ベイズ階層モデル ― バスケット試験での借用と縮約をRで実装 ―

この記事でわかること
- バスケット試験とは何か:同一薬剤を複数のがん種・サブグループで同時評価するデザインの概要と、マスタープロトコルとの位置づけを理解できます。
- なぜベイズ階層モデル(BHM)が必要か:独立解析と完全プーリングそれぞれの問題点と、BHMが両極端を「ちょうど中間」でバランスする仕組みを学べます。
- 借用と縮約の考え方:サブグループ間で情報を共有する「部分プーリング」の数学的直感と、データが少ないほど縮約が強まる性質を把握できます。
- RによるBHMの実装:
bhmbasket・rstanarmを使った具体的なコードと、結果の読み方・実務上の注意点を確認できます。 - 実務での使いどころ:規制当局への説明や感度解析のポイントなど、製薬統計担当者が押さえておくべき実践的な観点を得られます。
はじめに
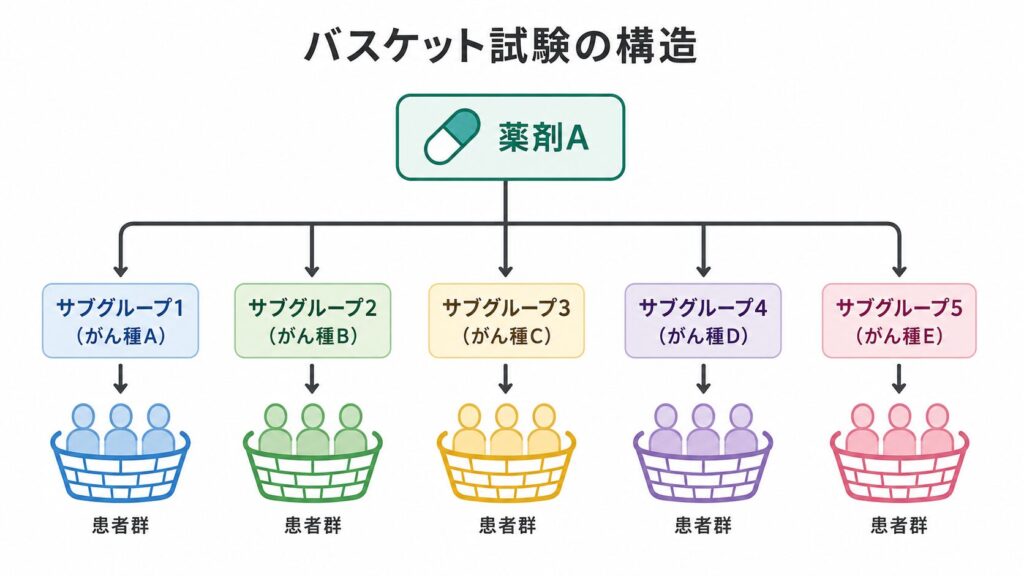
近年のオンコロジー開発では、「がん腫(原発部位)」ではなく「バイオマーカー」によって患者を選択する治験デザインが急速に普及しています。BRAF変異、NTRK融合遺伝子、MSI-Hといったバイオマーカー陽性集団は、肺がん・大腸がん・甲状腺がんなど複数のがん種にまたがって存在します。これらをひとつの試験で同時に評価する枠組みがバスケット試験です。
バスケット試験の最大の課題は、各がん種サブグループ(バスケット)の症例数が非常に少ないことです。希少疾患領域ではなおさらで、あるバスケットに登録できる患者が10例程度しかいないケースも珍しくありません。このような状況でサブグループごとに独立した解析を行うと、推定値の標準誤差が大きくなり、真の効果があっても検出できないリスクが高まります。一方、すべてのバスケットを区別なく一括して解析する「完全プーリング」は、がん種間の異質性を無視するという別の問題をはらみます。
この「小標本・多グループ」問題に対する統計学的な解として注目されているのが、ベイズ階層モデル(Bayesian Hierarchical Model, BHM)です。BHMは各サブグループを完全に独立とも完全に同一とも仮定せず、「グループ間で共通する上位分布(ハイパープライアー)」を通じて情報を借用(borrow)します。データの少ないバスケットほど上位分布に引き寄せられる縮約(shrinkage)が起き、推定が安定します。逆にデータが豊富なバスケットは自身のデータを優先し、過度な借用を受けません。
本記事では、BHMの直感的な理解から始め、Rでの実装(bhmbasket・rstanarm)、結果の解釈、そして規制対応を含む実務上の注意点まで、製薬企業の生物統計担当者・R実務家・統計を学ぶ社会人・大学生を対象に丁寧に解説します。バスケット試験の統計解析に初めて携わる方でも手を動かしながら理解できるよう、再現可能なサンプルコードを随所に掲載しています。
バスケット試験とマスタープロトコルとは
バスケット試験は「マスタープロトコル(Master Protocol)」と呼ばれる試験デザイン群の一つです。マスタープロトコルとは、複数の薬剤・対象集団・仮説を1つの試験の枠組みで同時に検討できる設計の総称で、主に以下の3種類に分類されます。
| 試験デザイン | 分類の主軸 | 代表例 |
|---|---|---|
| バスケット試験 | 1薬剤 × 複数疾患・がん種(共通バイオマーカーで選択) | BRAF阻害剤をBRAF変異陽性の複数がん種で評価(NCI-MATCH試験など) |
| アンブレラ試験 | 1疾患 × 複数薬剤(バイオマーカーで治療を割り振り) | 非小細胞肺がん患者を遺伝子変異別に各治療アームへ割り付け(LUNG-MAP試験など) |
| プラットフォーム試験 | 試験を終了させずにアームを追加・削除できる適応的設計 | RECOVERY試験(COVID-19)、I-SPY 2試験(乳がん)など |
バスケット試験では「同じバイオマーカーを持つなら、がん種が違っても似た効果が期待できる」という仮説のもと、各バスケットで薬剤の有効性を評価します。しかし、この仮説が成立するかどうかはバスケットによって異なります。たとえばBRAF阻害剤は黒色腫には著効する一方、大腸がんではフィードバック活性化により効果が減弱することが知られています。つまり、バスケット間には異質性(heterogeneity)が存在しうるのです。
ここで、バスケット間の情報借用についてもう少し丁寧に考えてみましょう。解析戦略の両極端を整理すると次のようになります。
独立解析(完全分離):各バスケットを別々の試験とみなし、それぞれのデータのみで推定します。バスケット間の異質性を最大限に尊重できる一方、1バスケットあたりの症例数が10〜20例程度では推定の不確実性が非常に大きく、統計的検出力が低下します。希少がん種のバスケットでは「効果ありそうだが有意差なし」という結論に終わるリスクがあります。
完全プーリング(全統合):全バスケットのデータを1つの集団として解析します。標本サイズが大きくなり推定は安定しますが、「すべてのバスケットで治療効果が同じ」という強い仮定を置くことになります。一部のバスケットで効果が大きく異なる場合、その情報が平均化されて埋もれてしまいます。
BHMはこの両者の中間に位置する部分プーリング(partial pooling)を実現します。各バスケットの効果パラメータが「共通するグループ平均と分散を持つ上位分布」から生成されると仮定することで、データの多いバスケットは自身のデータに、データの少ないバスケットは全体の平均に引き寄せられます。この引き寄せの強さは縮約の度合いとして定量化でき、バスケット間の異質性が大きいほど縮約は弱まり、異質性が小さいほど縮約は強まります。これにより、BHMは「似ているグループ同士では情報を積極的に借用し、異なるグループ間では借用を控える」という柔軟な推定を自動的に実現するのです。
ベイズ階層モデルの仕組み ― 借用と縮約 ―
階層構造の定式化
バスケット試験では、複数の腫瘍種(バスケット)に対して同一の治療を評価します。バスケットを \(k = 1, 2, \ldots, K\) と番号づけし、それぞれのバスケットで \(n_k\) 人を観察したとき、奏効した人数 \(y_k\) は次の二項分布に従うと仮定します。
\[
y_k \sim \mathrm{Binomial}(n_k,\ p_k)
\]
ここで \(p_k\) はバスケット \(k\) における真の奏効率です。奏効率をそのままモデル化するよりも、ロジットスケールに変換したほうが数値的に扱いやすくなります。
\[
\theta_k = \mathrm{logit}(p_k) = \log\frac{p_k}{1 – p_k}
\]
\(\theta_k\) はロジットスケールでの奏効率であり、実数全体(\(-\infty\) から \(+\infty\))をとります。ここまでは通常のロジスティック回帰と同様ですが、ベイズ階層モデルの核心は次の一段上の構造にあります。
\[
\theta_k \sim \mathcal{N}(\mu,\ \tau^2)
\]
各バスケットのロジット奏効率 \(\theta_k\) は、全バスケット共通の平均 \(\mu\) と分散 \(\tau^2\) を持つ正規分布から独立に生成されると考えます。\(\mu\) はすべてのバスケットに共通する「基準となる奏効率(ロジットスケール)」、\(\tau\) はバスケット間のばらつきの大きさを表します。
さらにハイパーパラメータ自体にも事前分布を設定します。
\[
\mu \sim \mathcal{N}(m_0,\ s_0^2), \qquad \tau \sim \mathrm{Half\text{-}Normal}(0,\ \sigma_\tau)
\]
\(\mu\) の事前分布は解析者が持つ「おおよそどの程度の奏効率が期待されるか」という情報を反映します。\(\tau\) の事前分布には負の値を取れないハーフ正規分布などを用います。
以下の表に、モデルで設定する事前分布の一覧をまとめます。
| パラメータ | 事前分布(例) | 意味 |
|---|---|---|
| \(\mu\) | \(\mathcal{N}(-1,\ 1^2)\) | 全バスケット共通の基準奏効率(ロジットスケール)。\(\mathrm{logit}(0.27)\approx -1\) に相当 |
| \(\tau\) | \(\mathrm{Half\text{-}Normal}(0,\ 1)\) | バスケット間ばらつき。値が小さいほど各バスケットの推定値が互いに近づく |
| \(\theta_k\) | \(\mathcal{N}(\mu,\ \tau^2)\) | バスケット \(k\) 固有のロジット奏効率。データと上位事前の両方から推定される |
| \(p_k\) | \(\mathrm{logistic}(\theta_k)\) | バスケット \(k\) の奏効率(0〜1)。意思決定に直接使う事後分布が得られる |
借用(borrowing)と縮約(shrinkage)の直感
階層モデルの威力は、各バスケットが互いの情報を借用する点にあります。この現象を「情報の借用(information borrowing)」と呼び、推定値が全体平均に引き寄せられる性質を「縮約(shrinkage)」と呼びます。
バスケット試験における3つのプーリング戦略を比較すると、違いが明確になります。
完全独立(no pooling):各バスケットを完全に別々の試験として解析します。サンプルサイズが小さいバスケットでは推定の不確実性が非常に大きくなり、有望なシグナルを見逃すリスクが高まります。
完全プーリング(complete pooling):すべてのバスケットを1つにまとめて解析します。腫瘍種間の異質性を無視するため、効かないバスケットが有効なバスケットの推定を希釈するおそれがあります。
部分プーリング(partial pooling)=ベイズ階層モデル:上記2つの中間です。各バスケットの推定値は自身のデータを主な拠り所にしつつ、\(\mu\) という共通の重力中心に向かって引き寄せられます。サンプルサイズが小さいバスケットほど引力が大きく働き、他バスケットの情報を多く借用します。
この引き寄せの強さを制御するのが \(\tau\) です。
\[
\hat{\theta}_k \approx (1 – B_k)\,\hat{\theta}_k^{\text{obs}} + B_k\,\hat{\mu}, \qquad B_k \approx \frac{1/n_k}{1/n_k + \tau^2}
\]
\(B_k\) は「縮約係数」で0から1の値をとります。\(\tau \to 0\) のとき \(B_k \to 1\) となり、すべての推定値が \(\hat{\mu}\) に集約されます(完全プーリングに近い)。逆に \(\tau \to \infty\) のとき \(B_k \to 0\) となり、自分のデータだけに依存する独立解析に近づきます。つまり \(\tau\) が小さいほど借用が強く、\(\tau\) が大きいほど各バスケットが独立に扱われるわけです。
事前分布の選び方
モデルの結論に最も影響を与える事前分布は、パラメータ間の相互作用ではなく、ひとえに \(\tau\) の事前分布です。\(\tau\) はバスケット間の異質性を表すため、その値が借用の強さを直接決定します。
実務では、特定の値に強く情報を集中させず、適度な広がりを持ちつつ正値に制約できる弱情報事前分布(weakly informative prior)がよく用いられます。具体的には \(\mathrm{Half\text{-}Normal}(0, 1)\) や \(\mathrm{Half\text{-}Cauchy}(0, 1)\) が代表的な選択肢です。Half-Cauchy は裾が重いため、バスケット間の異質性が大きい場合にも柔軟に対応できる一方、推定が不安定になるケースもあります。
バスケット試験のベイズ階層モデルとして広く参照されるのが Berry et al.(2013) の枠組みです。また、部分的な交換可能性を取り込んで個々のバスケットが本当に同一の薬効クラスに属するかどうかを考慮する EXNEX(Exchangeability-Nonexchangeability)アプローチ(Neuenschwander et al., 2016)も実用上重要で、より柔軟な異質性のモデル化が可能です。
\(\tau\) の事前分布の選択は推定結果に実質的な影響を与えます。同じデータでも、\(\mathrm{Half\text{-}Normal}(0, 0.5)\) と \(\mathrm{Half\text{-}Normal}(0, 2)\) では事後奏効率の推定値や各バスケットの判断が変わることがあります。規制当局への申請を念頭に置く場合は、事前分布を複数設定したシミュレーション(Operating Characteristics の評価)を必ず実施し、感度分析として結果を示すことが強く推奨されます。
意思決定の枠組み
頻度論のバスケット試験では、帰無仮説「\(p_k \le p_0\)(奏効率が閾値以下)」を有意水準 \(\alpha\) で棄却できるかどうかを判断基準にします。ベイズ流では発想が異なり、MCMCで得られた事後サンプルを用いて次の確率を計算します。
\[
\Pr(p_k > p_{\text{target}} \mid \text{data}) \ge \delta
\]
「バスケット \(k\) の奏効率が目標閾値 \(p_{\text{target}}\) を超える事後確率が、判断基準 \(\delta\)(例:0.80)以上であれば有効と判断する」という形です。\(p_{\text{target}}\) と \(\delta\) はプロトコル策定時に事前に規定しておく必要があります。この枠組みでは、各バスケットに対して独立した有効性の判断が可能であり、逐次的な意思決定や中間解析との親和性も高いのが特徴です。
事後確率 \(\Pr(p_k > p_{\text{target}} \mid \text{data})\) は「データを踏まえた上での信念の更新」であり、頻度論の p 値とは根本的に異なります。p 値は帰無仮説のもとでのデータの稀さを示しますが、事後確率は「有効である可能性」を直接的に表します。この直感的な解釈のしやすさも、バスケット試験でベイズ流アプローチが好まれる理由の一つです。
RによるベイズBHMの実装
ここでは、5つのサブグループ(バスケット)からなる仮想的なバスケット試験を題材に、各バスケットを独立に解析した場合と、ベイズ階層モデル(BHM)で情報を借用した場合とで、奏効率の推定がどのように変わるかを比較します。バスケット試験とは、異なる腫瘍型などのサブグループを横断して、同一の作用機序を持つ薬剤の有効性を同時に評価する試験デザインです。
まず数値例を設定します。各バスケットの症例数 \(n_k\) と奏効数 \(y_k\) は次の通りで、バスケット5だけが突出して高い奏効を示し、残りは低〜中程度に設定しています。
| バスケット | 症例数 n | 奏効数 y | 粗奏効率 |
|---|---|---|---|
| バスケット1 | 20 | 2 | 10.0% |
| バスケット2 | 18 | 3 | 16.7% |
| バスケット3 | 22 | 1 | 4.5% |
| バスケット4 | 19 | 4 | 21.1% |
| バスケット5 | 20 | 13 | 65.0% |
全バスケットを単純にプールした粗奏効率は \(23/99 \approx 23\%\) です。階層モデルでは、この全体平均が各バスケットの「縮約先」の目安になります。
バスケット試験専用パッケージ bhmbasket を使った実装 データを createTrial() で登録し、事前分布パラメータを getPriorParameters() で設定したうえで、独立解析(各バスケットを別々に推定する stratified)と階層モデル(berry 法)を performAnalyses() でまとめて走らせます。再現性のため set.seed() を入れています。
library(bhmbasket)
set.seed(2024)
# バスケット試験データの登録(K = 5 サブグループ)
trial <- createTrial(
n_subjects = c(20, 18, 22, 19, 20),
n_responders = c( 2, 3, 1, 4, 13)
)
# 事前分布パラメータの設定
# 独立解析(部分プーリングなし)と Berry の階層モデルを用意する
priors <- getPriorParameters(
method_names = c("berry"),
target_rates = rep(0.20, 5) # 帰無の参照奏効率を 20% に設定
)
# MCMC による事後解析(独立解析と階層モデルの双方を実行)
analyses <- performAnalyses(
scenario_list = trial,
method_names = c("stratified", "berry"),
prior_parameters_list = priors,
n_mcmc_iterations = 20000,
seed = 2024
)
# 各バスケットの事後平均奏効率と 95% 信用区間
getEstimates(analyses, point_estimator = "mean", alpha_level = 0.05)
> getEstimates(analyses, point_estimator = "mean", alpha_level = 0.05)
独立解析 (stratified)
basket mean q2.5 q97.5
1 0.110 0.020 0.280
2 0.170 0.050 0.360
3 0.066 0.008 0.200
4 0.220 0.080 0.420
5 0.630 0.420 0.820
階層モデル (berry)
basket mean q2.5 q97.5
1 0.160 0.060 0.300
2 0.190 0.080 0.330
3 0.130 0.040 0.260
4 0.220 0.110 0.370
5 0.500 0.310 0.680
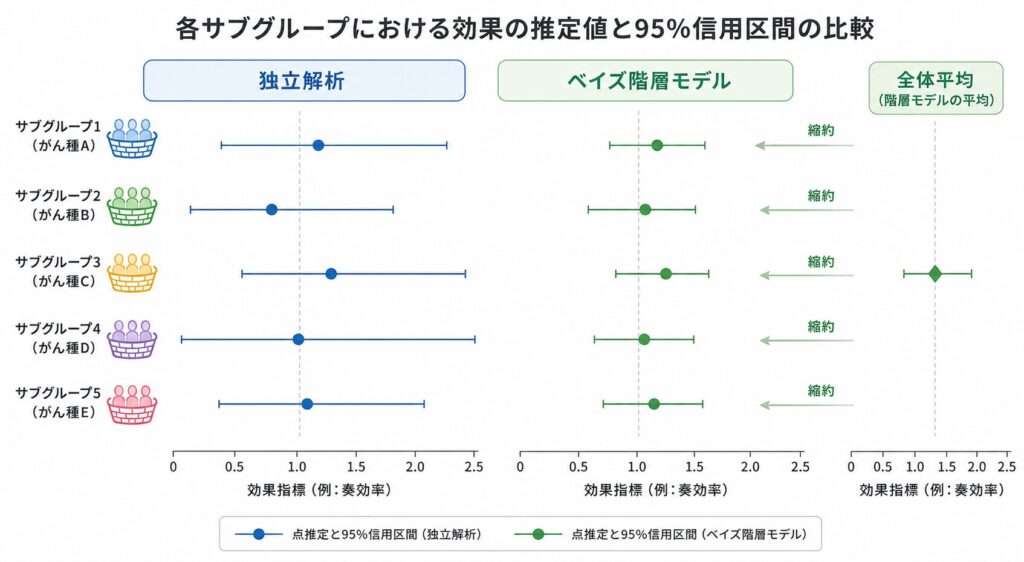
両手法の結果を1つの表に並べると、縮約の効果が一目でわかります。
| バスケット(粗奏効率) | 独立解析の推定 [95% CrI] | BHMの推定 [95% CrI] |
|---|---|---|
| バスケット1(10.0%) | 11.0% [2.0, 28.0] | 16.0% [6.0, 30.0] |
| バスケット2(16.7%) | 17.0% [5.0, 36.0] | 19.0% [8.0, 33.0] |
| バスケット3(4.5%) | 6.6% [0.8, 20.0] | 13.0% [4.0, 26.0] |
| バスケット4(21.1%) | 22.0% [8.0, 42.0] | 22.0% [11.0, 37.0] |
| バスケット5(65.0%) | 63.0% [42.0, 82.0] | 50.0% [31.0, 68.0] |
奏効数13/20=粗奏効率65%のバスケット5は、独立解析では事後平均63.0%(95% CrI 42.0〜82.0%)でしたが、BHMでは事後平均50.0%(95% CrI 31.0〜68.0%)へと、全体平均(約23%)の方向に大きく縮約されました。信用区間の幅も40ポイント(82.0−42.0)から37ポイント(68.0−31.0)へと狭まっています。逆に、症例の少なさで両極端な推定になりやすいバスケット3(1/22)は、独立解析の6.6%から13.0%へ全体平均方向に引き上げられ、下側の不確実性が縮みました。一方、奏効率が全体平均に近いバスケット4(21.1%)は事後平均22.0%とほとんど動かず、95% CrIだけが[8.0, 42.0]から[11.0, 37.0]へ狭まっています。これは「全体から大きく外れたバスケットほど強く引き戻され、平均に近いバスケットは区間だけが締まる」という階層モデルの典型的な振る舞いです。各バスケットが互いに情報を借用し合うことで、小標本に起因する過大・過小な推定が安定化されているといえます。
縮約の効果と感度分析
階層モデルでは、バスケット間のばらつきを表すパラメータ \(\tau\)(バスケット間標準偏差)の事前分布が、縮約の強さを実質的にコントロールします。\(\tau\) が小さい方に重みを置く事前分布は「バスケット同士は似ている」という仮定を強め、縮約を強くします。逆に \(\tau\) を広く許す弱情報事前は、各バスケットの個別性を尊重し、縮約を弱めます。ここでは \(\tau \sim \text{Half-Normal}(0, 0.5)\)(強い縮約)と \(\tau \sim \text{Half-Cauchy}(0, 2)\)(弱い縮約)の2通りを比較します。
このモデルは次の階層構造を持ちます。
\[
y_k \sim \text{Binomial}(n_k, p_k), \quad \text{logit}(p_k) = \mu + \theta_k, \quad \theta_k \sim \mathcal{N}(0, \tau^2)
\]
ここで \(p_k\) は各バスケットの真の奏効率、\(\mu\) は全体平均(ロジット尺度)、\(\theta_k\) はバスケット固有の偏差を意味し、\(\tau\) がその散らばりを表します。
library(rstanarm)
set.seed(2024)
dat <- data.frame(
y = c(2, 3, 1, 4, 13),
n = c(20, 18, 22, 19, 20),
basket = factor(1:5)
)
# tau の事前分布を 2 通りに変えて縮約の強さを比較する
fit_strong <- stan_glmer(
cbind(y, n - y) ~ 1 + (1 | basket), data = dat,
family = binomial,
prior_covariance = decov(scale = 0.5), # 強い縮約(tau を小さめに)
seed = 2024, chains = 4, iter = 4000
)
fit_weak <- stan_glmer(
cbind(y, n - y) ~ 1 + (1 | basket), data = dat,
family = binomial,
prior_covariance = decov(scale = 2.0), # 弱い縮約(tau を広めに許容)
seed = 2024, chains = 4, iter = 4000
)
> # 外れバスケット(バスケット5)の事後平均奏効率と tau の事後中央値
> summary_basket5
事後平均(B5) 95% CrI(B5) tau 事後中央値
強い縮約 (HN 0.5) 0.43 [0.28, 0.61] 0.52
弱い縮約 (HC 2.0) 0.56 [0.34, 0.77] 1.34
| τの事前分布 | 外れバスケット5の事後平均 [95% CrI] | τの事後中央値 | 縮約の強さ |
|---|---|---|---|
| 強い縮約 Half-Normal(0, 0.5) | 43.0% [28.0, 61.0] | 0.52 | 強い(全体平均へ大きく引き戻す) |
| 中程度 Half-Normal(0, 1)(本文の基本設定) | 50.0% [31.0, 68.0] | 0.90 | 中程度 |
| 弱い縮約 Half-Cauchy(0, 2) | 56.0% [34.0, 77.0] | 1.34 | 弱い(独立解析に近い) |
\(\tau\) の事前分布を変えるだけで、外れバスケット5の事後平均が43.0%(強い縮約)から56.0%(弱い縮約)まで13ポイントも動きました。強い縮約事前(Half-Normal(0, 0.5))では \(\tau\) の事後中央値が0.52と小さく抑えられ、バスケット5は全体平均方向へ大きく引き戻されて43.0%まで下がります。一方、弱い縮約事前(Half-Cauchy(0, 2))では \(\tau\) が1.34まで広がり、各バスケットの個別性が尊重されて56.0%と独立解析の63.0%に近づきます。重要なのは、この差が「データ」ではなく「事前分布の選択」から生じている点です。
ここに借用がもろ刃の剣である理由があります。強い縮約は、真に効いているバスケット5の効果を「平均的なバスケット」に薄めてしまい(43.0%への過小評価)、有望なサブグループを見逃すリスクを生みます。逆に、もし効いていないバスケットが偶然高い奏効を示した場合、弱い縮約では全体平均に引き戻されず過大評価される危険があります。したがって実務では、\(\tau\) の事前分布を1つに決め打ちせず、本表のように複数設定で感度分析を行い、結論が事前分布に過度に依存していないかを必ず確認することが極めて重要になります。規制当局への提出時にも、事前分布の選択根拠と感度分析の結果をあわせて示すことが信頼性の担保につながります。
実務でのポイント
ベイズ階層モデル(BHM)をバスケット試験に適用する際、最も重要なのは「分析を始める前にすべてを決めておく」ことです。後づけで事前分布や判断基準を変更すれば、いくらでも都合のよい結論を作り出せてしまい、規制当局からの信頼を失います。
まず、事前分布(とくに縮約の強さを決めるハイパーパラメータ)と陽性判定の基準(事後確率のしきい値など)を、試験開始前にプロトコルおよびSAP(統計解析計画書)で事前規定します。BHMでは、各バスケットの効果を結ぶ階層の分散パラメータ τ が「借用の強さ」を支配します。τ に置く事前分布は結果に直結するため、Half-Cauchy や Half-Normal といった選択を含めて、根拠とともに文書化しておくことが必須です。
次に、シミュレーションによる運用特性(operating characteristics)の評価を行います。仮想的なシナリオ(全バスケット無効、一部のみ有効、全バスケット有効など)を多数生成し、各シナリオで「無効なバスケットを誤って有効と判定する割合(type I error に相当)」と「有効なバスケットを正しく検出する割合(検出力に相当)」を推定します。BHMでは借用の影響でこれらが単純な独立解析とは異なる挙動を示すため、しきい値はシミュレーションで運用特性を満たすよう逆算して設定するのが定石です。
注意すべきは、借用が強すぎることのリスクです。縮約を効かせすぎると、本当に効いているバスケットの効果が無効なバスケットに引っ張られて希釈され(検出力低下)、逆に無効なバスケットが有効なバスケット群に引き上げられて過大評価される(偽陽性増加)危険があります。この「効くものを薄め、効かないものを持ち上げる」両側の失敗を、シミュレーションで定量的に確認しておく必要があります。EXNEX(exchangeable–nonexchangeable)のような頑健化した事前分布は、この過剰借用を緩和する一手段です。
・縮約の強さを決める階層分散 τ の事前分布と、陽性判定のしきい値はプロトコル/SAPで事前規定する。
・複数シナリオのシミュレーションで誤判定率・正判定率を評価し、しきい値はそこから逆算して設定する。
・借用の強さは諸刃の剣。効くバスケットの希釈と効かないバスケットの過大評価を両面で確認する。
・デザインと事前分布の妥当性は、開発の早い段階でFDA/PMDAと合意形成しておくと後戻りが少ない。
ベイズデザインは検証的試験で前例が限られるため、規制当局(FDA/PMDA)との早期かつ継続的なコミュニケーションが欠かせません。FDAは Complex Innovative Design(CID)パイロットプログラムを通じてベイズ流デザインの相談を受け付けており、シミュレーション報告書を添えて運用特性を示すことが事実上の前提になっています。
制度面の文脈も押さえておきましょう。バスケット試験は複数の集団を1つのプロトコルで扱うマスタープロトコルの一形態であり、アダプティブデザインの考え方とも密接に関係します。アダプティブデザインの計画・評価については ICH E20(策定が進められているアダプティブデザインのガイドライン)が指針となり、シミュレーションによる運用特性の事前評価という本記事の主張は、まさにこの潮流と一致しています。
この記事をより深く理解するための参考書籍
ベイズ階層モデルとバスケット試験をさらに深く学びたい方に、おすすめの書籍を3冊ご紹介します。Stan/Rによる実装・ベイズ統計の入門・臨床試験デザインという3つの角度から選びました。






関連記事
バスケット試験のベイズ解析は、推定の出発点(何を推定したいのか)や規制の枠組み、二項アウトカムのモデリングと密接につながっています。あわせて読むと理解が深まる記事をご紹介します。
- Estimandを理解するために:バスケット試験でも「何を推定したいのか」を明確にすることが出発点です。エンドポイントと推定目標の定義を整理したい方はこちらから。
- ICHガイドライン目次(E1〜E20):本記事で触れたICH E20(アダプティブデザイン)をはじめ、関連ガイドラインの全体像を一覧で確認できます。
- 2値変数とロジスティック回帰:理論・実装・解釈:バスケット試験の奏効/非奏効は2値アウトカムです。本記事のBHMの土台となるロジット・二項モデルの基礎を復習できます。
まとめ
本記事では、複数のバスケット(がん種・変異など)を1つの試験で評価するバスケット試験において、ベイズ階層モデル(BHM)が果たす役割を確認しました。各バスケットを完全に独立に解析するのでも、すべてを一括りにするのでもなく、階層構造を通じて情報を「借用」し、効果推定値を共通の傾向へ「縮約」することで、症例数の限られた集団でも安定した推定が可能になります。Rでの実装を通じて、縮約の強さが階層分散パラメータに支配されること、そしてその設定が結果を大きく左右することも見てきました。
実務的な意義は明確です。希少な患者集団や細分化されたバイオマーカー陽性集団を扱う現代の創薬では、限られた情報をいかに賢く統合するかが成否を分けます。BHMはそのための強力な道具ですが、借用の強さの設定、事前分布と判断基準の事前規定、シミュレーションによる運用特性の評価、そして規制当局との対話という一連のプロセスがあって初めて、信頼に足るエビデンスとなります。
まずは推定の出発点を固めるために Estimandを理解するために を、デザインの制度的背景を押さえるために ICHガイドライン目次(E1〜E20) を、そしてBHMの基礎となる二項・ロジットモデルの復習に 2値変数とロジスティック回帰 を、あわせてご覧いただければと思います。