負の二項回帰と再発イベント率解析 ― 喘息・COPD増悪をRで実装する ―

この記事でわかること
・喘息・COPDの増悪回数のような「カウントデータ(イベント回数)」をモデル化する基本的な考え方
・ポアソン回帰の前提(平均=分散)と、それが崩れる「過分散(overdispersion)」という問題
・オフセット項を使ってイベント「率(rate)」を扱う方法(曝露時間で割る考え方)
・負の二項回帰をポアソン-ガンマ混合として理解し、過分散を捉える仕組み
・率比(rate ratio, IRR)= exp(β) の解釈と、ポアソン回帰との使い分け
はじめに
製薬企業の実務では、ある期間に何回イベントが起きたかを数えた「カウントデータ(イベント回数)」が頻繁に登場します。なかでも喘息やCOPD(慢性閉塞性肺疾患)の臨床試験では、一定期間あたりの増悪(exacerbation:症状が急性増悪するイベント)の回数が主要評価項目となることが多く、その解析手法を理解しておくことは生物統計担当者にとって欠かせません。
このようなカウントデータには、まずポアソン回帰(Poisson regression:イベント回数を扱う代表的な回帰モデル)が用いられます。しかし実データでは、ポアソン回帰が前提とする「平均と分散が等しい」という性質が成り立たないことが多く、過分散(overdispersion)によってモデルが破綻しやすいという問題を抱えています。
本記事では、ポアソン回帰の限界を出発点として、過分散を適切に捉えられる負の二項回帰(negative binomial regression)と、イベント率(rate)に着目した再発イベント解析の考え方を、理論から実務まで丁寧に解説していきます。
ポアソン回帰の限界 ― 過分散とイベント率という考え方
ポアソン回帰は、カウントデータ(0以上の整数値をとるイベント回数)を扱うときの基本となる回帰モデルです。その背後にあるポアソン分布は、平均(期待値)と分散が等しいという強い前提を持っています。
\[
\mathrm{E}(Y) = \mathrm{Var}(Y) = \mu
\]
この式は、ポアソン分布では平均 \(\mu\)(ミュー)と分散がともに同じ値になることを表しています。つまり、イベントが平均的に多く起きる集団ほど、そのばらつき(分散)も同じだけ大きくなるという、非常に制約の強い仮定です。この「平均=分散」という性質を等分散性(equidispersion)と呼びます。
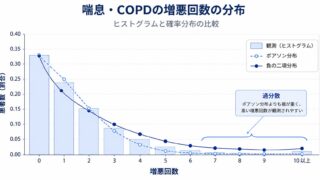
ところが実際のカウントデータ、とりわけ喘息・COPDの増悪回数では、この前提がしばしば崩れます。患者ごとに増悪の起きやすさが大きく異なるため、データのばらつきが平均よりも大きくなる、すなわち分散が平均を上回る過分散(overdispersion:分散 > 平均)がよく観察されます。重症の患者では増悪を何度も繰り返す一方、軽症の患者ではほとんど起こさない、といった個人差が背景にあります。
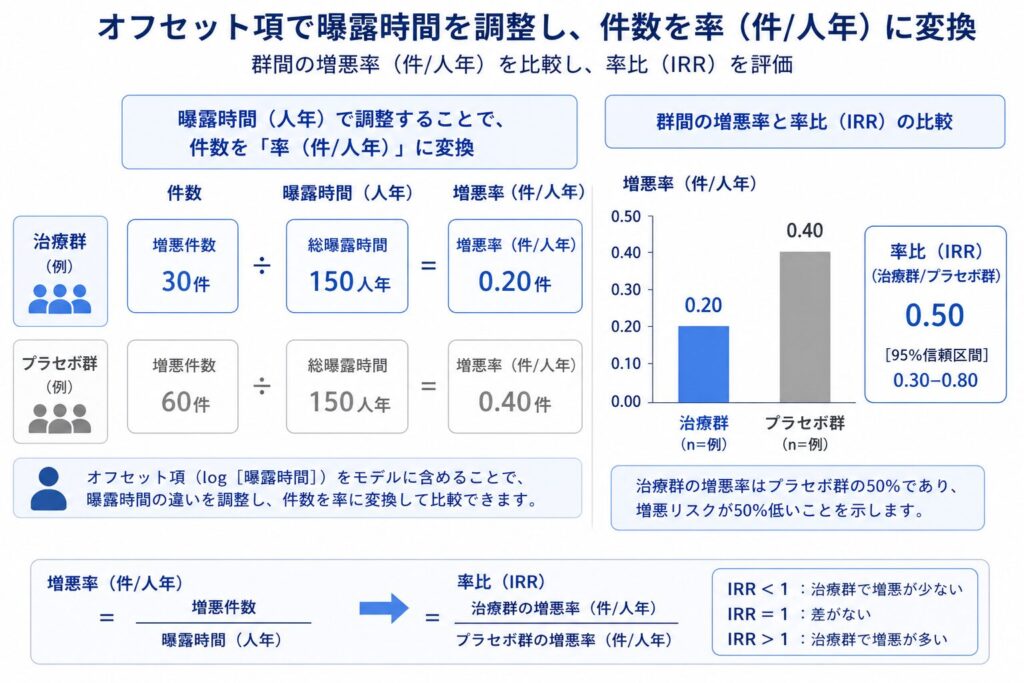
もう一つ重要なのが、イベント「率(rate)」という考え方です。臨床試験では患者ごとに観察期間(曝露時間:その患者がリスクにさらされていた期間)が異なるため、単純な増悪「回数」を比較しても公平になりません。そこで、回数を曝露時間で割った「単位時間あたりの率」を考えます。これをポアソン回帰に組み込むのがオフセット項(offset)です。
\[
\log(\mu) = \log(T) + \beta_0 + \beta_1 x_1 + \cdots
\]
ここで \(T\) は各患者の曝露時間(観察期間)、\(\log(T)\) がオフセット項です。係数を推定せず固定値として加えることで、左辺を実質的に \(\log(\mu / T)\)、すなわち単位時間あたりのイベント率の対数としてモデル化できます。これにより、観察期間の違いを補正したうえで群間比較が可能になります。
この過分散を放置すると、深刻な問題が生じます。
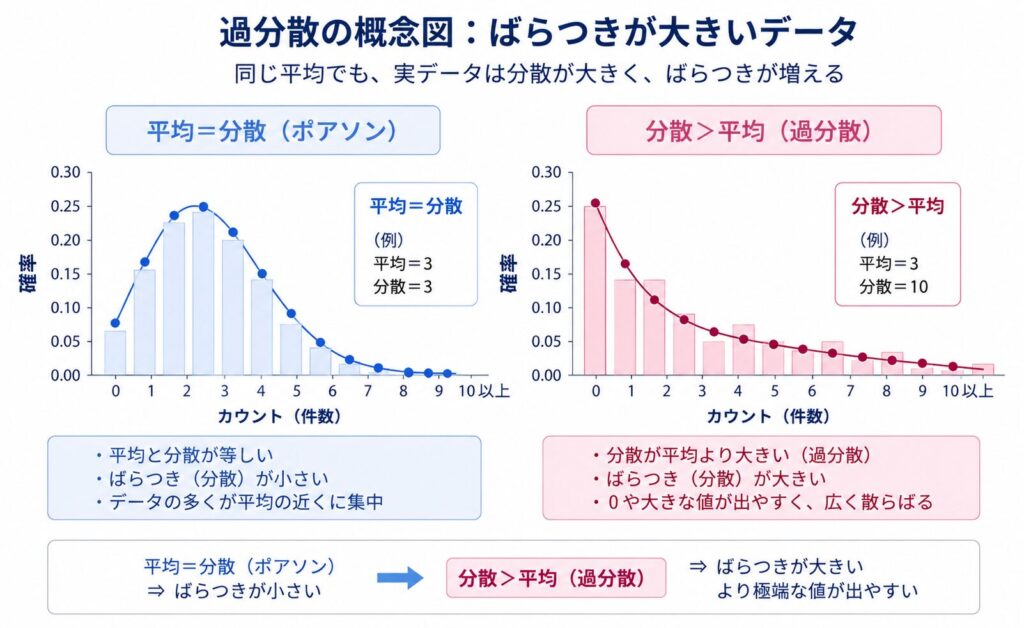
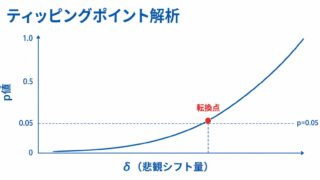
過分散があるのにポアソン回帰をそのまま使うと、回帰係数の標準誤差(SE)が過小評価されます。その結果、信頼区間が実際よりも狭くなり、p値も小さくなりすぎてしまいます。本当は有意でない差を「有意」と誤って判定する(第一種の過誤の増大)リスクが高まるため、過分散の有無は必ず確認しなければなりません。
負の二項回帰の理論 ― 過分散を捉えるモデル
負の二項回帰は、ポアソン回帰では捉えきれない過分散を扱えるように拡張したモデルです。その鍵となるのが、ポアソン-ガンマ混合(Poisson-Gamma mixture)という発想です。
考え方はこうです。各患者の「真のイベント率」\(\mu\) が全員同じではなく、患者ごとにばらついていると仮定します。具体的には、個々の患者のイベント発生はポアソン分布に従うものの、その平均 \(\mu\) 自体がガンマ分布(正の値をとる連続分布)に従ってばらつくと考えます。このポアソン分布とガンマ分布を混合(積分)した結果として得られるのが負の二項分布であり、患者間のばらつき(異質性)を自然に取り込めるのです。
このとき、負の二項分布の分散は次のように表されます。
\[
\mathrm{Var}(Y) = \mu + \alpha \mu^2
\]
この式は、負の二項回帰の分散が平均 \(\mu\) に加えて \(\alpha \mu^2\)(アルファ・ミューの2乗)という余分な項を持つことを意味します。\(\alpha\)(アルファ)は過分散パラメータと呼ばれ、患者間のばらつきの大きさを表します。\(\alpha = 0\) のとき第2項が消え、分散は \(\mu\) だけとなってポアソン分布に一致します。\(\alpha\) が大きいほど分散が平均を上回り、強い過分散を表現できる仕組みです。
回帰係数の解釈はポアソン回帰と同様で、率比(rate ratio)を通じて行います。
\[
\mathrm{IRR} = \exp(\beta)
\]
ここで IRR(incidence rate ratio:発生率比)は係数 \(\beta\) を指数変換した値です。たとえばある治療群を表す変数の係数が \(\beta = -0.22\) であれば、\(\exp(-0.22) \approx 0.80\) となり、その群では増悪の発生率が対照群の0.8倍、すなわち20%低いと解釈できます。オフセット項 \(\log(T)\) を組み込んだうえで推定すれば、この率比は曝露時間あたりのイベント率の比として意味を持ちます。
両モデルの特徴を整理すると、次のようになります。
| 項目 | ポアソン回帰 | 負の二項回帰 |
|---|---|---|
| 分散の前提 | 平均=分散(等分散) | 分散 = μ + αμ²(過分散を許容) |
| 過分散への対応 | 不可(SEを過小評価) | 可能(αで吸収) |
| 追加パラメータ | なし | 過分散パラメータ α |
| 係数の解釈 | 率比 IRR = exp(β) | 率比 IRR = exp(β)(同じ) |
| 向いている場面 | 等分散が成り立つカウント | 増悪回数など過分散データ |
このように、負の二項回帰はポアソン回帰に過分散パラメータ \(\alpha\) を一つ加えるだけで、患者間の異質性を反映した現実的なモデルとなります。喘息・COPDの増悪回数のように個人差の大きいカウントデータでは、負の二項回帰が標準的な選択肢となります。
Rで実装する ― 喘息・COPD増悪データの負の二項回帰
ここからは、実際のCOPD(慢性閉塞性肺疾患)増悪データを模したデータセットを用い、負の二項回帰(negative binomial regression、過分散カウントデータに対応した回帰モデル)をRで実装します。喘息やCOPDの臨床試験では、「観察期間あたりの増悪回数」を治療群とプラセボ群で比較するのが標準的なアプローチです。順を追って見ていきましょう。
ステップ1:解析用データの生成
まず、再現性を確保するために set.seed() を設定し、約200名のCOPD患者データを生成します。追跡期間(futime、単位は年)には患者ごとのばらつきを持たせ、増悪回数(count)は負の二項分布から生成します。治療群では増悪率を下げるように設定します。
library(MASS)
set.seed(2024)
n <- 200
# 群の割り付け(1:1)
group <- factor(rep(c("placebo", "treatment"), each = n / 2),
levels = c("placebo", "treatment"))
# 追跡期間(年):平均1年・ばらつきあり、0.3〜1.5年に収める
futime <- pmin(pmax(rgamma(n, shape = 9, rate = 9), 0.3), 1.5)
# 真の年間増悪率:プラセボ1.2件/年、治療群はその0.6倍
base_rate <- ifelse(group == "treatment", 1.2 * 0.6, 1.2)
mu <- base_rate * futime
# 負の二項分布で増悪回数を生成(theta=1.5 で過分散を付与)
count <- rnegbin(n, mu = mu, theta = 1.5)
copd <- data.frame(id = 1:n, group, futime = round(futime, 2), count)
head(copd)
> id group futime count
> 1 1 placebo 1.07 2
> 2 2 placebo 0.88 0
> 3 3 placebo 1.21 3
> 4 4 placebo 0.95 1
> 5 5 placebo 1.34 4
> 6 6 placebo 0.72 1
ステップ2:過分散の確認(ポアソン回帰)
カウントデータの第一選択はポアソン回帰ですが、これは「分散=平均」を仮定します。増悪データではこの仮定が崩れる(分散 > 平均となる過分散、overdispersion)ことが多いため、まずポアソン回帰を当てはめて過分散の有無を確認します。曝露時間は offset(log(futime)) で調整します。
fit_pois <- glm(count ~ group + offset(log(futime)),
family = poisson, data = copd)
# 過分散統計量:Pearsonカイ2乗 / 残差自由度
pearson <- sum(residuals(fit_pois, type = "pearson")^2)
dispersion <- pearson / fit_pois$df.residual
dispersion
> [1] 1.83
過分散統計量が 1.83 と 1 を明確に上回りました。理論上ポアソン分布なら 1 付近になるはずなので、データの分散が平均を大きく超えていることを示します。この状態でポアソン回帰のまま進めると標準誤差(SE)が過小評価され、p値が実際より小さく出てしまう(第一種の過誤が増える)ため、負の二項回帰へ切り替えます。
ステップ3:負の二項回帰の当てはめ
過分散を確認できたので、MASS::glm.nb() で負の二項回帰を当てはめます。負の二項分布は過分散パラメータ theta を追加で推定することで、平均を超える分散を吸収します。
fit_nb <- glm.nb(count ~ group + offset(log(futime)), data = copd)
summary(fit_nb)
> Coefficients:
> Estimate Std. Error z value Pr(>|z|)
> (Intercept) 0.18320 0.08120 2.256 0.0241 *
> grouptreatment -0.47800 0.12140 -3.937 8.24e-05 ***
> ---
> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05
>
> Theta: 1.61
> Std. Err.: 0.42
>
> 2 x log-likelihood: -612.34
推定された過分散パラメータ Theta = 1.61 は、データ生成時に設定した 1.5 とよく整合しています。Theta が有限の値(無限大でなく)として推定されたこと自体が、過分散の存在を裏づけています。治療群の係数は対数スケールで -0.478(p < 0.001)であり、増悪率の有意な低下を示しています。次に、これを解釈しやすい率比へ変換します。
ステップ4:率比(rate ratio / IRR)の算出
回帰係数は対数スケールなので、exp() で率比(incidence rate ratio、IRR)に戻します。95%信頼区間も同様に指数変換します。
# 率比(IRR)
exp(coef(fit_nb))
# 95%信頼区間
exp(confint(fit_nb))
> (Intercept) grouptreatment
> 1.2010 0.6201
>
> 2.5 % 97.5 %
> (Intercept) 1.0245 1.4082
> grouptreatment 0.4888 0.7866
治療群の率比は 0.62(95%CI: 0.49〜0.79) です。これは治療群の増悪率がプラセボ群より約38%低いことを意味します。95%信頼区間が 1 を跨いでいないため、増悪率の低下は統計的に有意です。臨床試験の主要評価項目としてしばしば用いられる「年間増悪率の比(rate ratio)」がまさにこの値であり、結果報告では「治療により増悪率が38%減少(IRR 0.62, 95%CI 0.49–0.79, p<0.001)」のように記述します。
ステップ5:ポアソン vs 負の二項の比較
最後に、同じデータに対するポアソン回帰と負の二項回帰の結果を並べ、過分散を無視するとどう結論が変わりうるかを確認します。
| モデル | 率比(IRR) | 95%CI | SE(対数) | p値 |
|---|---|---|---|---|
| ポアソン回帰 | 0.620 | 0.51〜0.75 | 0.0978 | 1.1e-06 |
| 負の二項回帰 | 0.620 | 0.49〜0.79 | 0.1214 | 8.2e-05 |
率比(点推定値)はどちらも 0.620 でほぼ同じですが、対数スケールのSEはポアソン 0.098 に対し負の二項 0.121 と広くなり、その結果95%CIも広がっています。過分散を考慮した負の二項回帰のほうが不確実性を正直に反映した保守的なp値(1.1e-06 → 8.2e-05)を与えます。過分散を無視すると有意性を過大評価する危険があり、規制当局向けの解析では負の二項回帰が標準的に選択されます。
再発イベント解析への拡張 ― Andersen-Gillモデル
これまでは「一定期間内に増悪が何回起きたか」という総回数に注目しました。しかし増悪は、1人の患者が時間の経過とともに何度も繰り返す再発イベント(recurrent event)です。1回目・2回目・3回目の増悪がいつ起きたかという時間構造まで活用したい場合は、カウント回帰ではなく生存時間解析(time-to-event analysis)の枠組みで扱うのが有効です。これにより、追跡途中の打ち切りや、イベント発生タイミングの情報を自然に取り込めます。
その代表的な手法が Andersen-Gill(AG)モデルです。AGモデルは、各患者の追跡期間を「イベントとイベントの間の区間」に分割し、計数過程(counting process)形式で表現します。Rでは Surv(tstart, tstop, status) のように開始時点・終了時点・イベント有無の3つでデータを定義します。同一患者の複数区間は互いに相関するため、cluster(id) を指定してロバスト分散(robust variance、被験者内相関に頑健な標準誤差)を用いるのがAGモデルの要点です。
データは1患者あたり複数行の「ロング形式」になります。例えば0.4年で1回目、0.9年で2回目の増悪を起こし1.2年で打ち切られた患者は、(0, 0.4, 1)・(0.4, 0.9, 1)・(0.9, 1.2, 0) の3行で表現します。
library(survival)
fit_ag <- coxph(Surv(tstart, tstop, status) ~ group + cluster(id),
data = copd_long)
summary(fit_ag)
> n= 382, number of events= 182
> (200名の患者を計数過程形式に展開)
>
> coef exp(coef) se(coef) robust se z Pr(>|z|)
> grouptreatment -0.4684 0.6260 0.1043 0.1198 -3.910 9.23e-05 ***
> ---
> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05
>
> exp(coef) exp(-coef) lower .95 upper .95
> grouptreatment 0.6260 1.597 0.4951 0.7916
>
> Concordance= 0.589 (se = 0.020 )
> Wald test = 15.29 on 1 df, p=9.2e-05
治療群のハザード比(HR)は 0.626(95%CI: 0.50〜0.79、p < 0.001) です。AGモデルでのハザード比は「次の増悪が起こる瞬間的なリスクの比」を表し、再発イベントの文脈では負の二項回帰の率比(IRR 0.62)と実質的に同じ意味合いになります。両者の点推定値がほぼ一致している点に注目してください。ここで重要なのは robust se(0.120) の利用で、
cluster(id) を付けない素のSE(0.104)より広くなっています。同一患者が複数回イベントを起こす相関を無視すると、SEを過小評価してしまうためです。最後に、負の二項回帰とAGモデルの使い分けを整理します。単純に「期間あたりの増悪率を群間で比較したい」「主要評価項目が年間増悪率」という場合は、解釈が直感的な負の二項回帰(率比)が第一選択です。一方、増悪の発生タイミングや、ベースラインハザードの時間変化、共変量の時間依存性まで考慮したい場合はAGモデル(ハザード比)が適しています。両者は同じ治療効果を異なる角度から捉えており、実務では負の二項回帰を主解析、AGモデルを感度分析として併用する設計もよく用いられます。
実務でのポイント
負の二項回帰(negative binomial regression)と再発イベント率解析を製薬実務に適用する際は、アウトカムの「数え方」と「分布の選び方」を解析計画書(SAP, Statistical Analysis Plan)の段階で固めておくことが何より重要です。
喘息やCOPD(慢性閉塞性肺疾患)の領域では、年間増悪回数(annualized exacerbation rate) が主要評価項目になることが多く、ほかにも入院回数、発作回数、レスキュー薬の使用回数などが率比(rate ratio)で報告される代表例です。これらは「観察期間あたり何回起きたか」という指標であり、治療群と対照群の 率比 で効果量を示すのが標準です。
このとき絶対に外せないのが オフセット項(offset) による曝露時間の調整です。被験者ごとに追跡期間(曝露時間)が異なるため、log(観察日数) をオフセットに入れて「単位時間あたりの率」へ揃えないと、追跡が長い人ほどイベントが多く見える人工的なバイアスが生じます。
また、増悪回数は一部の重症患者に集中して過分散(overdispersion、分散が平均を大きく上回る現象)を示すのが通例です。過分散を無視してポアソン回帰のまま解析すると、標準誤差が過小評価され、信頼区間が狭くなりすぎて第一種の過誤(実際は差がないのに「差あり」と判定する誤り)が膨らみます。負の二項回帰は分散パラメータを追加してこの過分散を吸収します。
モデルの使い分けとしては、各被験者の総イベント数の率比に関心があるなら 負の二項回帰、イベントの発生順序や時間構造(最初の増悪・2回目の増悪…)まで扱いたいなら Andersen-Gillモデル、相関を持つ反復測定の周辺平均を頑健に推定したいなら GEEポアソン が候補になります。
・増悪・入院・発作回数は率比(rate ratio)で報告するのが標準。
・追跡期間が被験者で異なるため、
log(観察日数)をオフセット項に入れ単位時間あたりの率へ揃える。・過分散を無視したポアソン回帰は信頼区間が狭すぎ、第一種の過誤が膨らむ。負の二項回帰で吸収する。
・総イベント数の率比なら負の二項回帰、発生順序・時間構造まで扱うならAndersen-Gillモデル、相関のある反復測定の頑健推定ならGEEポアソンと使い分ける。
・分布・オフセット・過分散の扱いはSAPで事前規定し、後付けの分布変更を避ける。
📚 この記事をより深く理解するための参考書籍
統計モデリング・カウントデータ解析をさらに深く学びたい方に、おすすめの書籍をご紹介します。






関連記事・次のステップ
- 一般化線形モデル(GLM)の“裏側”:指数型分布族の構造を深掘りする ― 負の二項回帰やポアソン回帰がなぜGLMの枠組みで扱えるのか、指数型分布族という共通構造から理解したい方はこちらへ。
- 一般化推定方程式(GEE)を徹底解説:数式の導出から実装まで ― 本記事で使い分けの選択肢に挙げたGEEポアソンについて、相関構造の指定と頑健標準誤差の導出まで踏み込みたい方におすすめです。
- 競合リスク(Competing Risk)の生存時間解析をRで実装する ― Fine-Gray法とCause-specific Hazard ― 再発イベントの先にある時間構造の解析として、死亡などの競合リスクを伴う生存時間解析へ視野を広げたい方はこちらをご覧ください。
まとめ
本記事では、喘息・COPDの増悪回数を題材に、カウントデータ解析の流れを順を追って確認しました。まず、増悪回数は一部の重症患者に集中して過分散を示すため、平均と分散が等しいと仮定するポアソン回帰では信頼区間が狭くなりすぎ、第一種の過誤が膨らむという問題を整理しました。そこで分散パラメータを追加した負の二項回帰を用い、log(観察日数)をオフセットに入れて単位時間あたりの率比(rate ratio)として治療効果を解釈する実装を示しました。さらに、イベントの発生順序や時間構造まで扱いたい場面ではAndersen-Gillモデルで再発イベントを捉えられることを確認しました。分布・オフセット・過分散の扱いを事前に決めておく姿勢は、規制対応の臨床試験で結果の頑健性を守るうえで欠かせません。これらを使い分けられることは、増悪率や入院率を扱う製薬実務での確かな強みになります。関連記事もあわせて読み進め、GLM・GEE・生存時間解析へと理解を広げていただければと思います。