統計検定準1級「分散分析・実験計画法」攻略 ― 一元・二元配置から乱塊法・直交表・交互作用まで ―

この記事でわかること
この記事を読むと、次の5つがわかります。
- 一元配置・二元配置分散分析の出題パターン
- 平方和の分解と分散分析表の作り方
- 交互作用の意味と検定
- 乱塊法・ラテン方格・直交表など実験計画法の基礎
- 準1級でよく問われる典型問題と解法のコツ
はじめに
統計検定準1級において、「分散分析・実験計画法」は毎回のように出題される頻出分野であり、配点も安定して確保しやすい得点源です。平方和の分解や分散分析表の読み取りは、計算手順さえ身につければ確実に解けるため、ここを得意分野にできるかどうかが合否を左右すると言っても過言ではありません。
また、分散分析や実験計画法の考え方は試験のためだけのものではありません。製薬の臨床試験や非臨床実験、品質管理、農事試験など、実務の現場でも「複数の条件で結果に差があるか」「どの要因が効いているか」を効率よく調べるための基本ツールとして広く使われています。考え方を理解しておくと、実務でデータに向き合う際の見通しもぐっと良くなります。
この記事は、統計検定準1級を受験する方はもちろん、統計を学び直したい社会人や大学生の方を対象としています。まずは一元配置分散分析の仕組みをていねいに押さえ、続いて二元配置・交互作用・乱塊法・直交表へと話を広げていきます。それでは、分散分析の基本から見ていきましょう。
分散分析の基本 ― 平方和の分解と一元配置分散分析
分散分析とは何か
分散分析(ANOVA:Analysis of Variance)とは、3つ以上の群(グループ)の母平均に差があるかどうかを、「分散の比」を使って検定する手法です。たとえば「薬剤A・B・Cで効果に差があるか」を調べたいとき、群ごとのばらつき(群間の分散)が群内のばらつき(誤差の分散)に比べて十分に大きければ、母平均に差があると判断します。
ここで「2群ずつt検定を繰り返せばよいのでは?」と思うかもしれません。しかしそれは誤りです。検定を繰り返すと、本当は差がないのに誤って「差あり」としてしまう確率(第一種の過誤)が積み重なってしまいます。これを多重性の問題といい、これを避けるためにすべての群をまとめて一度に検定するのが分散分析です。
一元配置モデル
1つの要因(因子)だけに着目する分散分析を一元配置分散分析と呼びます。観測値を次のようにモデル化します。
\[ y_{ij} = \mu + \alpha_i + \varepsilon_{ij} \]
ここで \(y_{ij}\) は第 \(i\) 水準の \(j\) 番目の観測値、\(\mu\) は全体の平均(総平均)、\(\alpha_i\) は第 \(i\) 水準の効果(その水準が総平均からどれだけずれているか)、\(\varepsilon_{ij}\) は偶然のばらつきを表す誤差です。誤差 \(\varepsilon_{ij}\) は互いに独立で、平均0・分散一定の正規分布に従うと仮定します。
検定したい帰無仮説は次のとおりです。
\[ H_0: \alpha_1 = \alpha_2 = \cdots = \alpha_a = 0 \]
これは「すべての水準の効果が0、すなわちどの水準も母平均に違いがない」という主張です(\(a\) は水準数)。F検定の結果この仮説が棄却されれば、「少なくとも1つの水準は他と異なる」と結論します。
平方和の分解
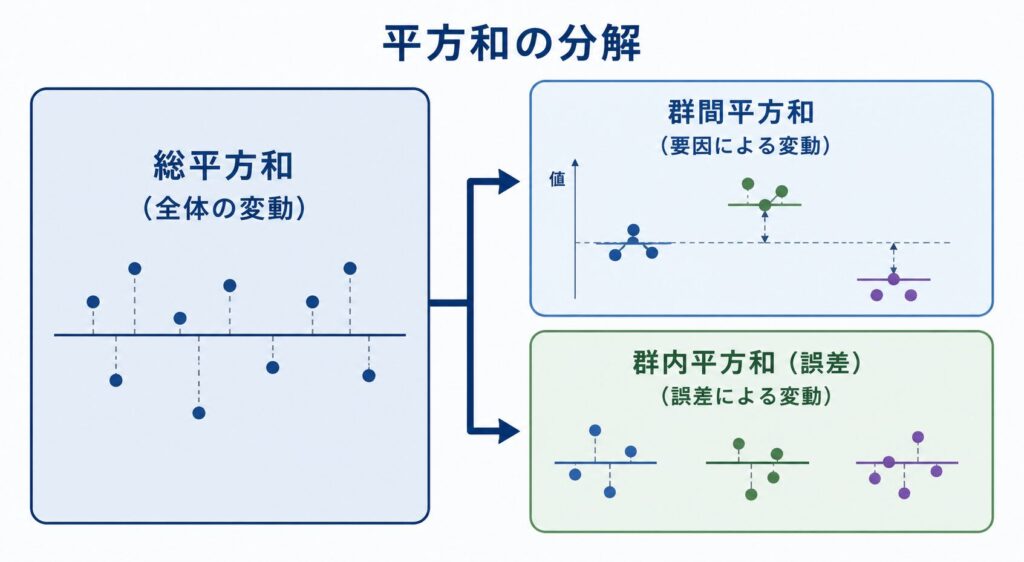
分散分析の核心は、データ全体のばらつきを2つに分解することです。
\[ S_T = S_A + S_E \]
ここで \(S_T\) は総平方和(全データが総平均からどれだけばらついているか)、\(S_A\) は群間平方和(級間平方和とも呼び、各水準の平均が総平均からどれだけ離れているか=要因Aによる変動)、\(S_E\) は群内平方和(誤差平方和とも呼び、各水準の内部に残るばらつき)です。「全体の変動=要因で説明できる変動+説明できない誤差」と分けて考えるのが分散分析の発想です。
自由度・平均平方・F統計量
平方和をそのまま比較するのではなく、それぞれの自由度で割った平均平方(分散の推定量)を求め、その比をとります。
\[ F = \dfrac{S_A/(a-1)}{S_E/(N-a)} \]
ここで \(a\) は水準数、\(N\) は総データ数です。分子は群間の平均平方 \(V_A\)、分母は群内(誤差)の平均平方 \(V_E\) を表します。要因Aの効果が大きいほど分子が大きくなるため、F値が大きいほど群間の差が大きいことを意味します。このF値が、自由度 \((a-1,\ N-a)\) のF分布の上側臨界値を超えれば「有意差あり」と判断します。
以上をまとめると、次のような分散分析表(ANOVA表)になります。
| 要因 | 平方和 | 自由度 | 平均平方 | F値 |
|---|---|---|---|---|
| 群間(A) | \(S_A\) | \(a-1\) | \(V_A = S_A/(a-1)\) | \(F = V_A/V_E\) |
| 群内(誤差E) | \(S_E\) | \(N-a\) | \(V_E = S_E/(N-a)\) | ― |
| 全体(計) | \(S_T\) | \(N-1\) | ― | ― |
この表は準1級でそのまま穴埋め形式で問われることも多いので、各セルの関係(平方和を自由度で割ると平均平方、平均平方の比がF値)を必ず手で再現できるようにしておきましょう。
分散分析でF検定が有意になっても、それは「どこかの群間に差がある」ことを示すだけで、具体的にどの群とどの群の間に差があるのかまでは分かりません。それを調べるのが多重比較です。F検定で有意 → 多重比較でペアを特定、という流れをセットで覚えておきましょう。
二元配置分散分析と交互作用
二元配置分散分析(two-way ANOVA)は、2つの因子A・Bが応答変数に与える影響を同時に検討する手法です。それぞれの因子が単独で持つ効果(主効果)に加えて、2因子の組合せによって生じる相乗的・相殺的な効果(交互作用)を評価できる点が大きな特徴です。
繰り返しのある二元配置のモデルは、次のように表されます。
\[ y_{ijk} = \mu + \alpha_i + \beta_j + (\alpha\beta)_{ij} + \varepsilon_{ijk} \]
ここで \(\mu\) は全体平均、\(\alpha_i\) は因子Aの第 \(i\) 水準の主効果、\(\beta_j\) は因子Bの第 \(j\) 水準の主効果、\((\alpha\beta)_{ij}\) は因子AとBの交互作用、\(\varepsilon_{ijk}\) は誤差項(互いに独立に正規分布 \(N(0,\sigma^2)\) に従うと仮定)を表します。添字 \(k\) は同一水準の組合せ内での繰り返し番号です。
このとき、データの総変動を表す総平方和 \(S_T\) は、各要因の寄与に分解できます。
\[ S_T = S_A + S_B + S_{AB} + S_E \]
\(S_A\) は因子Aによる変動、\(S_B\) は因子Bによる変動、\(S_{AB}\) は交互作用による変動、\(S_E\) は誤差による変動です。この分解により、総変動のうちどの要因がどれだけ寄与しているかを定量的に評価できます。
繰り返しの有無と交互作用
二元配置では、各水準の組合せに繰り返し(複数の観測)があるかどうかが重要です。繰り返しがない場合、交互作用の変動 \(S_{AB}\) と誤差の変動 \(S_E\) を区別できず、両者が混ざった形でしか扱えません。
繰り返しのない二元配置では、交互作用 \(S_{AB}\) と誤差 \(S_E\) を分離できません。そのため交互作用を検定したい場合は、各水準の組合せで2回以上の繰り返し観測を行う必要があります。準1級では「繰り返しがないと交互作用が検出できない」という点が頻出ですので、必ず押さえておきましょう。
繰り返しのある二元配置の分散分析表は、次のようにまとめられます(因子Aの水準数を \(a\)、因子Bの水準数を \(b\)、各組合せの繰り返し数を \(n\) とします)。
| 要因 | 平方和 | 自由度 | 平均平方 | F値 |
|---|---|---|---|---|
| 因子A | \(S_A\) | \(a-1\) | \(V_A = S_A/(a-1)\) | \(V_A/V_E\) |
| 因子B | \(S_B\) | \(b-1\) | \(V_B = S_B/(b-1)\) | \(V_B/V_E\) |
| 交互作用 A×B | \(S_{AB}\) | \((a-1)(b-1)\) | \(V_{AB} = S_{AB}/\{(a-1)(b-1)\}\) | \(V_{AB}/V_E\) |
| 誤差 E | \(S_E\) | \(ab(n-1)\) | \(V_E = S_E/\{ab(n-1)\}\) | ― |
| 計 | \(S_T\) | \(abn-1\) | ― | ― |
各要因のF値が大きく、対応するF分布の棄却域に入れば、その要因の効果が有意であると判断します。
交互作用の読み取り方
交互作用の有無は、交互作用プロット(interaction plot)を用いると直感的に把握できます。横軸に一方の因子の水準、縦軸に応答の平均値をとり、もう一方の因子の水準ごとに折れ線を描きます。折れ線が概ね平行であれば交互作用は小さく、折れ線が交差したり大きく非平行になったりしている場合は交互作用が存在すると考えられます。
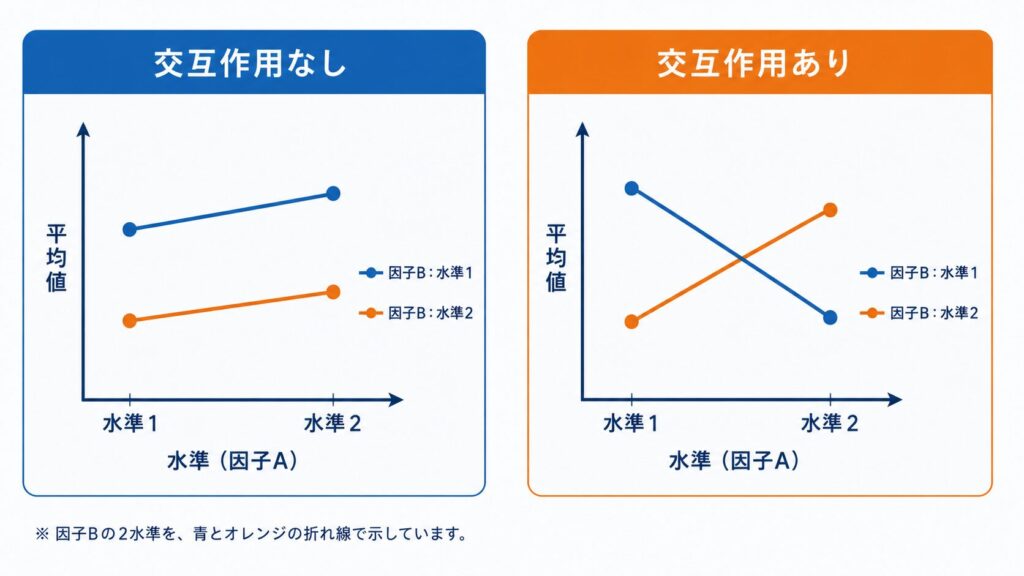
交互作用が有意なときは、主効果単独の解釈は慎重に行う必要があります。たとえば「因子Aの効果」が因子Bの水準によって変わってしまうため、全体平均としての主効果だけを見ても実態を捉えられないことがあります。このような場合は、因子Bの各水準ごとに因子Aの効果を調べる単純主効果(simple main effect)の検討へ進むのが定石です。
多重比較 ― 分散分析の後に行う検定
分散分析で「因子の効果が有意である」と判断できても、それは「少なくともどこかの群間に差がある」ことを示すだけで、具体的に「どの群とどの群の間に差があるのか」までは分かりません。この問いに答えるために行うのが多重比較(multiple comparison)です。
ここで安易にすべての対比較をt検定で繰り返すと問題が生じます。各検定の有意水準を \(\alpha\) としても、独立に \(k\) 回検定を繰り返すと、少なくとも1回は誤って有意と判定してしまう確率は \(1-(1-\alpha)^k\) まで増大します。たとえば \(\alpha=0.05\) で \(k=10\) 回行うと、この確率は約0.40に達します。このように検定全体で見たときの第一種の過誤の確率(FWER, familywise error rate:実験全体での第一種の過誤率)が膨らんでしまうため、これを制御する手法が必要になるのです。
代表的な多重比較法を以下にまとめます。
| 手法 | 用途・特徴 |
|---|---|
| Bonferroni法 | 有意水準を比較回数で割る最も単純な方法。汎用的ですが比較回数が多いと保守的になりすぎます。 |
| Holm法 | p値を小さい順に並べ段階的に基準を緩める、Bonferroni法の改良版。FWERを保ちつつ検出力が高くなります。 |
| TukeyのHSD | すべての2群の組合せ(全対比較)を行う場合の標準的手法。スチューデント化された範囲分布を用います。 |
| Dunnett法 | 対照群(コントロール)と各処理群との比較に特化した手法。比較対象を絞るため検出力が高くなります。 |
| Scheffé法 | 任意の対比(線形結合)に適用できる最も保守的な方法。柔軟ですが検出力は低めです。 |
手法選びで重要なのは「何を比較したいか」です。すべての群どうしを総当たりで比べたいときはTukeyのHSDを、特定の対照群と各処理群だけを比べたいときはDunnett法を用います。比較対象を対照群との比較に限定できるDunnett法のほうが、全対比較を行うTukeyのHSDより検定の数が少なく、その分検出力が高くなります。一方、Bonferroni法やScheffé法は保守的で第一種の過誤を厳しく抑えますが、その代わり差を検出しにくい傾向があります。Bonferroni法の検出力を改善したい場合は、その改良版であるHolm法を選ぶとよいでしょう。準1級では、これらの「用途による使い分け」が問われやすいポイントです。
実験計画法の基礎 ― フィッシャーの3原則と代表的な計画
実験計画法(design of experiments)とは、因子の効果を効率よく・偏りなく評価するためにデータの取り方そのものを設計する方法論です。やみくもにデータを集めるのではなく、誤差を小さくし、限られた実験回数から正しい結論を導くことを目的とします。その出発点が、統計学者R. A. フィッシャーが提唱した次の3原則です。
フィッシャーの3原則
① 反復(replication):同じ処理を複数回繰り返すことで、偶然誤差の大きさを推定でき、処理効果と誤差を区別できます。
② 無作為化(randomization):処理の割り付けをランダムにすることで、未知の系統誤差(偏り)を偶然誤差に変換し、推定を不偏にします。
③ 局所管理(local control):実験の場をブロックに分けて均一化し、ブロック内で条件をそろえることで誤差を小さく抑えます。
この3原則は準1級で頻出です。「反復・無作為化・局所管理」をセットで覚えましょう。
代表的な実験計画
完全無作為化法(completely randomized design) は最も基本的な計画で、すべての処理を実験単位に完全にランダムに割り付けます。3原則のうち反復と無作為化を満たしますが、局所管理は行いません。実験の場が均一なときに適します。
乱塊法(randomized block design) は、性質の近い実験単位をまとめた「ブロック因子」を設けて局所管理を実現します。各ブロックの内部で処理を無作為化することで、ブロック間のばらつき(系統的な変動)を誤差から分離できます。この分だけ誤差分散が小さくなり、処理効果の検出力が高まります。
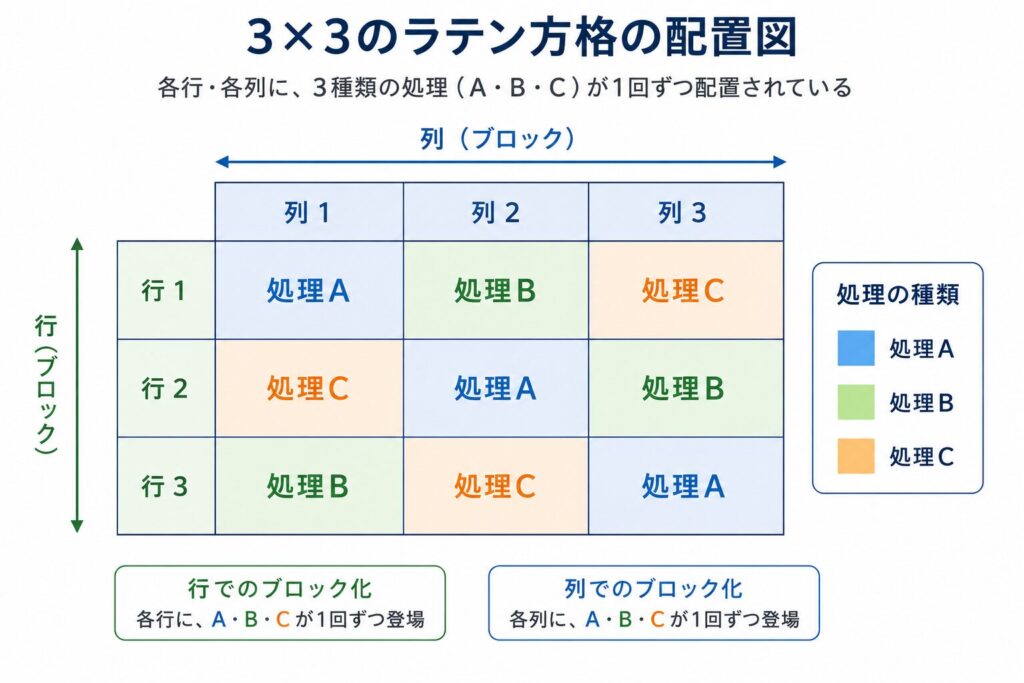
ラテン方格法(Latin square design) は、行と列の2方向でブロック化を行う計画です。\( k \) 個の処理に対して \( k \times k \) のます目を用い、各処理が各行・各列にちょうど1回ずつ現れるように配置します。すべての組み合わせを総当たりすると \( k^3 \) 回の実験が必要ですが、ラテン方格では \( k^2 \) 回で済み、2方向の変動を同時に取り除けるため効率的です。
直交表(orthogonal array) は、L8(2^7) や L9(3^4) などの規格化された割り付け表を使い、多数の因子を少ない実験回数で同時に評価する手法です。各列が互いに直交(バランス)しているため、各因子の主効果を独立に推定できます。これは全組み合わせの一部だけを実施する「一部実施要因計画」にあたり、実験回数を減らす代償として、主効果と交互作用などが見分けられなくなる「交絡」が生じる点には注意が必要です。
| 計画法 | 制御する変動(ブロック化の方向) | 特徴・使いどころ |
|---|---|---|
| 完全無作為化法 | なし(局所管理なし) | 最も基本。実験の場が均一なときに適する |
| 乱塊法 | 1方向(ブロック因子) | ブロック間変動を除き検出力を高める。最も汎用的 |
| ラテン方格法 | 2方向(行・列) | \( k^2 \) 回で2方向の変動を制御。処理数と水準数が等しい場合に有効 |
| 直交表 | 多因子をバランス配置 | 少ない回数で多数の因子を評価。交絡に注意 |
実験計画法の本質は「誤差を小さくし、少ない実験回数で正しく因子効果を評価する」ことにあります。反復・無作為化・局所管理という3原則と、ブロック化によって誤差を制御するという局所管理の発想が、完全無作為化法から乱塊法、ラテン方格法、直交表に至るすべての計画の土台になっています。どの計画を選ぶかは、制御したい変動の方向と、許容できる実験回数のバランスで決まります。
Rで分散分析と実験計画を実装する
ここでは R の組み込みデータセットを使い、分散分析を実際に動かして「分散分析表をどう読むか」を体得します。準1級では計算問題が中心ですが、R で出力を見慣れておくと表の構造が一気に理解しやすくなります。
まずは最も基本的な一元配置分散分析です。アヤメのデータ iris を用いて、3種類のアヤメ(Species)でがく片の長さ Sepal.Length の平均が異なるかを検定します。
# 一元配置分散分析:種によってがく片長の平均が異なるか
result1 <- aov(Sepal.Length ~ Species, data = iris)
summary(result1)
Df Sum Sq Mean Sq F value Pr(>F)
Species 2 63.21 31.606 119.3 <2e-16 ***
Residuals 147 38.96 0.265
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
要因 Species の自由度は \( a-1 = 3-1 = 2 \)、残差(誤差)の自由度は \( N-a = 150-3 = 147 \) です。F値は群間平均平方 31.606 を群内平均平方 0.265 で割った 119.3 で、p値は 2e-16 未満(ほぼ 0)です。したがって有意水準5%で帰無仮説(3種で平均が等しい)は棄却され、種によってがく片長の平均は有意に異なると判断できます。
次に、繰り返しのある二元配置分散分析です。ToothGrowth データで、モルモットの歯の伸び len を、投与方法 supp(OJ=オレンジジュース/VC=ビタミンC)と用量 dose の2要因で分析します。用量は数値ですが水準として扱うため factor() で因子に変換し、交互作用も含めて推定します。
# 二元配置(交互作用あり):投与方法 × 用量
result2 <- aov(len ~ supp * factor(dose), data = ToothGrowth)
summary(result2)
supp * factor(dose) は「supp の主効果」「factor(dose) の主効果」「両者の交互作用 supp:factor(dose)」をまとめて指定する書き方です。
Df Sum Sq Mean Sq F value Pr(>F)
supp 1 205.4 205.4 15.572 0.000231 ***
factor(dose) 2 2426.4 1213.2 92.000 < 2e-16 ***
supp:factor(dose) 2 108.3 54.2 4.107 0.021860 *
Residuals 54 712.1 13.2
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
用量 factor(dose) の主効果が F値 92.0、p値 2e-16 未満と極めて強く、用量が増えるほど歯が伸びることがわかります。投与方法 supp も p値 0.00023 で有意です。さらに交互作用 supp:factor(dose) は F値 4.107、p値 0.0219 で有意水準5%のもとで有意であり、投与方法の効き方が用量によって変わる(例えば低用量では OJ が有利だが高用量では差が縮まる)ことを示します。交互作用が有意なときは、主効果だけを単独で解釈せず、組み合わせごとに効果を見る必要があります。
用量という3水準の要因で有意差が出た場合、「どの用量間に差があるか」を知るには多重比較を行います。Tukey の HSD 法を使うと、全ての水準対の差を一度に比較できます。
# 用量間の全対比較(Tukey HSD)
TukeyHSD(aov(len ~ factor(dose), data = ToothGrowth))
Tukey multiple comparisons of means
95% family-wise confidence level
$`factor(dose)`
diff lwr upr p adj
1-0.5 9.130 5.90222 12.35778 0e+00
2-0.5 15.495 12.26722 18.72278 0e+00
2-1 6.365 3.13722 9.59278 7e-05
0.5・1・2 の3水準について \( {}_3C_2 = 3 \) 通りの全対比較が一度に出力され、いずれも p adj が 0.05 未満で有意です。差(diff)はすべて正で、用量が増えるほど歯が伸びるという用量反応関係が確認できます。多重比較では検定の繰り返しによる第一種の過誤の増大を補正するため、p adj(調整済みp値)で判断する点に注意してください。
準1級でよく問われる典型問題と解法のコツ
分散分析・実験計画法の分野は計算の型が決まっており、出題パターンを知っておくと得点しやすい領域です。代表的な出題パターンを整理します。
| 出題パターン | 問われること・着眼点 |
|---|---|
| 分散分析表の空欄補充 | 平方和・自由度・平均平方・F値の一部が空欄で、相互の関係式から残りを埋めさせる定番問題。 |
| 自由度の計算 | 一元配置は要因 \( a-1 \)・誤差 \( N-a \)、二元配置の交互作用は \( (a-1)(b-1) \) を正しく立てられるか。 |
| F値からの有意性判断 | 算出したF値を、分子・分母の自由度に対応するF分布表の棄却限界値と比較して有意か判定する。 |
| 交互作用の有無の判断 | 交互作用プロットの平行性で読み取る/交互作用を検出するには各水準組合せに繰り返しが必要、という論点。 |
| 実験計画法の選択 | 局所管理(ブロック化)が1方向なら乱塊法、2方向(行・列)ならラテン方格法、と方向数から計画を選ぶ。 |
特に分散分析表の空欄補充は、関係式さえ覚えていれば確実に得点できる頻出問題です。最後に、解くうえでの実務的なコツをまとめます。
① 分散分析表は「平方和 → 自由度 → 平均平方(=平方和 ÷ 自由度)→ F値(=要因の平均平方 ÷ 誤差の平均平方)」という一本の関係でつながっています。どこか1つの欄が分かれば、芋づる式に他の欄を埋められます。
② 自由度は検算に使えます。各要因と誤差の自由度の合計が、全体自由度 \( N-1 \) に一致するかを必ず確認しましょう。一致しなければ計算ミスのサインです。
③ 平方和も同様に、各要因の平方和の合計が全体平方和(総平方和)に一致します。F値は必ず「要因の平均平方」を分子、「誤差の平均平方」を分母に置く点を取り違えないようにしてください。
この記事をより深く理解するための参考書籍
分散分析・実験計画法をさらに深く学び、統計検定準1級の得点力を高めたい方に、おすすめの書籍を3冊ご紹介します。






関連記事・次のステップ
統計検定準1級「攻略」シリーズや、分散分析に関連する記事も合わせてご覧ください。
- 統計検定 準1級・1級 攻略ガイド ― 試験範囲・学習ステップ・よく出るテーマを完全整理 ―:試験全体の範囲と学習の進め方を俯瞰したい方はまずこちらから。
- Rで学ぶ反復測定ANOVA ― afexパッケージで球面性検定からGreenhouse-Geisser補正まで実装する ―:同じ被験者を繰り返し測る「反復測定」の分散分析へ進みたい方へ。
- 統計検定準1級「確率過程」攻略 ― マルコフ連鎖・定常分布・ポアソン過程の典型出題対策:準1級攻略シリーズの確率過程編です。
- 統計検定準1級「多変量解析」攻略 ― PCA・MDS・正準相関の出題対策:多変量解析の出題ポイントを押さえたい方へ。
- 統計検定準1級「ベイズ統計」攻略 ― 事前分布・MCMCの典型出題パターン:ベイズ統計の典型問題に取り組みたい方へ。
まとめ
本記事では、統計検定準1級の頻出分野である「分散分析・実験計画法」を体系的に整理しました。分散分析の核心は、データ全体のばらつきを要因による変動と誤差による変動に分け(平方和の分解)、その平均平方の比であるF値で母平均の差を検定することにあります。一元配置から二元配置へ進むと、主効果に加えて交互作用を評価でき、繰り返しの有無が交互作用検定の可否を決めることも確認しました。F検定で有意だった後は、TukeyのHSDやDunnett法といった多重比較で「どの群間に差があるか」を、第一種の過誤を制御しながら特定します。
実験計画法では、反復・無作為化・局所管理というフィッシャーの3原則を土台に、完全無作為化法・乱塊法・ラテン方格法・直交表が、制御したい変動の方向と許容できる実験回数のバランスで使い分けられることを見てきました。Rの aov() で分散分析表を読み解き、典型出題パターンと「平方和→自由度→平均平方→F値」という一本の関係を押さえておけば、本番でも安定して得点できるはずです。
分散分析・実験計画法は、考え方さえ理解すれば計算の型が決まっている、いわば「努力が報われやすい」分野です。本記事を出発点に手を動かして演習を重ね、準1級合格と、実務でのデータ解析力の双方につなげていただければと思います。