p値とは何か?― 統計検定でも実務でも誤解されがちな概念をやさしく解説 ―

- p値とは何の確率を表しているのか(直感的な意味と数式での定義)
- 初学者が陥りやすい「p値にまつわる3つの誤解」
- Rでp値を計算・シミュレーションして体感する方法
- ASA声明・p-hacking・ICH E9 など、製薬・研究の実務で押さえたい注意点
はじめに
論文を読んでいても、製薬企業の解析報告書を見ても、「p = 0.03 だったので有意」「p > 0.05 だったので差はない」といった表現が当たり前のように登場します。しかしいざ「p値って何ですか?」と問われると、正確に答えられる方は意外と少ないものです。
p値(ピーち、p-value)は仮説検定の中心にある指標であり、統計検定2級・準1級の頻出論点であるだけでなく、製薬企業のメディカルライティング・論文査読・FDA や PMDA への規制対応でも頻繁に登場します。一方で、誤った解釈のまま使われてしまうケースも非常に多く、米国統計学会(ASA)が公式声明を出すほどの問題になっています。
本記事では、統計を学び始めた大学生・社会人や、製薬企業で初めて統計解析に触れる方を対象に、p値を直感的に理解し、よくある誤解を避けるための基礎知識を体系的に解説します。Rのコードも交えて手を動かしながら学べる構成にしましたので、ぜひRStudioを開きながら読み進めてみてください。
p値の正体 ― 「データが偶然得られる確率」ってどういう意味?
統計の入門書を開くと真っ先に登場するのが「p値」です。論文や報告書でも「p < 0.05 だったので有意差あり」といった表現を目にしますが、いざ「p値って何の確率ですか?」と聞かれると、答えに詰まってしまう方も少なくないのではないでしょうか。ここではまず、難しい数式に入る前に、身近なたとえ話からp値の正体に迫ってみます。 たとえば、目の前に1枚のコインがあったとします。あなたはそのコインを10回投げました。すると、なんと9回も表が出たのです。このとき、ふと「このコイン、ちょっとおかしくない?」「もしかしてイカサマじゃ…?」と疑いたくなりますよね。p値とは、まさにこの「疑いの気持ち」を数値に翻訳する道具だと考えると、ぐっと理解しやすくなります。
ここで統計の世界では、最初に「とりあえずコインは公平だと仮定してみよう」という出発点を置きます。これを 帰無仮説(ききむかせつ、H₀) と呼びます。帰無仮説とは「差がない・効果がない・偏りがない」という、いわば”おとなしい仮説”のことです。一方で「いや、このコインはやっぱり偏っているはずだ」と主張する側の仮説を 対立仮説(たいりつかせつ、H₁) と呼びます。
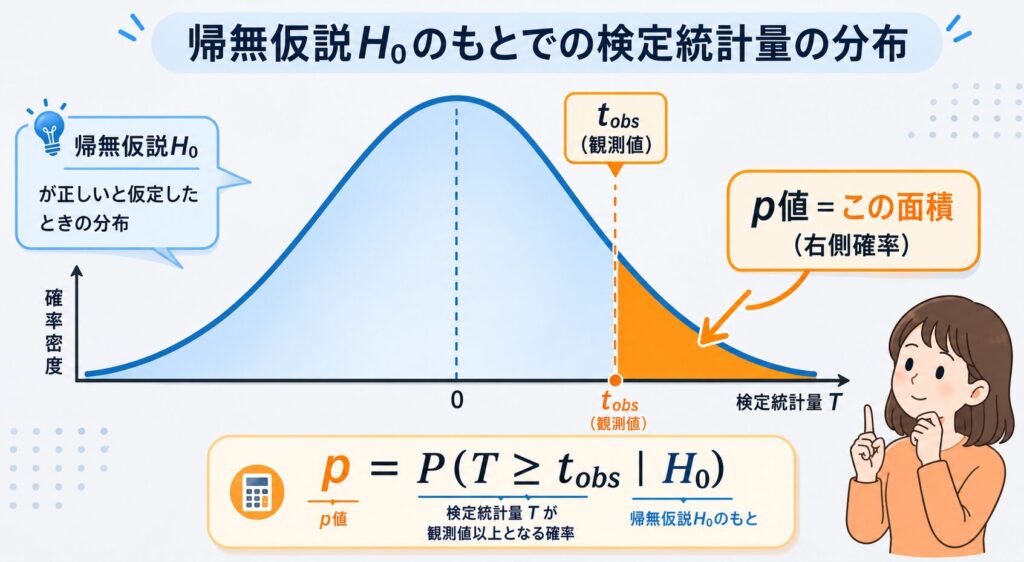
そのうえで、p値は次のように定義されます。
> 「帰無仮説 H₀ が正しいと仮定したとき、いま観測されたデータと同じか、それ以上に極端な結果が得られる確率」
これを数式で書くと、次の1行に凝縮されます。
\[ p = P(T \geq t_{obs} \mid H_0) \]
少し記号が並びましたが、意味はシンプルです。\(T\) は「データから計算される検定統計量(けんていとうけいりょう)」、\(t_{obs}\) は「今回実際に観測された値」、\(\mid H_0\) は「帰無仮説が正しいという条件のもとで」を表します。つまり「H₀ が本当だとしたら、今回みたいに極端な(あるいはもっと極端な)データが偶然出てくる確率はどれくらいか?」を表しているわけです。
先ほどのコインに当てはめてみましょう。もし本当に公平なコイン(H₀)だとしたら、10回中9回以上表が出る確率はおよそ1.1%です。つまり p ≈ 0.011 ということになります。「公平だと信じるには、ちょっと珍しすぎる結果」だと数字が告げているのです。
p値は「対立仮説が正しい確率」でも「帰無仮説が間違っている確率」でもありません。あくまで『帰無仮説が正しいと仮定したうえで、今回のデータがどれくらい珍しいか』を測る指標です。ここを取り違えると、後の解釈で大きく道を誤ってしまいます。
ここから自然に、検定のロジックが見えてきます。p値が小さいということは「帰無仮説のもとでは、こんなデータはめったに出ないはず」という状況です。それなのに現実に観測されてしまった――ならば「そもそも帰無仮説(公平なコインだという仮定)の方を疑った方がよさそうだ」と考えるわけです。逆にp値が大きければ、「今回くらいのズレは、H₀ のもとでも十分起こりうる範囲だね」と判断し、帰無仮説をあえて否定する理由は弱まります。
「極端な結果」というのは、両側検定なら「観測値より大きい側+小さい側の両方」、片側検定なら「片方の裾だけ」を指します。検定の設計によって”極端”の向きが変わる点も、p値を読むときの大切なポイントです。
このように、p値とは決して魔法の数字ではなく、「もし差がなかったとしたら、このデータはどれくらい珍しいだろう?」という問いに対する、確率という形での回答なのです。
p値にまつわる3つの誤解 ― 統計検定でも実務でもよくある勘違い ―
p値は便利な道具ですが、解釈を誤ると研究結果や臨床判断を歪めることになります。ここでは初学者が陥りがちな3つの誤解を整理します。統計検定の試験対策としても、製薬・医療現場での実務判断としても、ここを正しく理解しているかどうかが分かれ目になります。
誤解①:p値は「帰無仮説が正しい確率」ではない
最も多い誤解が「p = 0.03 だったから、帰無仮説(H₀:差がない)が正しい確率は3%だ」という解釈です。これは完全な間違いです。
正しくは、p値とは「帰無仮説が真であると仮定したとき、観測されたデータ以上に極端な結果が得られる確率」を指します。あくまで「H₀が真という条件付き確率」であって、「H₀が真である確率そのもの」ではありません。
たとえば新薬の試験で対照群との差を検定し、p = 0.03 が得られたとします。これは「差がない世界が本当だとしたら、今回のような結果(あるいはそれ以上に極端な差)が偶然出る確率が3%」という意味です。「新薬に効果がない確率が3%」でも「効果がある確率が97%」でもありません。
「H₀が正しい確率」を求めたい場合は、ベイズ統計の事後確率(posterior probability)が必要です。頻度論のp値からは原理的に算出できないことを覚えておきましょう。
誤解②:p < 0.05 で「効果がある」とは限らない
「p < 0.05 なら効果あり、実用的に意味がある」という思い込みも危険です。p値はあくまで「偶然では説明しにくいか」を示すだけで、効果の大きさ(効果量=effect size、対照群との差の大きさを標準化した指標)は教えてくれません。
ポイントはサンプルサイズの影響です。被験者数が極端に大きい試験では、臨床的にはほとんど意味のない小さな差でも統計的有意(p < 0.05)になってしまいます。 たとえば降圧薬の試験で、10,000例を集めて収縮期血圧が平均0.5 mmHgだけ下がり、p = 0.01 が得られたとします。統計的には有意ですが、0.5 mmHgの低下が臨床的に意味を持つかは別問題です。p値だけでなく、効果量と95%信頼区間(confidence interval)を必ずセットで確認する習慣が重要です。
誤解③:p > 0.05 で「差がない」とは限らない
逆方向の誤解として「p = 0.20 だったから、両群に差はない」と結論づけてしまうケースも頻発します。「有意でない(not significant)」は「差がないことを証明した」ではないのです。
ここで関わってくるのが検出力(power、本当に差があるときにそれを検出できる確率)の問題です。サンプルサイズが小さい・ばらつきが大きい・効果量が見積もりより小さいといった条件では、本当は差があっても検出できず、p > 0.05 になります。
たとえば30例の小規模試験で新薬と既存薬を比較し、p = 0.18 が得られたとします。これは「差がない証拠」ではなく「今回のサンプルサイズでは差を捉えきれなかった」可能性が十分にあります。同等性を主張したい場合は、非劣性試験や同等性試験の設計と、事前の検出力計算(sample size calculation)が必須となります。
| よくある誤解 | 正しい解釈 |
|---|---|
| p = 0.03 は「帰無仮説が正しい確率3%」 | H₀が真と仮定したとき、観測値以上に極端な結果が出る確率が3% |
| p < 0.05 なら「効果がある」 | 統計的有意と臨床的意義は別。効果量と信頼区間で大きさを確認する |
| p > 0.05 なら「差がない」 | 検出力不足の可能性あり。「差を示せなかった」だけで「差がない証拠」ではない |

これら3つの誤解は、統計検定2級・準1級の頻出論点であるだけでなく、製薬企業のメディカルライティングや論文査読でも繰り返し指摘される重要ポイントです。p値を「魔法の判定基準」ではなく「条件付き確率の一指標」として扱う姿勢が、誤った結論を避ける第一歩となります。
Rで体感するp値 ― irisデータとシミュレーションで理解する ―
ここまでで「p値とは何か」「どう解釈すべきか」を概念として整理してきました。本章ではRを使って実際にp値を計算し、さらに「帰無仮説が真のとき p値はどう分布するか」をシミュレーションで確認します。Rを未経験の方でも、RStudioにそのままコピペで動くコードを掲載していますので、ぜひ手を動かしながら読み進めてみてください。数字を眺めるだけでなく自分のPCで再現することで、p値の正体がぐっと身近になります。
irisデータでt検定を実行してみる
最初は誰もが一度は触れるRの組み込みデータセット iris を使い、アヤメ3品種のうち setosa と versicolor の がく片の長さ(Sepal.Length) に差があるかを2標本t検定で調べてみます。帰無仮説 H₀ は「2品種の Sepal.Length の平均は等しい」です。
# irisデータからsetosaとversicolorだけを抽出してt検定
data <- iris[iris$Species %in% c("setosa", "versicolor"), ]
result <- t.test(Sepal.Length ~ Species, data = data)
print(result)
実行すると、次のような出力が得られます。
> print(result)
Welch Two Sample t-test
data: Sepal.Length by Species
t = -10.521, df = 86.538, p-value < 2.2e-16
alternative hypothesis: true difference in means between group setosa and group versicolor is not equal to 0
95 percent confidence interval:
-1.1057074 -0.7542926
sample estimates:
mean in group setosa mean in group versicolor
5.006 5.936
出力の
p-value < 2.2e-16 はRが表示できる最小値レベルで、実質的に「ほぼ0」という意味です。これは「もしH₀(setosaとversicolorのSepal.Lengthの平均が等しい)が正しいとしたら、今回観測されたような差(5.006 vs 5.936)が偶然生じる確率はほぼ0」ということを示しています。t統計量は t = -10.521 と非常に大きく、95%信頼区間 [-1.106, -0.754] も0を含みません。よってH₀は明確に棄却され、2品種のがく片長には統計的に意味のある差があると判断できます。帰無仮説が真のとき、p値はどう分布する?
次が本章の山場です。先ほど「p値はH₀が正しいときに観測される確率」と説明しましたが、ではH₀が 本当に正しい とき、p値はどんな分布になるのでしょうか。同じ正規分布から2群を1,000回サンプリングし、毎回t検定をしてp値を集めてみます。
# 帰無仮説が真のときのp値分布シミュレーション
set.seed(123)
n_sim <- 1000
pvals <- numeric(n_sim)
for (i in 1:n_sim) {
x <- rnorm(30, mean = 0, sd = 1)
y <- rnorm(30, mean = 0, sd = 1) # 同じ分布(=H0が真)
pvals[i] <- t.test(x, y)$p.value
}
# ヒストグラムを描画
hist(pvals, breaks = 20, main = "帰無仮説が真のときのp値分布",
xlab = "p値", col = "#2E86C1", border = "white")
abline(v = 0.05, col = "#F39C12", lwd = 2, lty = 2)
# p < 0.05 となった割合
mean(pvals < 0.05)
最後の行を実行すると、次のような結果が表示されます。
> mean(pvals < 0.05)
[1] 0.049
ヒストグラムを見ると、p値は0から1の範囲にほぼ平坦に散らばっているはずです。どこかの値に山ができることはなく、 0〜1の一様分布 に近い形が描かれます。オレンジの破線(p = 0.05)の左側にも、棒が他の領域と同じ高さで並んでいる点に注目してください。
2群が まったく同じ分布 から来ているにもかかわらず、
mean(pvals < 0.05) は約 0.049(理論値 0.05 に非常に近い)となりました。これは「H₀が真であっても、約5%の確率で p < 0.05 が起きてしまう」ことを意味します。つまり 有意水準 α = 0.05 とは、H₀が正しいときに誤って棄却してしまう確率そのものであり、これを統計学では 第一種の過誤(Type I error) と呼びます。「p < 0.05 だったから差がある」と即断できないのは、まさにここに理由があります。1,000回のうち約50回は、本当は差がないのに「差がある」と誤判定してしまうのです。多重検定の問題(たくさん検定すれば、そのうちのどれかは偶然有意になる)も、この事実が出発点になっています。
このように、Rで数行のコードを書くだけで「p値の正体」を体感できます。次の章では、こうしたシミュレーションから見えてくる「p値を実務で使うときの落とし穴」について、具体例を挙げながら見ていきましょう。
実務でのポイント ― 製薬・研究の現場でp値を扱うときの注意点 ―
p値は便利な道具ですが、現場で扱う際には「数字の独り歩き」を防ぐ視点が欠かせません。製薬・研究・ビジネスのいずれの分野でも、p値だけを根拠に意思決定を進めると、後から思わぬ落とし穴に気づくことがあります。ここでは、初学者が脱・初心者になるために押さえておきたい実務上のポイントを整理します。
ASA声明 ― 「p < 0.05 だけで結論を出すな」という警告
2016年、ASA(American Statistical Association:米国統計学会)は、p値の誤用が科学全体に与える影響を懸念して公式声明を発表しました。要点をかみ砕くと次のようになります。
- p値は「仮説が正しい確率」ではない
- 「p < 0.05」という閾値だけで科学的・実務的な結論を導いてはいけない
- p値だけでなく、効果量(effect size:効果の大きさ)、信頼区間、研究デザインを総合的に評価すべきである
つまりp値は「判定の出発点」であって、「結論そのもの」ではないという立場が、国際的にも明確に示されたわけです。
p-hacking(ピーハッキング)― 有意になるまで分析を繰り返す行為
p-hacking(p値ハッキング) とは、解析の途中で仮説や対象集団を後付けで変更し、たまたまp < 0.05 になった結果だけを報告してしまう行為を指します。たとえば次のような操作が典型です。
- 多数の変数を片っ端から検定して、有意になったものだけ取り上げる
- サブグループを後から切り出して「この集団では効いていた」と主張する
- データを追加しながら何度も検定を繰り返す
複数の検定を行えば、本当は差がなくても偶然p < 0.05 になる確率は跳ね上がります。これを防ぐために、多重比較補正(multiple comparison adjustment) を行うのが原則です。代表的な手法としてはBonferroni(ボンフェローニ)法、Holm(ホルム)法などがあり、検定の数に応じて有意水準を厳しく調整します。臨床試験では、主要評価項目(primary endpoint)を事前に1つに絞る運用も、p-hacking 対策の重要な一手です。
信頼区間(CI)の併記 ― 「効果の大きさ」を可視化する
p値が示すのは「差があるかどうか」の判定だけで、どのくらい差があるかは教えてくれません。そこで欠かせないのが 95%信頼区間(Confidence Interval:CI) の併記です。
たとえば「血圧低下量の差 = 5 mmHg、95%CI: 0.5〜9.5、p = 0.03」と報告されれば、「有意であり、かつ効果の幅は0.5〜9.5 mmHgのどこかに収まる可能性が高い」と読み取れます。p値単独より、臨床的意義の議論が格段に進みます。論文・治験総括報告書(CSR)でも、信頼区間の併記は実質的に必須の作法です。
製薬実務 ― ICH E9 と「両側0.05・片側0.025」の慣習
医薬品開発では、ICH E9(International Council for Harmonisation:医薬品規制調和国際会議が定めるガイドライン「臨床試験のための統計的原則」)が世界共通の土台です。確証的試験では 第一種の過誤(α:本当は差がないのに「差がある」と誤判定する確率) を 両側0.05(片側0.025) に固定し、解析計画書(SAP)で事前に明文化するのが慣習です。「やってみてからp値が良かった解析」を採用することは、規制当局のレビューで強く敬遠されます。
- 鉄則1:p値だけで判断せず、効果量と95%信頼区間を必ずセットで確認する
- 鉄則2:解析計画は事前に決め、後付けの検定追加・サブグループ解釈は p-hacking と心得る
- 鉄則3:製薬・臨床試験では ICH E9 に則り、有意水準と主要評価項目を解析計画書で確定させてから解析する
📚 この記事をより深く理解するための参考書籍
統計・生物統計をさらに深く学びたい方に、おすすめの書籍をご紹介します。p値・仮説検定の理論から、実務での応用、統計検定対策まで、本記事の内容を一段深く理解するのに役立つ3冊です。






関連記事・次のステップ
p値の理解をさらに深めるための関連記事をご紹介します。本記事で扱ったトピックの「次の一歩」として、ぜひ続けてお読みください。
- 信頼区間とp値の関係を図解で理解する ― なぜ95%CIがp値より重要なのか ―:本記事の「信頼区間を併記すべき理由」をさらに掘り下げ、図解付きで95%CIの優位性を解説しています。
- 区間推定入門:数式と図解で理解する信頼区間の世界:信頼区間の基礎をゼロから学べる入門記事。p値の理解とセットで読むと、両者の関係性がクリアになります。
- 検出力分析(Power Analysis)入門 ― サンプルサイズ設計に欠かせない基礎知識をSAS・Rで実装 ―:本記事の誤解③「p > 0.05 で差がないとは限らない」の背景にある検出力と第二種の過誤を、コード付きで詳しく解説。
- 統計検定 準1級・1級 攻略ガイド ― 試験範囲・学習ステップ・よく出るテーマを完全整理 ―:統計検定の受験を考えている方は、まずこの攻略ガイドで全体像を掴むのがおすすめです。
- 平均への回帰とは何か:統計学初学者のためのやさしい解説:統計初学者がよく混乱する「平均への回帰」を、p値の理解とは別角度のやさしい入門記事として紹介しています。
まとめ
本記事では、統計検定でも実務でも頻繁に登場するp値について、その本来の意味と「3つの代表的な誤解」、Rを用いたシミュレーション、そして製薬・研究の実務で気をつけたい注意点を体系的に整理しました。
押さえておきたい本質は次の3点に集約できます。
- p値は「帰無仮説が正しいと仮定したとき、観測値以上に極端な結果が偶然出る確率」であり、「帰無仮説が正しい確率」でも「効果がある確率」でもないこと
- p < 0.05 と臨床的意義は別物であり、効果量と95%信頼区間を必ずセットで確認する姿勢が必要であること
- ASA声明・p-hacking・ICH E9 が示すとおり、p値は「結論そのもの」ではなく「議論の出発点」として位置づけるべきであること
p値の正しい理解は、統計検定の合格だけでなく、製薬・臨床研究・ビジネスでのデータ活用において読者の大きな強みになります。本記事を出発点として、関連記事・参考書籍を通じてさらに学びを深めていただければと思います。