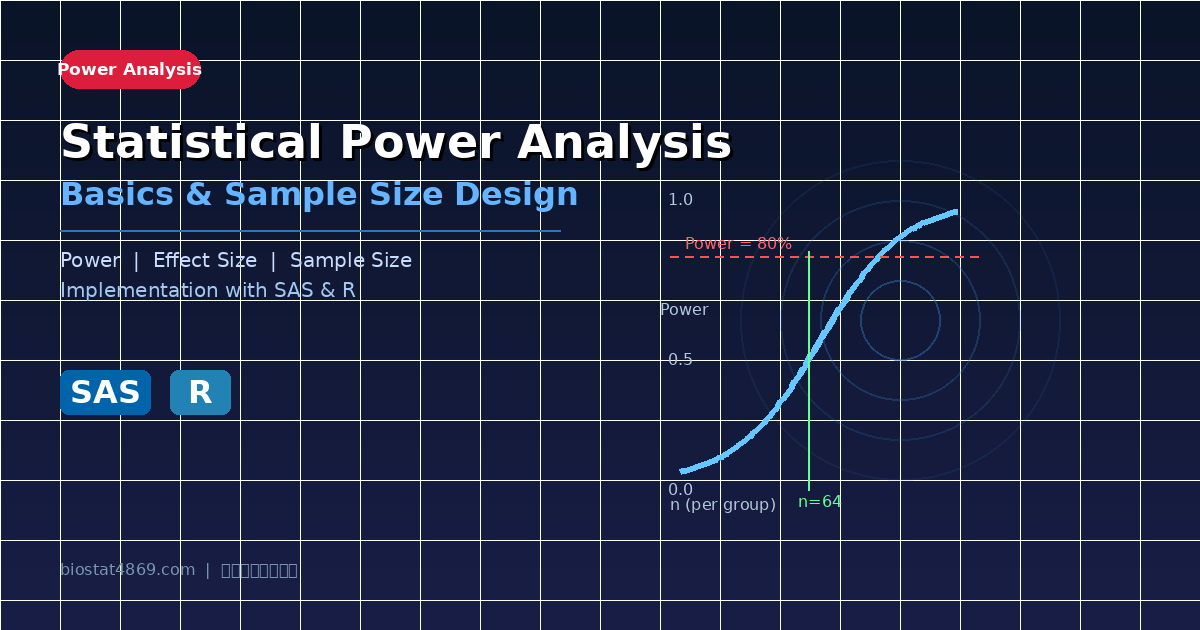
臨床試験や研究計画においてサンプルサイズを決定する場面では、検出力分析(Power Analysis)が極めて重要になります。「何人集めれば十分か」という問いに対して、統計的な根拠をもって答えるための手法が検出力分析であり、規制当局(FDA・EMA・PMDA)への試験計画書提出においても必須の内容です。
検出力分析は一見シンプルに見えますが、効果量・有意水準・検出力・サンプルサイズという4つのパラメータが相互に依存しており、試験デザインや仮説の種類によってアプローチが変わります。製薬企業の生物統計担当者にとって日常業務に直結するテーマであり、SAS・Rでの実装も実務上欠かせません。
本記事では、検出力分析の基本概念を整理したうえで、代表的な検定(2標本t検定・カイ二乗検定)を題材に、数式・RコードおよびSASコードを交えてわかりやすく解説します。
検出力分析の基本概念
4つの核となるパラメータ
検出力分析は以下の4つのパラメータの関係を扱います。これらは相互に決定し合うため、3つが決まれば残りの1つが計算できます。
| パラメータ | 記号 | 一般的な設定値 | 説明 |
|---|---|---|---|
| 有意水準(第1種の誤り) | α | 0.05 | 帰無仮説が真であるのに棄却する確率 |
| 第2種の誤り | β | 0.10〜0.20 | 対立仮説が真であるのに棄却しない確率 |
| 検出力(Power) | 1-β | 0.80〜0.90 | 真の効果を正しく検出できる確率 |
| 効果量(Effect Size) | δ, ES | 試験・疾患により異なる | 「検出したい差・関連の大きさ」を標準化した指標 |
2種類の誤りと検出力の関係
| 帰無仮説 H₀ が真 | 対立仮説 H₁ が真 | |
|---|---|---|
| H₀ を棄却しない(検定非有意) | ✅ 正しい判断(確率:1-α) | ❌ 第2種の誤り(確率:β) |
| H₀ を棄却する(検定有意) | ❌ 第1種の誤り(確率:α) | ✅ 正しい判断=検出力(確率:1-β) |
製薬臨床試験では一般に α = 0.05(両側)、検出力 1-β = 0.80 または 0.90 が設定されます。検出力80%とは「真に有効な薬剤を80%の確率で統計的に有意と判定できる試験設計」を意味します。
数理的背景
各群 n 人の2標本t検定(両側)において、平均差 δ、標準偏差 σ(等分散仮定)のとき、必要サンプルサイズは以下で近似されます。
\[n = \frac{2\sigma^2(z_{\alpha/2} + z_{\beta})^2}{\delta^2}\]
ここで zα/2 は有意水準 α に対応する標準正規分布の上側パーセント点、zβ は第2種の誤り β に対応するパーセント点を意味します。たとえば α = 0.05(両側)では zα/2 = 1.96、検出力 80%(β = 0.20)では zβ = 0.842 となります。
効果量(Cohen’s d)は「検出したい差を標準化した指標」です。
\[d = \frac{\delta}{\sigma} = \frac{\mu_1 – \mu_2}{\sigma}\]
| Cohen’s d | 効果の大きさ | 臨床的目安 |
|---|---|---|
| 0.2 | 小(small) | 微細だが意味のある差 |
| 0.5 | 中(medium) | 明確に視認できる差 |
| 0.8 | 大(large) | 顕著な差 |
Rによる実装
ステップ1:pwrパッケージのインストールと基本操作
Rでは pwr パッケージを用いることで、主要な検定のサンプルサイズ・検出力計算を簡潔に実行できます。
# pwrパッケージのインストール(初回のみ)
install.packages("pwr")
library(pwr)
# 2標本t検定:サンプルサイズの計算
result_n <- pwr.t.test(
d = 0.5,
sig.level = 0.05,
power = 0.80,
type = "two.sample",
alternative = "two.sided"
)
print(result_n) Two-sample t test power calculation
n = 63.76576
d = 0.5
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group📝 解釈:Cohen’s d = 0.5(中程度の効果量)、有意水準5%(両側)、検出力80%の条件下では、各群64人(合計128人)が必要と計算されます。実務では ceiling 関数で切り上げ、さらに脱落率を見越して1.1〜1.2倍のマージンを加えることが一般的です。
ステップ2:検出力の計算(n固定時)
# 各群50人に固定した場合の検出力を計算
result_power <- pwr.t.test(
n = 50,
d = 0.5,
sig.level = 0.05,
type = "two.sample",
alternative = "two.sided"
)
print(result_power) Two-sample t test power calculation
n = 50
d = 0.5
sig.level = 0.05
power = 0.6969804
alternative = two.sided
📝 解釈:各群50人(合計100人)では検出力は約70%にとどまります。臨床試験では検出力80%以上が求められるため、この設計は統計的に不十分と評価されます。規制当局からの指摘事項になり得るため、目標検出力を満たす設計が不可欠です。
ステップ3:感度分析(検出力曲線の描画)
library(ggplot2)
d_seq <- seq(0.2, 1.0, by = 0.05)
n_seq <- sapply(d_seq, function(d) {
ceiling(pwr.t.test(d = d, sig.level = 0.05, power = 0.80,
type = “two.sample”)$n)
})
df_sens <- data.frame(effect_size = d_seq, n_per_group = n_seq)
ggplot(df_sens, aes(x = effect_size, y = n_per_group)) +
geom_line(color = “#2c7bb6”, linewidth = 1.2) +
geom_point(color = “#2c7bb6”, size = 2.5) +
geom_vline(xintercept = c(0.2, 0.5, 0.8), linetype = “dashed”, color = “gray50”) +
labs(
title = “効果量とサンプルサイズの関係(検出力80%、α=0.05両側)”,
x = “Cohen’s d(効果量)”,
y = “必要サンプルサイズ(各群)”
) +
theme_minimal(base_size = 13)
📝 解釈:d = 0.2(小効果)では各群約394人が必要な一方、d = 0.8(大効果)では約26人で済みます。感度分析により、効果量の仮定がずれた場合のリスクを事前に評価できます。
ステップ4:カイ二乗検定のサンプルサイズ計算
# 奏効率:対照群30%、治療群50%
p1 <- 0.30
p2 <- 0.50
w <- ES.w2(matrix(c(p1, 1 - p1, p2, 1 - p2) / 2, nrow = 2))
cat(sprintf("Cohen's w = %.4f
", w))
result_chi <- pwr.chisq.test(w = w, df = 1, sig.level = 0.05, power = 0.80)
print(result_chi)Cohen's w = 0.2085
Chi squared power calculation
w = 0.2085
df = 1
N = 182.3591
sig.level = 0.05
power = 0.8
NOTE: N is the *total* number of observations
📝 解釈:対照群30%・治療群50%の奏効率差を検出するには合計183人(各群約92人)が必要です。二項分布を用いた正確な計算が必要な場合は TrialSize パッケージも参考になります。
SASによる実装(PROC POWER)
2標本t検定
/* 2標本t検定:サンプルサイズ計算 */
PROC POWER;
TWOSAMPLEMEANS
MEANDIFF = 5
STDDEV = 10
ALPHA = 0.05
POWER = 0.80
SIDES = 2
NTOTAL = .;
RUN;
Actual Power N Total
0.802 128📝 解釈:Rと同様に合計128人(各群64人)という結果が得られます。SASでは “Actual Power”(80.2%)として達成検出力も確認できる点が実務上有用です。
カイ二乗検定(奏効率の比較)
/* カイ二乗検定:2群の割合比較 */
PROC POWER;
TWOSAMPLEFREQ
TEST = PCHI
GROUPPROPORTIONS = (0.30 0.50)
ALPHA = 0.05
POWER = 0.80
SIDES = 2
NTOTAL = .;
RUN;
Actual Power N Total
0.806 182📝 解釈:合計182人(Actual Power = 80.6%)が必要です。Rとの1人の差は正規近似の丸め方の違いによるものです。PROC POWER はGUI操作にも対応しており、計画書添付用プロットも自動生成できます。
感度分析:シナリオ比較表
| Cohen’s d | α=0.05 / Power=0.80 | α=0.05 / Power=0.90 | α=0.025 / Power=0.80 | α=0.025 / Power=0.90 |
|---|---|---|---|---|
| 0.2(小) | 394 | 527 | 504 | 659 |
| 0.5(中) | 64 | 86 | 82 | 107 |
| 0.8(大) | 26 | 34 | 33 | 43 |
検出力を80%から90%に上げると必要サンプルサイズは概ね1.3〜1.4倍になります。試験計画の段階でこのような複数シナリオを提示することは、スポンサー・規制当局との合意形成においても有益です。
実務でのポイント
① 効果量の設定根拠を明確にする
効果量は過去の文献・先行試験・パイロットスタディから設定します。「臨床的に意味のある差(MCID)」を科学的根拠に基づいて設定することが、規制当局への説明可能性を高めます。
② 脱落・プロトコル逸脱を考慮したマージンを設ける
脱落率・解析対象外率を踏まえたインフレーション(例:÷0.85)を適用します。試験計画書には「期待される脱落率〇%を想定し、合計〇人を組み入れる」と明記することが一般的です。
③ 多重比較・複数エンドポイントへの対応
複数の主要評価項目がある場合はファミリーワイズエラー率(FWER)の制御(Bonferroni法・Hochberg法等)が必要です。これにより必要サンプルサイズも増大するため、複数エンドポイントを見越した検出力分析が求められます。
④ SASとRの使い分け
規制提出資料にはSAS(PROC POWER)が多用される一方、感度分析の可視化・柔軟なレポート作成ではRが優れています。両ツールで結果を照合することがバリデーションの観点からも推奨されます。
まとめ
本記事では、検出力分析(Power Analysis)の基本概念から始まり、有意水準・検出力・効果量・サンプルサイズという4つのパラメータの関係を整理しました。2標本t検定・カイ二乗検定を例に数理的な背景を示したうえで、RのpwrパッケージおよびSASのPROC POWERを用いた具体的な実装手順を解説しました。
検出力分析は、臨床試験計画における「何人集めれば十分か」という問いへの統計的な回答であり、科学的・倫理的な観点からも極めて重要な工程です。アンダーパワーな試験は真の効果を見逃すリスクがあり、オーバーパワーな試験は不必要な被験者負担を生みます。適切なサンプルサイズ設計を通じて、効率的かつ信頼性の高い臨床試験を実現していただければと思います。
次回は、複数エンドポイントを考慮した同時検出力(Conjunctive Power)の計算方法を紹介します。単一エンドポイントの検出力分析では対応できない、より複雑な試験デザインへの応用についても解説する予定です。
参考書籍