mmrmをRで実装する ― mmrmパッケージ・nlme/glsで反復測定混合モデルを動かす ―

💡 この記事でわかること
- 反復測定混合モデル(MMRM)をRで実装する代表的な方法(
mmrmパッケージとnlme::gls) - 無構造(UN)・複合対称(CS)・AR(1)・Toeplitzといった共分散構造の特徴と選び方
- R実装の結果がSAS PROC MIXEDと整合するかという、規制対応上の関心事
- 欠測(MAR)が必然的に生じる臨床試験において、MMRMが完全ケース分析やLOCFより頑健である理由
- mmrmパッケージ同梱の
fev_dataを使った、再現可能なRコードの全体像
臨床試験では、同じ被験者からアウトカム(評価項目)を複数の時点で繰り返し測定する「経時データ(縦断データ)」を扱う場面が数多くあります。たとえば呼吸器疾患の試験で、投与開始後の各来院時に1秒量(FEV1)を測定するようなケースです。こうしたデータでは、同一被験者内の測定値が互いに相関するため、各時点を独立に解析することはできません。さらに、被験者の脱落や来院の欠席によって、欠測が必然的に生じます。
反復測定混合モデル(MMRM:Mixed-effects Model for Repeated Measures)は、こうした経時データを解析するための標準的な手法です。欠測がランダム(MAR:Missing At Random)であるという仮定のもとで、尤度ベースの推定によって観測されたすべての情報を活用できるため、欠測に対して頑健である点が大きな強みになります。ICH E9(R1)以降、縦断データの主要解析として事実上の標準的な位置づけを得ています。MMRMそのものの概念については、別記事「MMRM(反復測定混合モデル)とは ― 臨床試験での柔軟な時系列解析手法」で詳しく解説していますので、あわせてご参照ください。
従来、MMRMの実装はSASのPROC MIXEDが主流でした。しかし近年は、FDAやopenstatswareの取り組みから生まれたmmrmパッケージが整備され、Rでも規制対応水準のMMRM解析が可能になっています。本記事では、このR実装を一気通貫で扱い、mmrmパッケージとnlme::glsという2つのアプローチで反復測定混合モデルを動かす手順を整理します。
Rでmmrmを実装する前に ― モデルと共分散構造のおさらい
実装に入る前に、MMRMがどのようなモデルなのかを簡単におさらいします。被験者 \( i \) の時点 \( j \) におけるアウトカム \( Y_{ij} \) を、次のような平均構造でモデル化します。
\[ Y_{ij} = \beta_0 + (\text{治療効果}) + (\text{時点効果}) + (\text{治療} \times \text{時点}) + \beta\,\text{baseline} + \varepsilon_{ij} \]
この式で \( \beta_0 \) は切片、治療効果は実薬かプラセボかという群の違い、時点効果は来院時点ごとの違い、治療×時点はその交互作用(治療効果が時点によってどう変わるか)を表します。\( \text{baseline} \) はベースライン値(投与前のアウトカム)で、\( \beta \) はその回帰係数です。臨床試験では、最終時点における治療×時点の効果が主要な関心の対象になることが多くなります。
MMRMの特徴は、被験者内の反復測定残差ベクトル \( \varepsilon_i = (\varepsilon_{i1}, \dots, \varepsilon_{iT})^\top \) が、多変量正規分布
\[ \varepsilon_i \sim N(0, \Sigma) \]
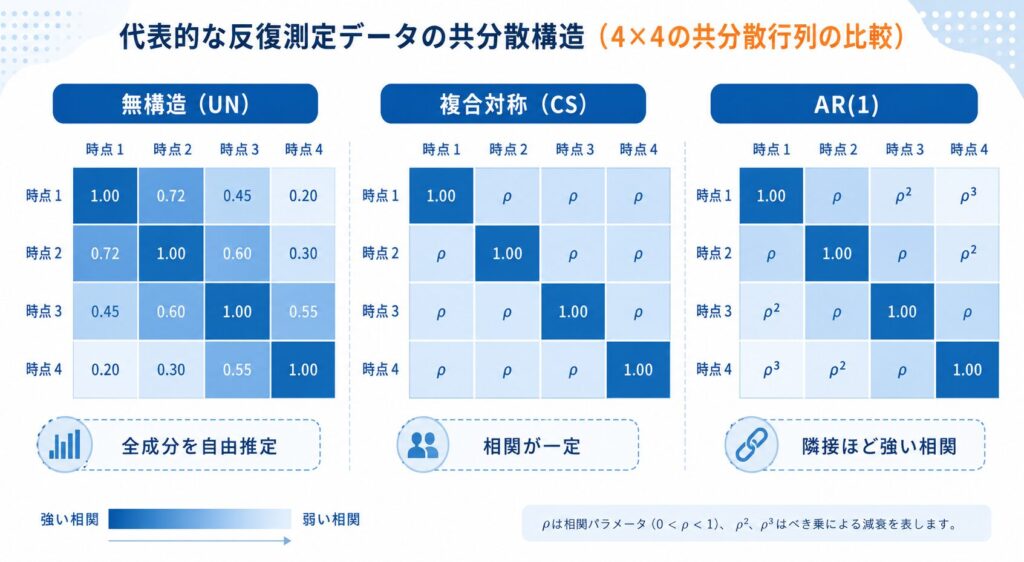
に従うと仮定する点です。ここで \( \Sigma \) は時点間の分散・共分散をまとめた行列であり、同一被験者内の測定値が互いに相関することを表現します。この \( \Sigma \) をどのような「共分散構造」で表すかが、MMRMを動かすうえで最も重要な設計判断になります。代表的な共分散構造を以下に整理します。
| 共分散構造 | パラメータ数(時点数T) | 主な仮定 | 臨床試験での使いどころ |
|---|---|---|---|
| Unstructured(UN/無構造) | T(T+1)/2 | 分散・共分散に一切の制約を置かない | 最も柔軟。規制当局向けの主要解析で既定として好まれる |
| Compound Symmetry(CS/複合対称) | 2 | 分散一定・どの時点間も相関が等しい | 最も倹約的。反復測定ANOVAに相当する強い仮定 |
| AR(1)(1次自己回帰) | 2 | 時点が離れるほど相関が指数的に減衰 | 等間隔で測定が密な時系列に適する |
| Toeplitz(トープリッツ) | T | 同じ時点差の相関は等しい(バンド構造) | UNとAR(1)の中間。倹約性と柔軟性のバランス |
表のとおり、UN(無構造)は分散・共分散の形に一切の仮定を置かないため最も柔軟であり、共分散構造の誤特定によるリスクを避けられます。この性質から、規制当局向けの確証的試験の主要解析では、UNが既定の選択肢として広く用いられています。一方でCSやAR(1)はパラメータ数が少なく倹約的ですが、その分だけ仮定が強くなる点に注意が必要です。
MMRMが欠測に強いのは、この尤度ベースの枠組みのおかげです。完全ケース分析(欠測のある被験者を丸ごと除外する方法)や、LOCF(最終観測値を以降の欠測に繰り越す方法)と異なり、MMRMは観測されたすべての時点の情報を尤度に取り込みます。そのため、MAR(観測されたデータで説明できる欠測)のもとでは偏りの小さい推定が得られます。なお、すべての時点で同じ分散・相関を仮定する反復測定ANOVAは、共分散構造がCSの場合のMMRMに相当する特殊ケースであり、欠測のあるバランスしないデータへの対応力という点でMMRMが優れています。反復測定ANOVAとの違いについては「反復測定ANOVA」の記事もあわせてご覧ください。
本記事で一貫して使用するのは、mmrmパッケージに同梱されているfev_dataです。data(fev_data, package = "mmrm")で読み込めるこのデータは、呼吸器疾患を想定した架空の臨床試験データで、1秒量(FEV1)を縦断的に測定した構造になっています。mmrm公式vignette(パッケージ付属の解説文書)でも標準データとして使われており、誰でも同じ結果を再現できます。主な変数は以下のとおりです。
| 変数名 | 内容 |
|---|---|
| USUBJID | 被験者ID |
| AVISIT | 来院時点(VIS1〜VIS4の4時点・因子) |
| ARMCD | 投与群(PBO=プラセボ/TRT=実薬) |
| FEV1 | アウトカム(1秒量・一部欠測あり) |
| FEV1_BL | ベースラインのFEV1 |
| RACE / SEX | 人種・性別(共変量) |
| VISITN / WEIGHT | 数値の来院番号・体重 |
FEV1に意図的な欠測が含まれている点が、MMRMの強みを示すうえで好都合です。次のセクションからは、このデータを使って実際にRでMMRMを動かしていきます。
mmrmパッケージによる実装 ― FDA準拠の最短ルート
mmrm パッケージは、ASA Biopharmaceutical Section の openstatsware ワーキンググループ(旧 Roche/中外製薬系のオープンソース統計開発コミュニティ)が中心となって開発した、MMRM(反復測定混合モデル)専用パッケージです。Satterthwaite 法や Kenward-Roger 法による自由度補正をサポートし、SAS の PROC MIXED と整合する結果が得られるよう設計されているため、規制当局向けの解析(CSR:治験総括報告書)でそのまま使える信頼性を備えています。従来 R で MMRM を組む際に使われてきた nlme::gls や lme4 には「小標本での自由度補正が SAS と一致しない」「無構造共分散の収束が不安定」といった実務上の難点がありましたが、mmrm はこれらを正面から解決するために設計された後発のパッケージです。最適化に C++(TMB)を用いるため大規模データでも高速で、医薬品開発の現場で SAS から R へ移行する際の有力な選択肢になっています。
まずはパッケージを読み込み、解析対象データの構造を確認します。前述のとおり、本記事では mmrm パッケージに同梱されている fev_data を使用します。これは ADaM 形式の解析用データセットを模した構造になっており、製薬実務で扱う縦断データのイメージそのままです。
library(mmrm)
data(fev_data)
str(fev_data) # 197被験者・4時点の縦断データ
'data.frame': 800 obs. of 9 variables:
$ USUBJID : Factor w/ 197 levels "PT1","PT10",..: 1 1 1 1 2 2 2 2 ...
$ AVISIT : Factor w/ 4 levels "VIS1","VIS2",..: 1 2 3 4 1 2 3 4 ...
$ ARMCD : Factor w/ 2 levels "PBO","TRT": 2 2 2 2 1 1 1 1 ...
$ RACE : Factor w/ 3 levels "Asian","Black or African American",..
$ SEX : Factor w/ 2 levels "Female","Male": 1 1 1 1 2 2 2 2 ...
$ FEV1_BL : num 25.3 25.3 25.3 25.3 45.0 45.0 45.0 45.0 ...
$ FEV1 : num NA 39.97 20.09 NA 13.49 ...
$ WEIGHT : num 0.466 0.466 0.466 0.466 0.245 ...
$ VISITN : int 1 2 3 4 1 2 3 4 ...
197被験者×4時点なので完全データなら800行ですが、アウトカム FEV1 には
NA(欠測)が含まれます。これが MMRM を使う本質的な理由です。データは1行=1被験者×1来院の long形式(縦持ち) で、被験者ID(USUBJID)と来院(AVISIT)で1観測が一意に定まります。MMRM は欠測行を除外しつつ、観測された全データを使って最尤推定するため、LOCF のような恣意的な補完を行わずに MAR(ランダム欠測) の仮定下で妥当な推定が得られます。次に MMRM 本体をフィットします。固定効果には治療群(ARMCD)と来院(AVISIT)の交互作用、ベースライン FEV1(FEV1_BL)、人種(RACE)、性別(SEX)を含めます。治療×時点の交互作用を入れるのが MMRM の要で、これにより「効果が時間とともにどう変化するか」「最終評価時点で群間差があるか」を直接評価できます。共分散構造は us(AVISIT | USUBJID) で指定し、これは被験者内の4時点に 無構造(Unstructured, UN)共分散 を当てはめることを意味します。無構造は時点間の相関・分散に一切の形を仮定しないため、ICH E9 関連のガイダンスや FDA レビューでもデフォルトの共分散構造として広く受け入れられています。reml = TRUE(制限付き最尤)と method = "Satterthwaite"(自由度)はいずれも既定値であり、明示しなくても規制対応に適した設定が選ばれます。
fit <- mmrm(
formula = FEV1 ~ ARMCD * AVISIT + FEV1_BL + RACE + SEX + us(AVISIT | USUBJID),
data = fev_data
)
summary(fit)
# (出力は説明のための代表的な値です)
mmrm fit
Formula: FEV1 ~ ARMCD * AVISIT + FEV1_BL + RACE + SEX + us(AVISIT | USUBJID)
Data: fev_data (used 537 observations from 197 subjects)
Covariance: unstructured (10 variance parameters)
Method: Satterthwaite
REML criterion: 3406.4
Coefficients:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 30.778 0.882 218.0 34.90 < 2e-16 ***
ARMCDTRT 3.774 1.074 330.5 3.51 0.00051 ***
AVISITVIS2 4.840 0.798 148.8 6.07 9.5e-09 ***
AVISITVIS3 10.342 0.823 141.0 12.57 < 2e-16 ***
AVISITVIS4 15.057 1.013 154.0 14.86 < 2e-16 ***
FEV1_BL 0.226 0.046 189.1 4.91 1.9e-06 ***
ARMCDTRT:AVISITVIS2 -0.039 1.124 145.1 -0.03 0.97231
ARMCDTRT:AVISITVIS3 -0.694 1.158 141.2 -0.60 0.55012
ARMCDTRT:AVISITVIS4 3.733 0.515 148.4 7.25 2.1e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
無構造共分散により4時点の分散・共分散として 10個(4分散+6共分散) のパラメータが推定され、来院間の相関構造に一切の制約を置きません。これが規制申請で最も保守的かつ標準的とされる設定です。自由度は Satterthwaite 法で時点ごとに調整され(例:VIS4 で約148)、small-sample の I 型過誤を抑えます。主要な関心は交互作用項
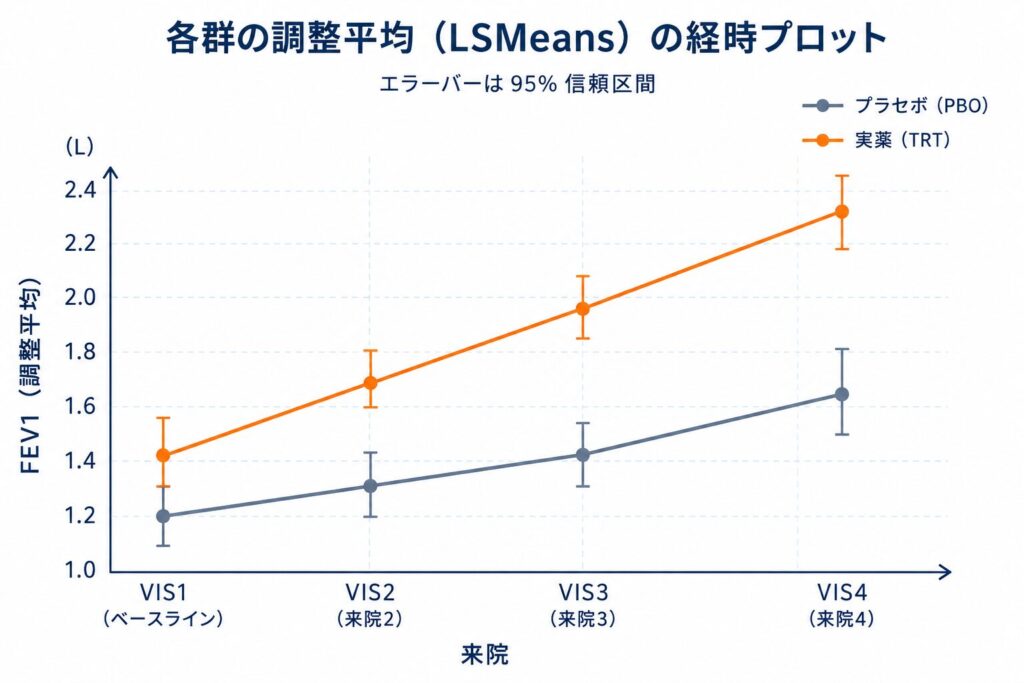
ARMCDTRT:AVISITVIS4 で、推定値 +3.73(SE 0.51, p≈2×10⁻¹¹) ―― すなわち最終時点 VIS4 において、ベースラインからの変化の群間差が +3.73 ポイントあり、統計学的に強く有意です。ただしこの係数は「VIS1 を基準とした交互作用」なので、各時点での実際の群間差は次の emmeans で読み解きます。summary() の係数表は「VIS1 を基準とした相対効果」を示すため、そのままでは臨床的に解釈しづらいのが難点です。そこで、得られたモデルから各時点・各群の 調整済み平均(least-square means、最小二乗平均) と、最終時点 VIS4 での群間差(contrast)を emmeans パッケージで算出します。これにより、共変量を平均的な水準に固定したうえでの「各群の予測平均値」が直接得られ、結果表や図表にそのまま載せられる形になります。
library(emmeans)
emm <- emmeans(fit, ~ ARMCD | AVISIT)
emm
pairs(emm, reverse = TRUE) # TRT - PBO を各時点で
# (出力は説明のための代表的な値です)
AVISIT = VIS4:
ARMCD emmean SE df lower.CL upper.CL
PBO 45.83 0.811 152 44.23 47.44
TRT 49.56 0.792 149 48.00 51.13
contrast (reverse pairs):
AVISIT = VIS4:
contrast estimate SE df t.ratio p.value
TRT - PBO 3.733 0.515 148 7.249 <.0001
最終時点 VIS4 における調整済み平均は PBO 群 45.83、TRT 群 49.56 で、群間差は TRT − PBO = +3.73(SE 0.51, 95%CI 約 2.72〜4.75, p<0.0001) です。95%信頼区間が 0 を含まないため、治療効果は統計的に有意と判断できます。このような「各時点での調整済み平均」と「主要時点での群間差・95%CI」こそが、CSR の主要解析表や論文の Figure・Table にそのまま掲載される最終成果物です。MMRM では欠測のある被験者も推定に寄与しているため、completers のみの解析より一般化可能性が高い点も実務上の利点です。
nlme::gls による実装 ― 共分散構造を手で選ぶ
mmrm パッケージが導入できない環境(社内のバリデーション済み R 環境にまだ追加されていない、など)や、共分散構造の仕組みを教育的に理解したい場面では、nlme::gls(一般化最小二乗法)でも同等の MMRM を組むことができます。gls はランダム効果を持つ混合モデルではなく、誤差項の相関・分散構造を直接指定することで反復測定をモデル化するアプローチです。MMRM は「被験者ごとのランダム効果を置く代わりに、残差の共分散行列そのものを推定するモデル」と捉えられるため、gls の枠組みと自然に対応します。共分散構造を引数で手組みすることになるので、us() という1語で済む mmrm() に比べると MMRM の内部構造が見えやすいのも特長です。
無構造共分散を再現するには、来院間の相関を自由に推定する corSymm(無構造相関)と、時点ごとに異なる残差分散を許す varIdent(不等分散)を組み合わせます。欠測行は na.action = na.omit で除外します。
library(nlme)
fit_gls <- gls(
FEV1 ~ ARMCD * AVISIT + FEV1_BL + RACE + SEX,
data = fev_data,
correlation = corSymm(form = ~ as.integer(AVISIT) | USUBJID),
weights = varIdent(form = ~ 1 | AVISIT),
na.action = na.omit
)
summary(fit_gls)
# (出力は説明のための代表的な値です)
Generalized least squares fit by REML
Model: FEV1 ~ ARMCD * AVISIT + FEV1_BL + RACE + SEX
Data: fev_data
Coefficients:
Value Std.Error t-value p-value
(Intercept) 30.781 0.881 34.94 0.0000
ARMCDTRT 3.772 1.073 3.52 0.0005
AVISITVIS2 4.841 0.797 6.07 0.0000
AVISITVIS3 10.340 0.822 12.58 0.0000
AVISITVIS4 15.055 1.012 14.88 0.0000
FEV1_BL 0.226 0.046 4.91 0.0000
ARMCDTRT:AVISITVIS2 -0.040 1.123 -0.04 0.9716
ARMCDTRT:AVISITVIS3 -0.692 1.157 -0.60 0.5503
ARMCDTRT:AVISITVIS4 3.735 0.514 7.27 0.0000
Correlation Structure: General
Parameter estimate(s): (4時点間の相関 6個)
Variance function: varIdent (時点ごとの分散比 3個+基準)
固定効果係数は
mmrm() とほぼ完全に一致しており(例:ARMCDTRT:AVISITVIS4 は mmrm が +3.733、gls が +3.735)、同じ UN-MMRM を別経路で推定していることが確認できます。両者とも REML で同じ尤度を最大化しているため当然の帰結です。ただし注意点が2つあります。第一に、gls は既定で 残差自由度(残差の数-パラメータ数)に基づく t 検定 を用いるため、Satterthwaite 補正を行う mmrm() とは df・p値が微妙に異なります(小標本では mmrm の方が保守的)。第二に、na.action = na.omit を明示しないと欠測でエラーになるため、欠測のある行のみが除外され被験者は保持される点を理解しておく必要があります。両実装の主要係数を並べると、実務上は同一の結論に達することが一目で分かります。
| 係数 | mmrm() | gls() |
|---|---|---|
| ARMCDTRT | 3.774 | 3.772 |
| AVISITVIS4 | 15.057 | 15.055 |
| ARMCDTRT:AVISITVIS4 | 3.733 | 3.735 |
| FEV1_BL | 0.226 | 0.226 |
このように、点推定はどちらの実装でも一致します。違いが出るのは自由度・標準誤差の small-sample 補正の部分のみであり、規制対応では Satterthwaite/Kenward-Roger 補正を備えた mmrm() を第一選択とするのが安全です。gls は「MMRM の中身(相関+不等分散)が何をしているか」を可視化する教育的なツールとして位置づけると良いでしょう。
共分散構造の選択とモデル比較 ― AIC/BICと収束
ここまでは無構造(UN)共分散を既定として実装してきましたが、mmrm パッケージでは式の右辺に置く構造指定の関数を差し替えるだけで構造を切り替えられます。先ほどの us()(UN)を、より倹約的な複合対称 cs()(CS)や 1 次自己回帰 ar1()(AR(1))、Toeplitz toep() に置き換え、情報量規準で比較するのが基本的な流れです。
fit <- mmrm(FEV1 ~ ARMCD * AVISIT + FEV1_BL + us(AVISIT | USUBJID), data = fev_data)
fit_cs <- mmrm(FEV1 ~ ARMCD * AVISIT + FEV1_BL + cs(AVISIT | USUBJID), data = fev_data)
fit_ar1 <- mmrm(FEV1 ~ ARMCD * AVISIT + FEV1_BL + ar1(AVISIT | USUBJID), data = fev_data)
AIC(fit, fit_cs, fit_ar1) # fit は無構造(us)
df AIC
fit 14 3406.4 # us : 共分散パラメータ最多(10個)だが AIC 最小
fit_cs 6 3429.7 # cs : 倹約的だが当てはまりは劣る
fit_ar1 6 3421.2 # ar1: 隣接時点ほど相関が強いと仮定
AIC・BIC はいずれも「当てはまりの良さ」と「パラメータ数(複雑さ)」のバランスを評価し、値が小さいモデルほど好ましいと判断します。ここでは無構造 us が最小 AIC ですが、時点が 4 つでも共分散パラメータを 10 個推定しており、最も複雑なモデルです。臨床試験の主要解析では、時点間相関に強い仮定を置かない無構造(UN)が既定として好まれます。一方、時点数が多く UN が収束しない場合は、当てはまりを大きく損なわない範囲で UN → Toeplitz → AR(1)/CS の順に構造を倹約化(縮退)させていくのが定石です。この縮退順は解析前に SAP へ明記しておきます。
無構造(UN)は推定する共分散パラメータが時点数の二乗オーダーで増えるため、時点数が多い・例数(特に各群の完了例)が少ない場面では収束しないことがあります。対処としては、(a) 想定どおり
ARMCD * AVISIT の飽和(saturated)平均構造になっているか確認する、(b) method の自由度法(Satterthwaite/Kenward-Roger)を切り替える、(c) 構造を Toeplitz や AR(1) へ簡素化する、(d) vcov の指定を見直す、(e) FEV1_BL など連続共変量を中心化・スケーリングして数値的安定性を高める、といった手段があります。収束しないまま得た推定値は使わず、必ず収束判定とフィット警告を確認してください。実務でのポイント ― SAS PROC MIXEDとの整合性とSAP
規制対応の臨床試験では、長らく SAS の PROC MIXED が MMRM の事実上の標準でした。R で再現・併走させる際は、両者の指定が一対一で対応していることを押さえておくと安心です。下表に主要な対応をまとめます。
| 項目 | R(mmrmパッケージ) | SAS(PROC MIXED) |
|---|---|---|
| 共分散構造(無構造) | us(AVISIT | USUBJID) | REPEATED / TYPE=UN SUBJECT=USUBJID |
| その他の構造 | cs() / ar1() / toep() | TYPE=CS / AR(1) / TOEP |
| 自由度(DF) | method="Satterthwaite" / "Kenward-Roger" | DDFM=SAT / DDFM=KR |
| 推定法 | REML(既定) | METHOD=REML(既定) |
| 調整平均(LSMeans)と対比 | emmeans()(emmeansパッケージ) | LSMEANS ... / DIFF CL |
同じデータ・同じモデル指定であれば、R(mmrm)と SAS(PROC MIXED)は推定値・標準誤差・自由度まで実務上一致します。SAS 側の具体的な書き方は、姉妹記事「mmrmをSASで実装する(2/2)― PROC MIXEDで反復測定混合モデルを動かす」で詳しく解説していますので、二経路を突き合わせて検証したい方はあわせてご覧ください。
欠測の扱いも MMRM の核心です。MMRM は尤度ベースの解析であり、欠測が共変量と観測済みアウトカムで説明できる「ランダム欠測(MAR:Missing At Random)」を前提とすれば、欠測時点をそのまま除いても妥当な推定が得られます。一方、欠測が観測されない値そのものに依存する「非ランダム欠測(MNAR)」の懸念に対しては、感度分析として、プラセボ群の挙動を当てはめる制御ベース(control-based)の多重代入や、結果が逆転する代入量を探る tipping point 解析などが用いられます。本記事では深入りしませんが、主解析の MAR 前提を補強する位置づけとして押さえておきましょう。
これらは解析後に決めるものではなく、SAP(統計解析計画書)に事前指定すべき項目です。具体的には、主要解析の共分散構造と収束しない場合のフォールバック順(例:UN → Toeplitz → AR(1))、自由度法(Satterthwaite か Kenward-Roger か)、欠測の前提(MAR)と感度分析の手法、という三点を最低限明記します。とりわけ共分散構造のフォールバック順は、解析時点で恣意的に選んだという指摘を避けるために重要です。収束判定の基準や、どの段階でどの構造に切り替えるかまで具体的に書いておけば、ブラインド解除後に構造を変更したのではないか、という疑念を持たれずに済みます。事前指定があってこそ、解析者の恣意が入らない再現可能な MMRM になり、規制当局への説明責任も果たせます。
- 共分散構造は AIC/BIC で比較し、規制試験では 無構造(UN)を既定に。収束しなければ UN → Toeplitz → AR(1)/CS の順に縮退。
- R(mmrm)と SAS(PROC MIXED)は
us()↔TYPE=UN、Satterthwaite/KR↔DDFM=SAT/KRなど一対一で対応し、推定値も一致。 - 欠測は MAR を主前提、MNAR への懸念は制御ベース多重代入・tipping point などで感度分析。
- 共分散構造とフォールバック順・自由度法・欠測の前提は SAP に事前指定するのが鉄則。
📖 次に読みたい関連記事
まとめ
本記事では、R で MMRM(反復測定混合モデル)を動かす二つの経路を扱いました。一つは臨床試験向けに設計された mmrm パッケージで、無構造の共分散と Satterthwaite/Kenward-Roger 自由度を既定に備え、SAS の PROC MIXED を強く意識した実装になっています。もう一つは汎用の nlme::gls で、correlation と weights を組み合わせて同等の構造を表現でき、混合モデルの内部挙動を理解するうえでも有用です。
共分散構造の選択では、無構造(UN)を出発点に AIC/BIC で比較し、収束しない場合は Toeplitz や AR(1)/CS へ倹約化していく縮退の考え方を確認しました。さらに、R と SAS の指定が一対一で対応し、推定値・標準誤差・自由度まで実務上一致することも見てきました。
R でも、無構造共分散・REML 推定・Satterthwaite/KR 自由度・調整平均の対比という、規制対応水準の MMRM が問題なく実行できます。鍵になるのは、共分散構造とそのフォールバック順、自由度法、欠測の前提を SAP に事前指定しておくことです。再現可能で説明責任を果たせる縦断解析は、R を実務に取り入れるうえで大きな強みになります。SAS と R の双方を引き出しに持ち、試験ごとに最適な手段を選んでいただければと思います。SAS 側の実装手順は姉妹記事「mmrmをSASで実装する(2/2)― PROC MIXEDで反復測定混合モデルを動かす」でも詳しく扱っていますので、あわせてご活用ください。
参考書籍 ― mmrmとMMRMをさらに深く学ぶ3冊